
Introducing Fullstack-Bench
Autonomous “vibe coding” is here: AI agents are starting to take vague requirements and independently write, deploy, and debug code with little human oversight. While tools like Cursor, Bolt, and v0 are great for small, specialized, or human-assisted tasks, the next frontier is letting AI handle entire features autonomously in large codebases. As the creators of a popular backend platform, it’s critical that Convex is a great target for AI coding. So, we’ve spent the past few months studying when autonomous AI coding agents succeed and when they fail.
Today’s autonomous agents, like Cursor Composer, Devin, and Aider, aren’t very consistent yet. Cursor Composer sometimes cranks out incredible features on its own in minutes, but other times it gets stuck in frustrating debugging loops where fixing one bug introduces three elsewhere. To understand why this happens, we’ve built Fullstack-Bench, a curated set of tasks for autonomous fullstack engineering that starts from a frontend app and evaluates how well an agent can implement the backend across multiple frameworks.
From these experiments, we’ve identified three ingredients for successful autonomous coding: tight, automatic feedback loops; expressing everything in standard, procedural code; and strong, foolproof abstractions. When these conditions hold, today’s coding agents can fully autonomously implement ambitious features across multiple systems. When they don’t, they often get stuck in costly loops that require human expert intervention.
Here's an example of this working, where Cursor Composer autonomously writes code for eight minutes:
In this post, we’ll walk through our experimental design, our initial results on a selection of backends (FastAPI+Redis, Supabase, and Convex), and our observations on what makes autonomous coding work.
Fullstack-Bench
Our main goal with Fullstack-Bench is to test the limits of today’s coding agents on autonomous fullstack engineering. Fullstack engineering is uniquely difficult since it requires writing code for multiple frameworks, debugging issues across the frontend and backend, and reasoning about concurrency and state management at scale.
When designing the experiment, we noticed that coding agents are already excellent at building frontend-only apps with tools like v0. So, our tasks give the agent the full frontend implementation as a starting condition, only asking them to implement the backend. This keeps the experiment focused and makes the results easier to grade, since the UI will be mostly the same.
Then, our framework supports adapting each task’s starting condition to multiple different backends. By varying the backend, we can explore how well the agent performs on systems with different tradeoffs. For example, the Python-based FastAPI+Redis backend is widely adopted and standard, while the Supabase and Convex backends are newer and have less representation before models’ knowledge cutoff.
