
A Map of Sync
In the words of a recent tweet from Rocicorp’s Aaron Boodman, “[the local-first/sync space] is a big, beautiful, hot mess.” Between the local-first movement, a bounty of new database startups, academic research like CRDTs, and internal app frameworks powering products like Linear, it’s hard to know what’s going on and how everything relates to each other.
A few of us at Convex have worked for over a decade on sync at Dropbox, and we've been working the past few months on extending Convex's sync engine for better offline support and responsiveness. Here are our notes for how we've been keeping things straight.
Categorizing sync platforms
In this document, we’ll present a taxonomy for sync that organizes a few sync platforms across nine different dimensions1 and then walk through the dimensions one at a time.
Data model:
- Size: How large is the data set that a single client can access?
- Update rate: How often do clients send updates?
- Structure: Is the data rich with structure or flat and unstructured?
Systems requirements:
- Input latency: How long can updates be delayed while maintaining a good user experience?
- Offline: How many interactions does the app need to support offline?
- Concurrent clients: How many concurrent clients will look at the same data?
Programming model:
- Centralization: How centralized is the programming model and infrastructure?
- Flexibility: How flexible are sync policies, especially around conflict resolution?
- Consistency: What types of invariants can the application assert about its data model, and how strong can these invariants be?
| Linear | Dropbox | Figma | Replicache | Automerge | Valorant | ||
| Data Model | Size | ~100MB | ~10TB | ~100MB | ~64MB | ~1MB | ~1MB |
| Update Rate | ~0.1Hz | ~0.01Hz | 60Hz | 60Hz | ~2Hz | 60Hz | |
| Structure | High | Low | High | High | Medium | Unknown | |
| Systems | Input Latency | ~1s | ~5s | ~100ms | ~500ms | N/A | ~50ms |
| Offline | Medium | High | Medium | High | High | None | |
| Concurrent Clients | Unlimited | Unlimited | 500 | Unlimited | N/A | 22 | |
| Programming Model | Centralization | Proprietary | Proprietary | Proprietary | Server-authority | Decentralized | Proprietary |
| Flexibility | High | Low | Unknown | High | Medium | Unknown | |
| Consistency | Medium | Medium | Unknown | High | Medium | Unknown | |
We’d love feedback and corrections to this table: DM me on Twitter or shoot me an email.
Data model
In any system, it’s often fruitful to start with nouns over verbs, and in this category, we’ll start by dissecting a sync app’s data model. What data flows through the system, and how does it change?
Dimension 1: Size
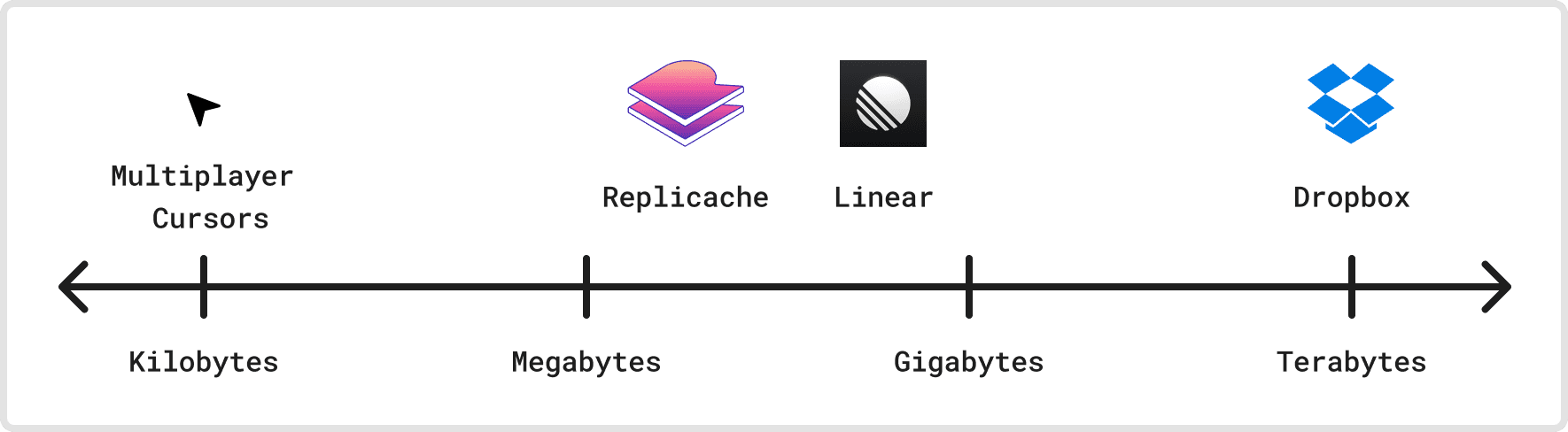
Our first dimension is size: How much data can a client potentially access through the sync protocol? Sync platforms with small amounts of state may store all of it in-memory on the client and server, while larger applications may use slower, cheaper storage, load it lazily, and update it incrementally.
