
How We Horizontally Scaled Function Execution

Convex was designed to change the abstractions of backend engineering. We believe engineers should not need to administer a database and glue cloud services together to run their backend. They should be focused on building their product by writing functions that contain the core business logic of their application. Using Convex, developers write transactional queries and mutations that read and write from tables with their data. They don't have to worry about scale and how they're going to need to rearchitect the system when the database starts falling over. The Convex team has built exabyte-scale storage systems before, and we designed Convex with scale in mind. We started with a single-tenant backend for each customer deployment, and we just took a significant step in distributing the backend: making the function runner horizontally scalable. We've launched a new multi-tenant service called Funrun that runs functions from any Convex deployment.
Background
What are Convex functions?
Convex functions are programs developers write in JavaScript or TypeScript that run in Convex, replacing a traditional backend. Queries and mutations are transactions that commit to the database atomically. Convex’s custom database uses optimistic concurrency control (OCC) for the transaction protocol to achieve atomicity and serializability.
- Queries and mutations begin at a timestamp
ts, with a snapshot of the data at that timestamp. - The function is executed based on the snapshot of the data at
ts. - The writes are checked for conflicts with other transactions that committed since the transaction began at
ts. If there are no conflicts, the writes are committed to the database. Otherwise, the function is retried, starting at step 1 again until a retry limit.
Since queries and mutations are transactional, developers can think of Convex functions as code that runs inside the database. To learn more about the overall architecture, check out How Convex Works.
How does Convex run functions?