Finally, after the agent finishes its task, we grade its response according to a task-specific rubric. We also count the number of interventions the human operator needed to make to report an error or provide a hint to get the agent unstuck. Our goal was to make grading as natural as possible, so the rubric items are high level feature tests.
Let’s dive into these three main parts in more detail.
Tasks
Each task includes a frontend-only Next.js web app and a prompt to make it fullstack by adding a backend. We currently have three apps of increasing difficulty:
| App | Deadline | Description | Frontend LOC |
|---|---|---|---|
| Chat | 30m | A simple chat app with channels, messages, and no authorization. | 503 |
| Todo | 30m | A todo app that has projects, tasks, and comments. Tasks have multiple states and due dates. Every user can view every piece of state. | 1491 |
| Files | 1h | A files app with a single workspace, multiple projects within the workspace, and a filesystem tree under each project. The workspace has admins, users can be parts of groups, and groups may nest within each other. Users or groups can be members of projects and have access to the project’s files. | 3321 |
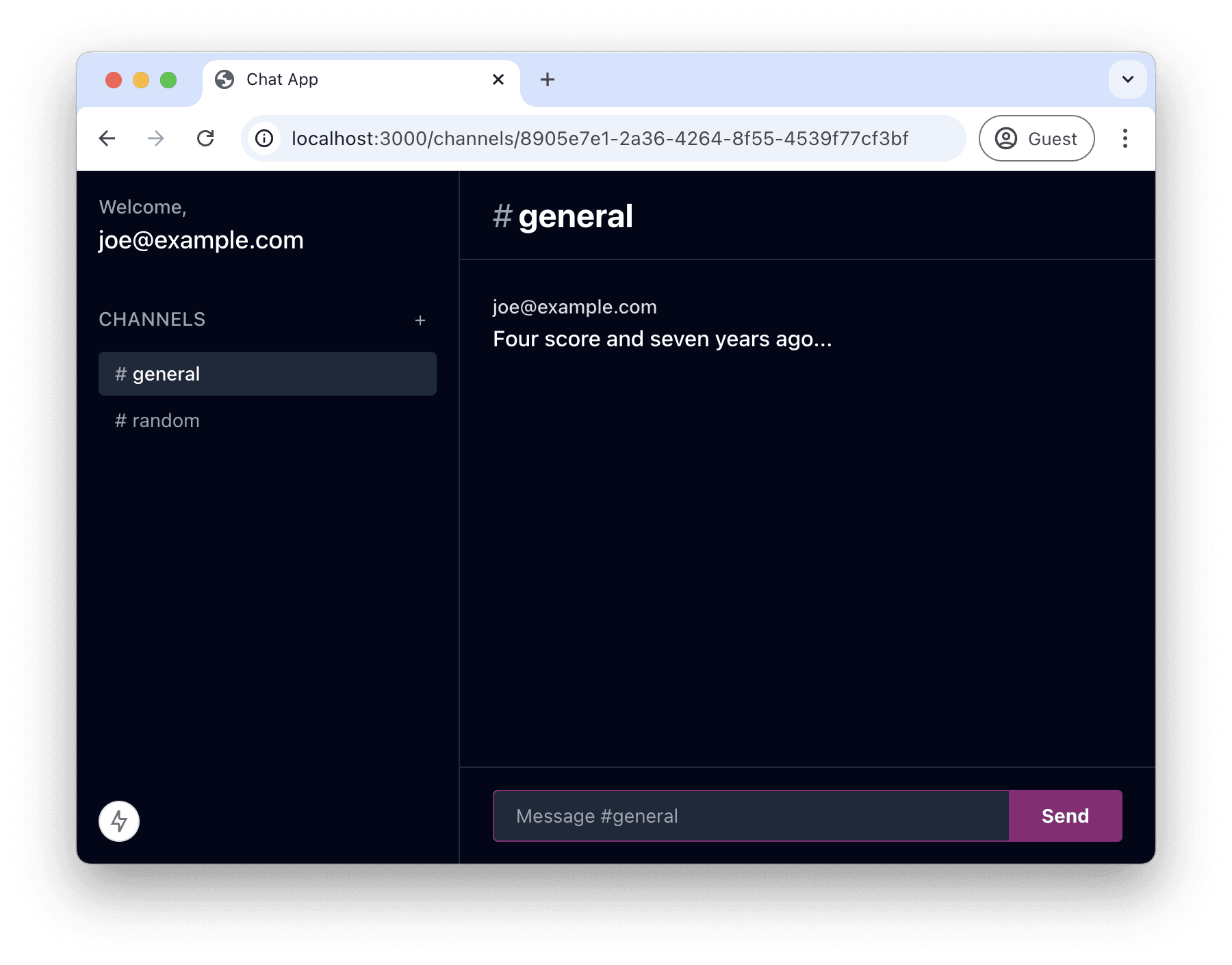
Each app includes sample data as a starting point, simulating a developer using v0 for filling out the frontend and using example data before figuring out state management and the backend. Here’s the initial condition for the chat app task:
Backends
Fullstack-Bench supports implementing each task with one of three different backends:
- Supabase: Supabase is a fullstack platform centered around Postgres. Idiomatic Supabase has clients directly connect to the database with PostgREST. Supabase has built-in authentication and encourages developers to use Postgres Row Level Security for restricting what clients can do to the database. Supabase supports transactions with Database Functions written in SQL or PL/pgSQL and realtime with their Realtime API.
- FastAPI: FastAPI is a web server for Python with standard patterns for authentication. We setup FastAPI with Redis, an in-memory store with stored procedures in Lua and built-in Pub/Sub. This framework represents the classic three-tier app architecture and provides the agent the most flexibility for setting up its API, storage, and subscriptions.
- Convex: Convex is a fullstack platform where developers write their API and data fetching layers in TypeScript. Everything, from configuration, to API endpoints, to queries is pure code. Read API endpoints automatically live-update and are cached, and write API endpoints are executed as atomic transactions. The framework generates TypeScript bindings for the client for end-to-end type-safety from the client to the database.