If we look at just the cursors in Figma’s multiplayer view, the cursor state is tiny: just a few bytes per active user. This state is cheap to store everywhere and broadcast whenever it changes. Figma tracks a lot more state than just the cursors, but this perspective would apply to an app that uses, say, Liveblocks for only syncing cursor state.
Linear, on the other hand, can have hundreds of megabytes of issue data (the internal Linear project is 150MB as of last year), and it’s stored in IndexedDB on Web clients, and parts of it are lazily fetched as needed. Replicache, as a similar point on this dimension, recommends keeping total data size under 64 MB.
For an extreme example, a Dropbox user may be able to access many millions of files and terabytes of data from their account. This data is stored on cold storage and often only downloaded when the user opens a file for the first time.
Dimension 2: Update rate
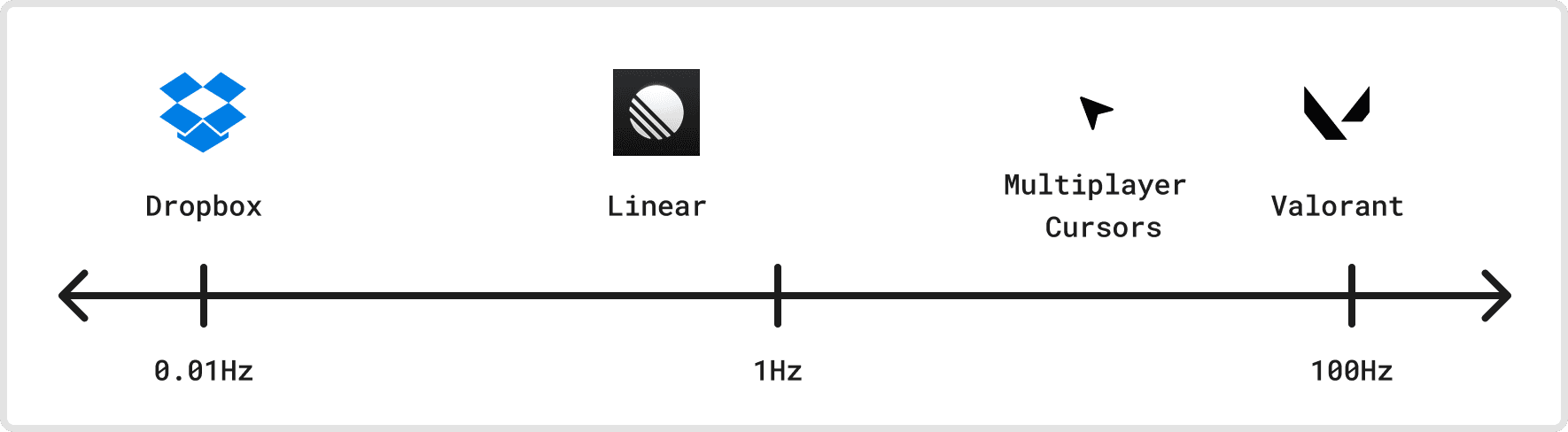
Next, let’s discuss update rate: How frequently do users send changes to the data model? Do we expect updates to stream in continuously at a fixed rate, or are they bursty in time?
Some interaction patterns, like multiplayer cursors on Figma’s document view, send updates at 60Hz to provide a smooth experience.2 These updates are only sent for currently active clients, so documents that don’t have anyone looking at them don’t receive any updates.