Running code “inside” a database requires extremely low-latency. Before launching Funrun, each Convex deployment ran functions in its own process using V8, a JavaScript runtime. Back in 2020 when the founders were building the first version of Convex, they chose to use V8 to run developer code instead of popular serverless function providers like AWS Lambda. Using V8 avoids high cold-start latency and the overhead of containerization in serverless functions and makes it possible to have low latency database IO. V8 can spin up an isolate that runs developer code in 10ms compared with 500ms-10s latency to spin up an AWS Lambda. Cloudflare has written a great article going into these details here.
However, while AWS Lambdas are built to scale, V8 is not. V8 has a limit of 128 threads, so a single Convex backend could only run 128 functions at a time. Eventually customers could run into this hard limit in our monolithic architecture or need to scale beyond a single machine, so we split the function runner out into a separate service called Funrun. Any backend can send requests to Funrun, and we can scale up the number of Funrun instances as needed to match demand.
What is Funrun?
In a nutshell, Funrun is a read-only gRPC service that reads from the database to get a snapshot of the data, computes the results of developer-defined functions, and sends the results back to the backend where the writes are checked for conflicts and committed atomically.
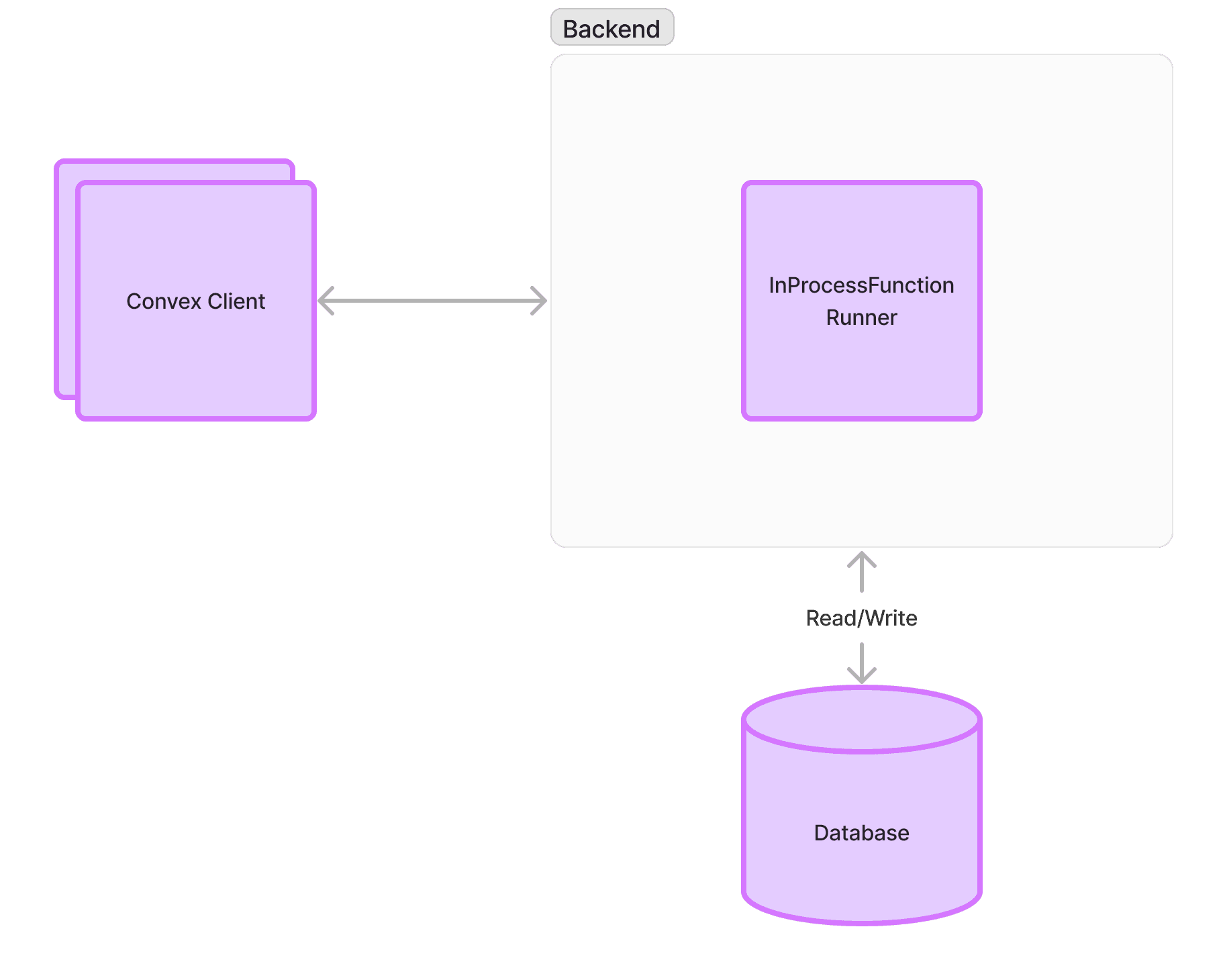
Old Architecture
New Architecture
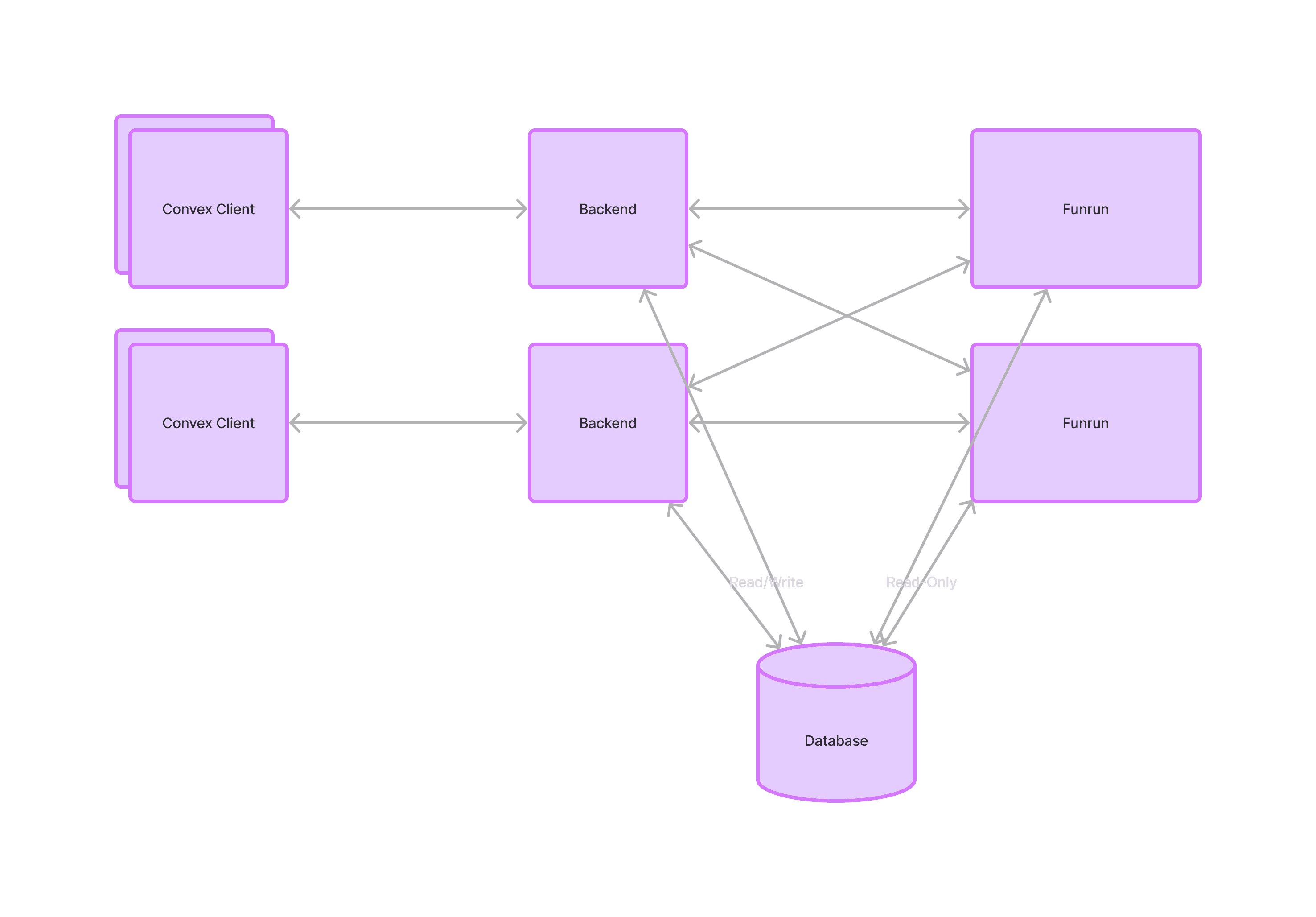
In both architectures, each customer deployment corresponds to a single backend process. Convex clients in the developers’ app talk to the backend over websockets and HTTP. In the old architecture, functions ran inside the backend, in V8 isolates managed by the InProcessFunctionRunner. In the new architecture, backends send requests to any Funrun instance. Then Funrun runs functions and sends the results back to the backend, where the committer checks for conflicts and writes to the database.