Each backend’s template has authentication and a basic user table set up already, and we include instructions on how to use each template in a backend-specific prompt. Both Convex and Supabase provide Project Rules for Cursor, so we include those within their templates too1.
Grading
Once we've chosen a task and a backend, we're ready to run an experiment. We stitch together the task’s frontend app with the backend’s template and assemble the starting prompt for the agent. We startup the backend’s servers, feed the prompt into Cursor Composer in agent mode (with all YOLO mode options turned on2), start a timer, and let it rip.
We let the agent continue and count the number of human interventions needed, terminating the experiment when the model has stopped making progress or hits a deadline. We categorize interventions as follows:
Error reported: The model decided it was done, and the human tried out the app, hit an error, and then copy pasted the error and a screenshot into the agent chat.
Hint: The model got stuck and the human gave it a suggestion or a bug fix that was more than just an error report.
Agent: Cursor Composer sometimes forgets to run type checking, pauses before finishing its task, or hits a tool call limit. We tell the agent to continue and don’t count it as an intervention.
After the task completes, we grade the final output according to the task’s rubric, checking each piece of the app’s functionality.3 We wanted these rubrics to be as natural as possible, so they just check app functionality without introspecting any of the different backends’ implementations. For example, the chat app's rubric checks whether a solution supports creating a new channel, listing a newly created channel without a page refresh, posting a message in a channel, and so on.
Results
We ran the experiment across each choice of three tasks and three different backends and graded the results:
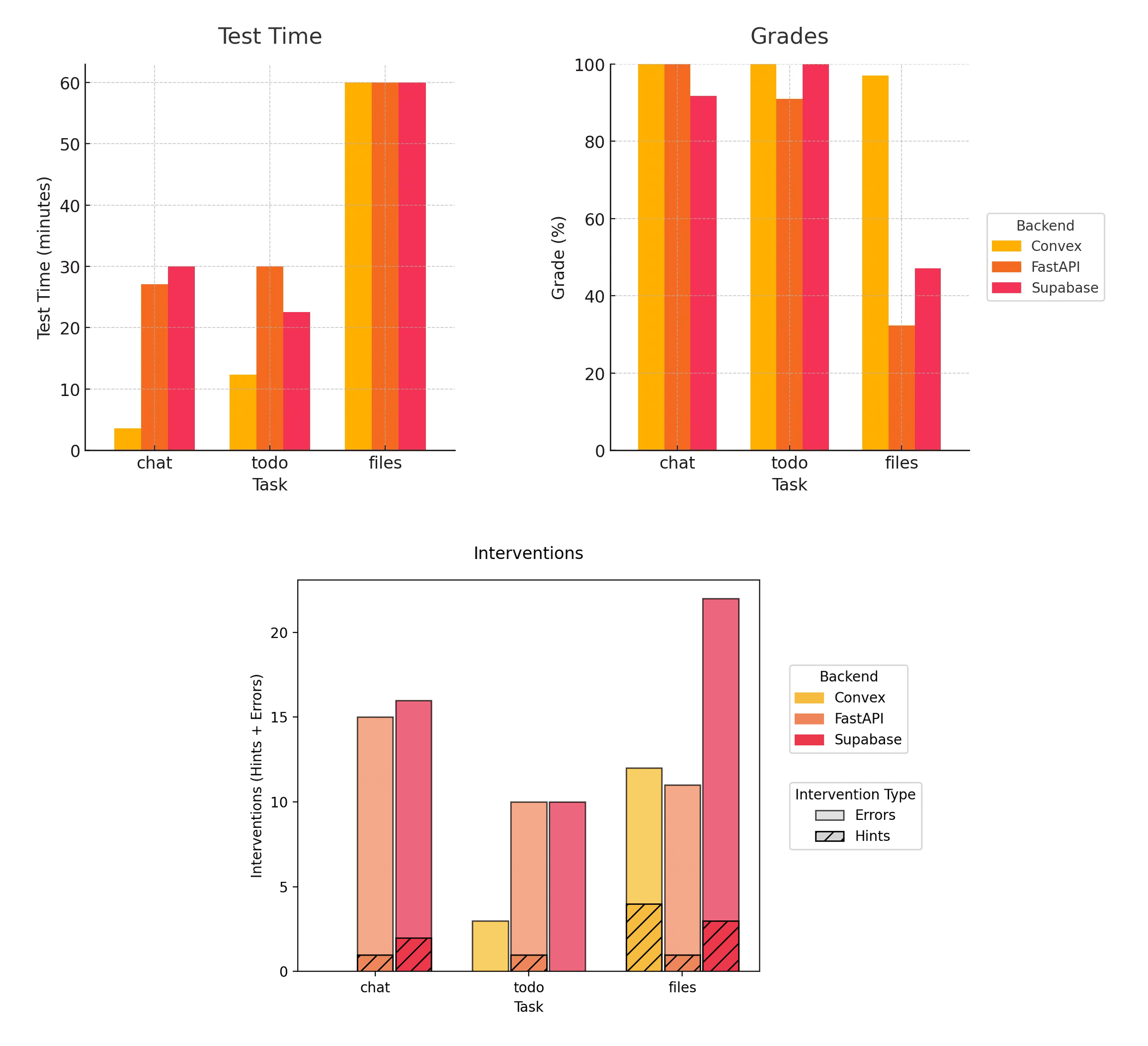
| Task | Errors reported | Hints given | Test time | Final LOC | Grade |
|---|---|---|---|---|---|
| chat / Convex | 0 | 0 | 3:34 | 789 | 12/12 |
| chat / FastAPI | 14 | 1 | 27:05 | 967 | 12/12 |
| chat / Supabase | 14 | 2 | 30:00 | 855 | 11/12 |
| todo / Convex | 3 | 0 | 12:20 | 2003 | 22/22 |