They may not feel like sync apps, but multiplayer games like Valorant often have highly sophisticated netcode pushing updates through centralized infrastructure to keep game state in sync across players around the world. Valorant is a fast-paced competitive 5 vs. 5 multiplayer game, and it targets 60Hz for its client updates. So, its sync protocol needs to support 60 updates per second per client continuously flowing through the system during an active game.

Users don’t rearrange issues or create new projects on Linear that often, and most objects in their system are mostly idle. We don’t know their update rate per client publicly, but it’s likely never much more than 1Hz and much lower than that averaged over time.
Systems with high update rate often rely on in-memory data structures, binary serialization formats, and aggressive batching. Low update rate systems are often simpler and store data structures on slower, cheaper media.
Dimension 3: Structure
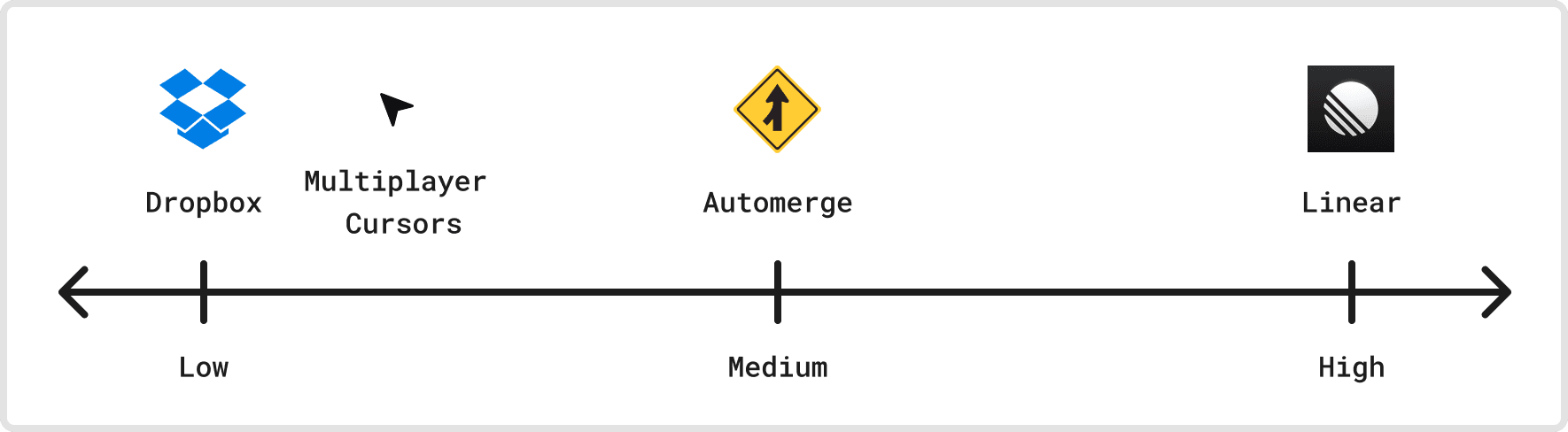
The data that flows through a sync engine can have different levels of structure. How much does the sync platform understand about the data it’s syncing, and are there non-trivial relationships internal to the data?
On one extreme, we have systems like Dropbox that don’t understand anything about the files. To the sync engine, file contents are just uninterpreted streams of bytes and completely unstructured. Systems with smaller data can also have low structure. For example, the state for Figma’s multiplayer cursors has a very simple state description: just a map of a User ID to a cursor position within the document. There’s more structure here than Dropbox’s opaque files, but it isn’t much.
Automerge is a CRDT library borne out of research for syncing JSON without conflicts. Arbitrary JSON is much more structured than the multiplayer cursors flat map of positions, as it can have nested list and map types. Put another way, JSON is a tree of nodes, and trees have the non-trivial invariant of not having cycles. Preventing cycles when clients can move nodes around requires deeply understanding the structure of the trees involved.
At the most structured extreme, we have application data models like Linear. The sync engine understands how issues, workspaces, and teams fit together, and there are important, application-specific relationships between pieces of data within the system. For example, issues maintain pointers to their assignee, labels, project, and milestone, building a rich object graph.