How does it work?
When we first pulled out the function runner into a separate service, it took seconds to do simple queries and mutations because we had to load a snapshot of the database state on every request to have accurate data for functions to read from.

Believe it or not, now Funrun actually has about the same performance as running functions directly in the backend. Network latency is minimal because backend instances and Funrun instances are located in the same region. The greatest cost is database roundtrips for information that was previously stored in memory after loading the database when the backend starts up. We minimized database roundtrips by caching modules and the in-memory indexes and routing requests to the same Funrun instances to maximize cache hits.
System Metadata Caching
To run a function, we need the source code and configuration for each Convex deployment. We call the metadata for getting the source code the "modules", and the configuration exists in system tables we keep in memory because we need them on every request.
Here are some examples of system tables we use on every request:
- Tables table: We need to know what tables exist so we know what we can read from and write to.
- Indexes table: We need to know what indexes are available for queries.
- Schemas table: We check that every write is compatible with your schema.
- Backend state: No functions can run when your deployment is disabled.
The module cache and in-memory index cache both use a sophisticated asynchronous LRU cache. In the past, we've seen thundering-herd issues with the module cache. One request takes a long time, and then subsequent requests and retries all fetching the same module add to the load. The asynchronous LRU we developed asynchronously loads values for a particular key at most once, returning the result to all callers who are waiting for that key.
Request routing
The system metadata caches are only useful for reducing latency if backends consistently send requests to the same Funrun instances so there are few cache misses. We have a client at our service discovery layer that establishes connections to upstream Funrun instances and sends at most 32 requests at one time to any particular Funrun. It uses the Rendezvous hashing algorithm to consistently send requests from a client to the same node until the limit.
Isolate reuse
Another source of latency is V8 isolate creation. For security, isolate contexts are not reused between requests, and isolates are only reused when requests come from the same backend. The isolate scheduler keeps track of which backends used an isolate and picks the most recently used isolate that has been used by the backend before. Otherwise it creates a new one.
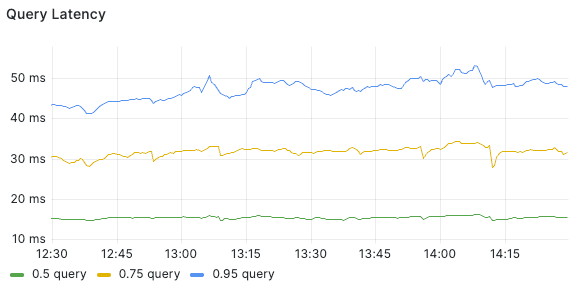
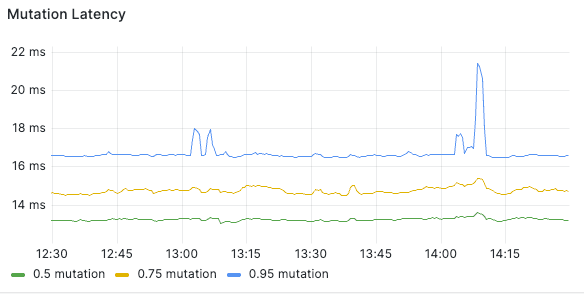
Performance
With these improvements, Funrun query and mutation performance using Funrun is about the same as when functions are executed in backend, with the median less than 20ms.
Impact
We rolled out Funrun to users in early March 2024, enabling pro customers to run 10 times as many functions concurrently. Now that Funrun is its own multi-tenant service, we can easily scale horizontally by increasing the number of Funrun instances as our customers’ applications scale. We managed to distribute the system without sacrificing performance.
Convex is the backend platform with everything you need to build your full-stack AI project. Cloud functions, a database, file storage, scheduling, workflow, vector search, and realtime updates fit together seamlessly.