| todo / FastAPI | 9 | 1 | 30:00 | 2357 | 20/22 |
| todo / Supabase | 10 | 0 | 22:30 | 2195 | 22/22 |
| files / Convex | 8 | 4 | 60:00 | 4240 | 33/34 |
| files / FastAPI | 10 | 1 | 60:00 | 4612 | 11/34 |
| files / Supabase | 19 | 3 | 60:00 | 4358 | 16/34 |
Detail on hints given (with timestamps):
chat / FastAPI:
- 8:33: Suggested directly using
useEffectfor state management.
chat / Supabase:
- 7:49: Suggested changing the schema rather than continuing to change the client.
- 20:06: Gave a hint to look at how the hook is getting called in the sidebar.
todo / FastAPI:
- 28:12: Fixed an SSE response parsing bug it was getting stuck on.
files / Convex:
- 12:36: Suggested using
anyto fix cyclic types in TypeScript. - 22:50: Fixed
v.unionsyntax and a TypeScript narrowing issue. - 48:22: Explained
nullvs.undefinedfor Convex validators. - 51:31: Pointed out logic bug in access check.
files / FastAPI:
- 21:55: Cursor Composer got into loops editing two different api.ts files. Stopped the agent, manually merged the files, and told it to resume.
files / Supabase:
- 47:16: Suggested disabling RLS rules to make progress.
- 58:41: Pointed out that the UI state is inconsistent with the DB.
- 63:55: Suggested disabling RLS again to make progress.
- With hints and manual error reporting, the agent was able to solve most of the first two tasks on all backends within the time limit.
- For the chat and todo tasks, the agent effectively oneshotted the task on Convex with no hints and few errors reported. The agent also solved these tasks over twice as fast on Convex. We attribute this speed to getting it right on the first try vs. needing a slow iteration loop with a human intervention.
- The files task, at around 4000 lines of code, is hard enough to cause the agent to hit the time limit on all backends. At this point, the solutions got partial credit for the features they had completed at the end of the test.
Using these results and the video footage from the experiments, let’s revisit our three ingredients of autonomous coding: tight, autonomic feedback loops; expressing everything in standard, procedural code; and strong abstractions that are hard to use incorrectly.
Provide tight, automatic feedback loops.