Systems requirements
For our next category, we’ll dig into the systems requirements of different sync platforms. Systems programming is the art of negotiating an application’s ideal experience with the limitations of the real world. Networks aren’t always fast and reliable, computation is sometimes expensive, and storage can be slow and costly. This section explores tradeoffs implied by the real world and how they turn into requirements for the sync protocol.
Dimension 4: Input latency
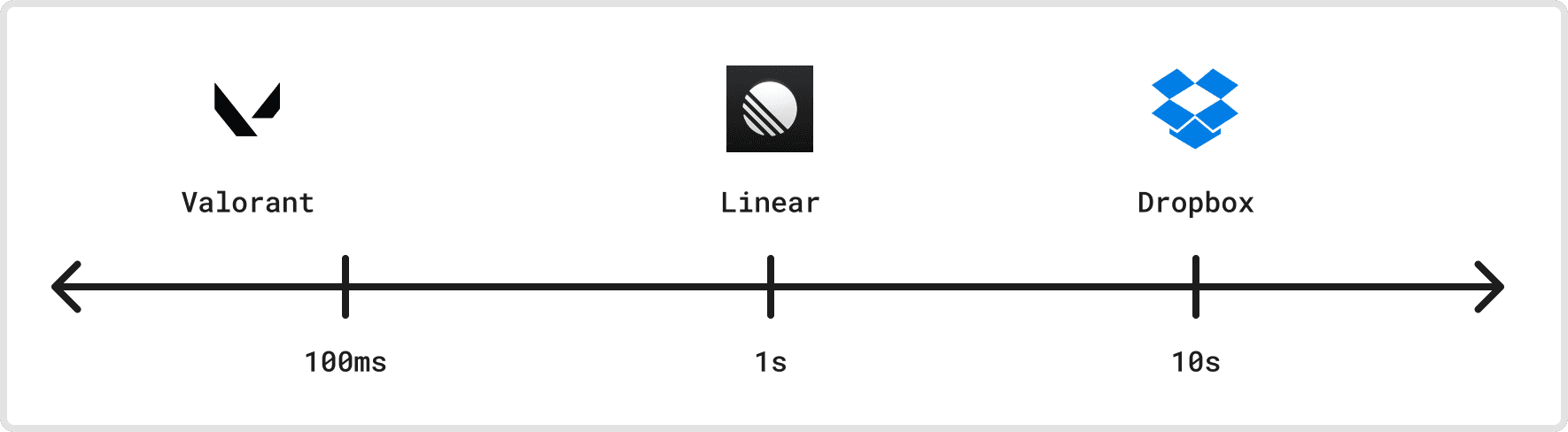
Networks are, sadly, not instantaneous and perfectly reliable. One way network latency prominently shows up in collaborative sync apps is input latency: How long does it take for an input from one user to show up on another user’s device? How much input latency can an application tolerate while still providing a good user experience?
In “Peeking into Valorant’s Netcode,” Riot Games writes how skilled players can reliably detect even 10ms changes in end-to-end input latency, and differences of 20-50ms have large implications on gameplay fairness. So, their application has an extreme sensitivity to input latency that most apps do not, and they’ve solved extreme engineering problems to keep it down.
Linear feels real-time, but it’s actually a lot less sensitive to input latency. Experimentally, I’ve observed sync taking in the high hundreds of milliseconds, and it still feels great.
Even multiplayer cursors are, interestingly, less sensitive to input latency. For cursor movement to feel smooth and human, it should be sampled frequently (Reflect samples at 120Hz, or once every 8ms, on supported devices), but it’s not so important that any individual update propagates at anywhere near 8ms end-to-end. Anecdotally, collaborating on a Figma doc with a second of injected network latency feels totally fine.
Finally, file sharing apps like Dropbox are even more tolerant of latency. Dropbox users typically don’t work on the same file at the same time, and syncing changes to files, even if it takes multiple seconds, is still a lot faster than sending a new version over email or Slack.
Dimension 5: Offline support
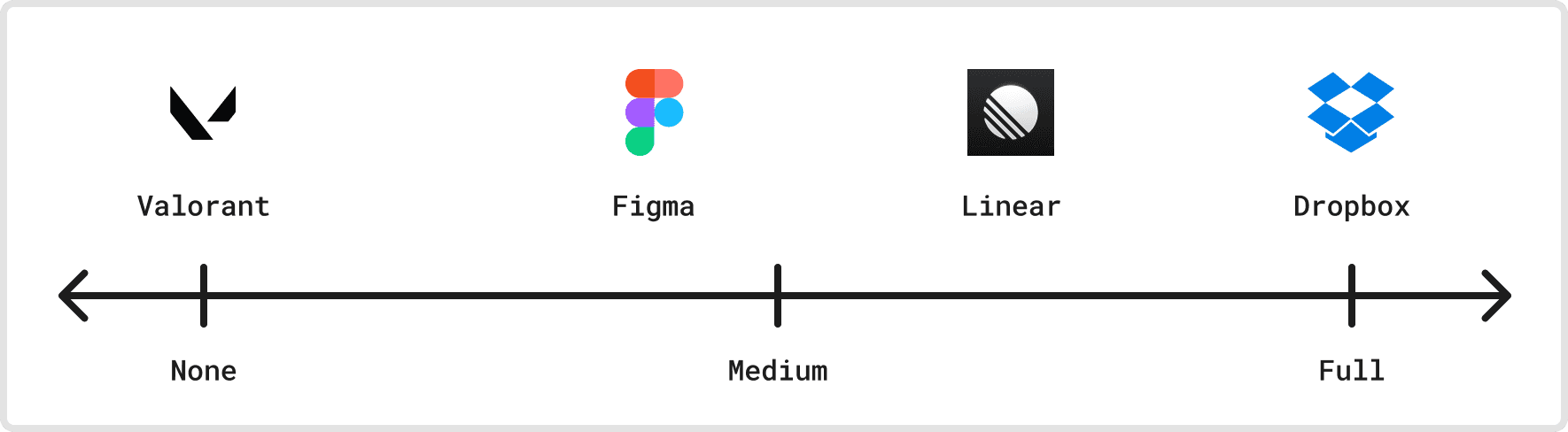
An extreme version of network latency is the client being entirely offline. Does a sync application need to handle sustained offline usage? How long can clients be offline before reconnecting, and are they allowed to make changes while offline?
Valorant explicitly doesn’t support players that go offline. If a user loses network connectivity, they’re kicked off the game (and their teammates are likely sad). This is an explicit product goal, and it can even spill over into kicking out players that have very slow or unreliable networks, as this can degrade the gameplay experience for other players.
On the other extreme, we have apps that maintain all of their functionality when offline. Reads to the local data model never block on the network, and offline writes are persistently buffered while the client is offline and reconciled on reconnection. Obsidian, a local-first note-taking app, doesn’t surface network connectivity at all other than a small spinner in the bottom right. Similarly, Dropbox just puts your files on the local filesystem, so you can always read and write to them whether you’re offline or not.
In the middle we have apps that mostly work while offline. Linear is a great example of this pattern, where offline changes are permitted but show up in the UI with a small disclaimer.
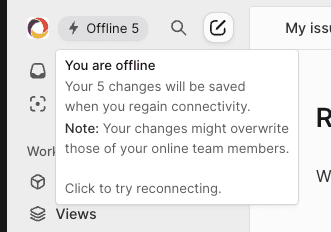
Linear’s Toumas Artman’s talk “Scaling the Linear Sync Engine” from last year discusses how this same idea of “partial offline support” also applies to their data fetching. Linear started by fully bootstrapping all data for a workspace on an initial page load, so the client could subsequently go offline and have full access to their data. As workspaces got larger, this became resource-intensive and a poor user experience, so they moved some data fetches to either become asynchronous or purely on-demand. This is great for performance but degrades some offline functionality, as not all data is available on the local device.
Dimension 6: Number of concurrent clients
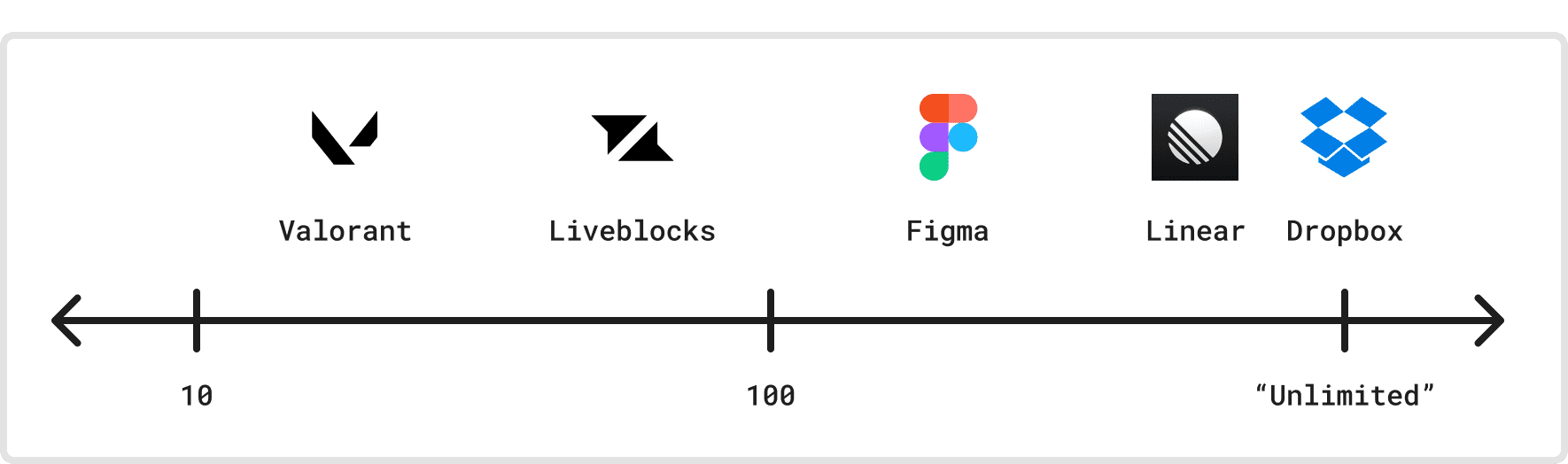
Servers, unfortunately, have finite resources and often can only handle a finite number of active connections. How many concurrent clients does an application need to support? Needing to scale past a single server may have large implications on the protocol’s architecture.
As with offline support, Valorant has a built-in limit in its product for this dimension: There are at most 22 participants per game (10 players plus coaches and observers). Figma has a higher but still static limit for its files: 200 editors, 200 cursors, and up to 500 total participants. Liveblocks permits at most 50 simultaneous connections per room on their Pro plan.
Linear and Dropbox, on the other hand, have distributed architectures that can accommodate a virtually unlimited number of clients. These architectures, however, often require writing changes to durable storage: Linear maintains a record of changes in a separate Postgres table that sync servers can use as an operation log.
Programming model
Our final category for sync apps is their programming model. What types of apps are possible, and what does it feel like to develop an app on a particular sync engine?
Dimension 7: Centralization
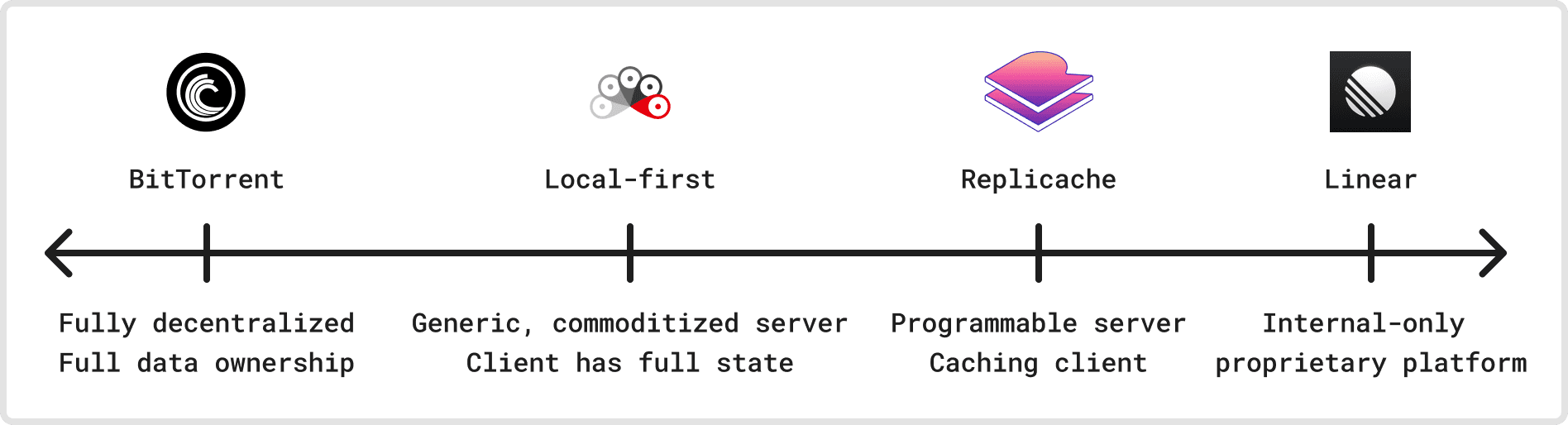
Centralization vs. decentralization is a classic topic in computer science, politics, and just about everything. Does a sync protocol have a single author, or is it authored by a decentralized community? Does it require a centralized server, or can it work entirely peer-to-peer? Is that centralized server highly programmable or commoditized? Is the entire framework controlled and used by a single organization?
On the decentralized side, the local-first manifesto, as embodied by libraries like Automerge, aims for decentralized, open-source development where clients maintain full control over their data. Even if there is a central server, it is entirely commoditized and easy to swap out for another implementation. For file sync, protocols like BitTorrent with distributed trackers avoid centralization entirely.
On the other side, apps like Figma, Asana, and Linear have proprietary sync engines that are only available to their internal product teams. All three rely on centralized infrastructure also operated by the same organization.
In the middle we have frameworks like Replicache (and eventually Zero), where the client’s local store is a local cache of the server’s authoritative data, and state modifications always need to flow through the server, which has the final say on their validity.
Dimension 8: Flexibility
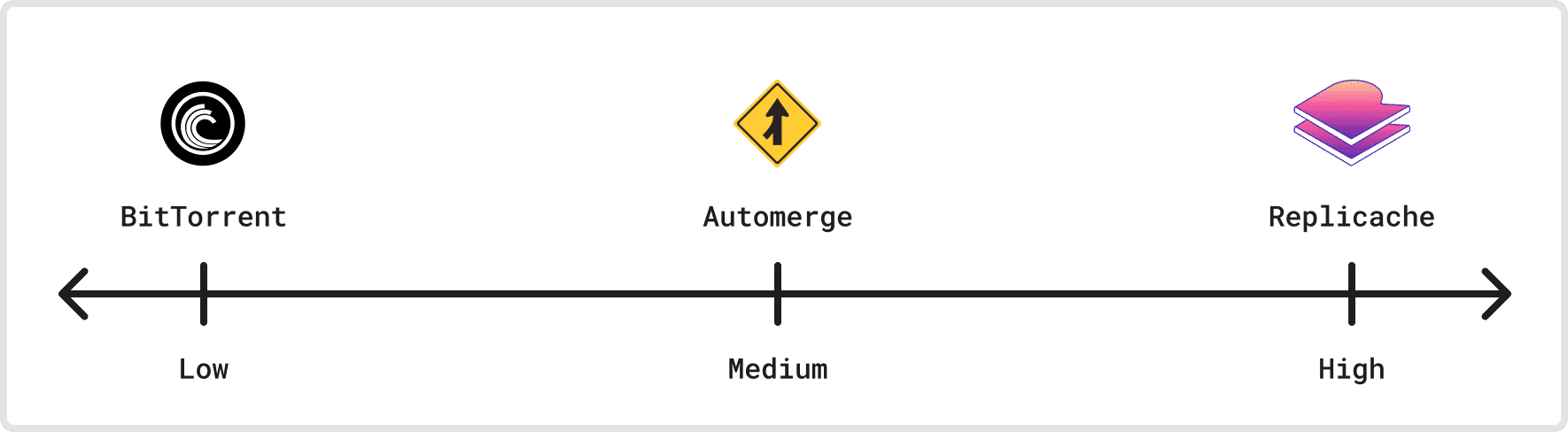
How flexible is a sync protocol to support different use cases? How baked in are assumptions around the data model and product decisions about how it syncs? Is the protocol programmable, where the developer can insert their own code at specific integration points to influence sync decisions?
Bittorrent, for example, comes fully formed and can’t be altered to do much other than sync files across peers. Similarly, Dropbox’s sync protocol is fully bespoke for syncing files and their metadata, and supporting new products requires fundamentally changing the protocol itself.
Programmability often shows up when dealing with conflicts, where multiple clients modify the same data in incompatible ways. There’s often no single algorithm that works for handling concurrent modifications for any non-trivial data structure (what happens if two people edit a document’s title at the same time?), so conflict resolution may need to be handled at the application layer as a product decision, not at the framework layer. Expressing these conflict resolution rules is often best done in code.
CRDTs take an interesting middle road for flexibility. They often try to resolve as many conflicts as possible automatically, embedding many product decisions within the library. Peritext, for example, has some great examples of decisions they’ve made for handling concurrent text formatting changes with edits. These rules are product decisions that are fully baked into the library. However, many CRDT libraries, like Automerge, still retain the possibility for automatic merging to fail, and then the developer can specify their own conflict resolution logic.
Replicache is a great example of a highly programmable sync platform. On the client, developers specify their queries and modifications against the local store in code with “subscriptions” and “local mutators.” The developer can implement the mutators server-side with whatever logic they’d like by implementing the /push endpoint. Similarly, the developer retains deep control for how they’d like to implement their server-side data fetching, adopting one of many “backend strategies.”
Dimension 9: Consistency
A sync protocol’s consistency model provides a promise to application developers: If the application structures its code in a particular way, the protocol will preserve the application’s data invariants. A strong consistency model lets the application developer have strong data invariants, while a weak consistency model requires the developer to handle system states due to data races, offline edits, and so on.
Some applications don’t require very strong consistency. For example, Halo Reach’s netcode explicitly segmented their sync protocol into a reliable protocol for game state and an unreliable protocol for “events,” optional information about state transitions that enriched the game experience. For example, a player’s health would be in reliable game state, while the existence of nearby explosion that hurt them may only show up as an event. Developers working on Halo Reach multiplayer couldn’t assume that both would show up, but the price of anomalies was at worst cosmetic.3
CRDTs generally don’t provide strong consistency guarantees. Automerge, for example, defaults to last writer wins for a single key, which can easily lose data if clients are offline for a long time and perform disconnected edits.4
Furthermore, their JSON CRDT doesn’t provide cross-key consistency: It’s not possible to have a data invariant that spans multiple nodes in their tree. As a developer, I may want to have the data invariant that two arrays are always the same length in my JSON document, but the CRDT will happily merge updates to those separate arrays that get their lengths out of sync.
Finally, Replicache has a well-documented, strong consistency model. Since mutators are specified in code as transactions, the system can guarantee that so long as each transaction preserves the application’s data invariants, the system will never present a view of the data with a broken invariant.
Wrapping up
With these nine dimensions, we can start to tame the wilderness of the current sync ecosystem. Sync engines can differ wildly, but they all make important decisions in their data model, their systems requirements, and their programming model.
In our next post, we'll share how we're thinking of extending Convex's sync engine and where it will land on each of these nine dimensions. Stay tuned!
Footnotes
-
Aaron presented three of his dimensions but left it at that to go eat something 🙂 Our dimensions are similar to his three with some additions and slight shifts. In particular we move "document vs. database sync" into the data model and merge "server-authority vs. decentralization" and "sync engine vs. syncing data store" into "centralization." ↩
-
We'll discuss this later with respect to input latency, but it's possible for the system to record updates at 60Hz but use batching to distribute them at 10Hz. ↩
-
As an even weaker form of consistency, games like Rocket League assume state updates are predictable, since they're largely physics-based. Clients predict other players' inputs and simulate them forwards in time before ever receiving them. Then, if there's ever a misprediction, the client rolls its state back and reapplies the authoritative state. ↩
-
Automerge mitigates this data loss by keeping old versions as conflicts and allowing the developer to handle the conflict. ↩