Cursor Composer integrates directly with language servers to give feedback to its agent. Over our experiments, we observed the agent autonomously code for 10+ minutes when it was able to get good feedback from the type system.
The loop of writing code, getting immediate feedback from the type system, and then fixing the type errors also enabled the agent to correct its own hallucinations. For example, Claude hallucinated that it’s necessary to include the _creationTime field when inserting a document into Convex. This caused a type error, which the agent then autonomously fixed.
As an example in the opposite direction, our FastAPI stack doesn’t have type safety for its schema. When working on the TODO app task, the agent got confused and mixed set and sorted set operations on the same key in Redis. It didn’t find the bug until a round of manual testing, slowing the whole process down.
Type safety, in particular, is an excellent guardrail for coding agents. It’s fast and keeps the coding agent on the straight and narrow path and prevents it from wandering off or getting into loops.
We also observed that type safety provides a great termination condition. With all backends, the agent often thought it was done before it actually implemented all of the task’s features. We especially noticed this behavior on the files task, where we hypothesize that the size of the codebase makes it hard for Cursor's context management to fit all the relevant source code into the model's context. Type checking is a cheap way to look at every file in the codebase, and it’s highly effective at pointing the agent to the right part of the codebase to work on next.
Express as much as possible in standard, procedural code.
The AI coding agent regularly got stuck on constructs that weren’t directly visible in code. With Supabase, most of the interventions and hints were related to RLS rules and debugging their execution semantics. The agent often couldn’t figure out how to prevent rule evaluation from getting into cycles, despite Postgres’s Row Security Policies being an open standard that predates model knowledge cutoff.
The agent also got stuck on setting up foreign key relationships in SQL, another part of the system that lives outside the normal, procedural TypeScript codebase.
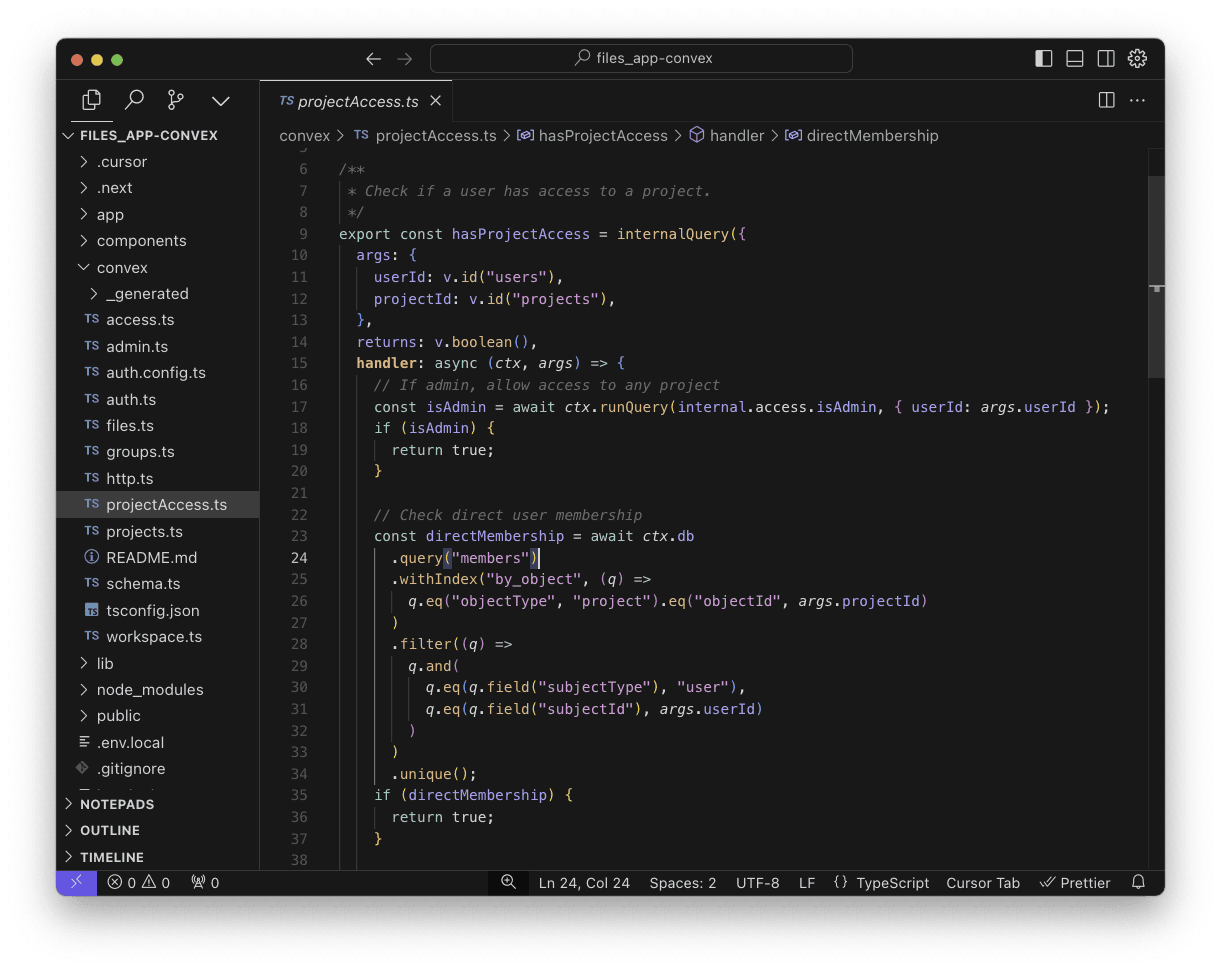
On the other hand, the model was able to oneshot authorization rules in Convex, since they're just regular TypeScript functions called by server endpoints. Here’s an example from the Files app for checking whether a user has access to a given project:
We also observed the agent getting stuck on "nonstandard" API design decisions that don't match its expectations. For example, Convex has a subtle distinction between null and undefined in its documents, where null is a value explicitly set, and undefined can either be a missing field in an object or an explicit undefined value set in JavaScript. The agent got confused with this distinction and required a hint to get unstuck:
Coding agents are uniquely great at writing and reasoning about code, especially when the code uses APIs that match expectations. Put another way, writing regular procedural code against a novel but natural API (like most of Convex) outperforms a declarative language that’s well-represented in the pre-training dataset (like Postgres’s RLS rules).
Design strong abstractions.
Working with distributed state is a classically hard problem, from managing client-local stores to transporting it over a network to representing it on a server. It’s not worth solving hard problems from scratch every time, and platforms like Convex that solve them once and package them up into strong abstractions expand what models are capable of.
When working with FastAPI and Supabase, bugs related to state management often required manual error reporting. For example, the files app on Supabase contained a bug where creating a project caused it to render twice in the UI, since the agent’s initial attempt incorrectly merged results from local optimistic updates and the view from Supabase Realtime:
On the networking side, the agent consistently struggled with Server Side Events (SSE) when using the FastAPI stack. Our FastAPI template sets up the eventsource-client NPM package in the initial condition and an example streaming endpoint on the server. But since the FastAPI setup is so flexible, the agent would often introduce bugs and get confused. When working on the chat app, the agent mistakenly diagnosed a streaming error and introduced another bug by double encoding the event payload.
Whenever possible, don’t force coding agents to solve hard problems. Use libraries or frameworks that provide good abstractions and prevent the agent from wandering off the path when debugging issues. Since Convex handles state management and WebSocket communication internally, the agent didn’t need to think about a large class of problems and could stay focused on implementing the task’s business logic.
Conclusion
We’re excited about this work for two reasons.
First, Fullstack-Bench is hopefully a generally useful benchmark for testing agents’ abilities to write full apps. Over time, we’ll add support for more backends, more tasks, and make grading more autonomous. We’re also interested in making grading a lot harder to stress models’ capabilities: correctness under highly concurrent load with tools like Jepsen and Antithesis and performance with open loop load testing.
Second, we'll be tweaking Convex's design over time to make it an even better target for AI coding agents. We're pleased to see that API decisions that are good for humans are often good for AI coding agents too, and we'll be adding more feedback loops to the Convex development experience for all coders.
These experiments are designed to be fully open and reproducible, and we welcome contributions on the GitHub repo for new backends, tasks, or graders.
Thanks to David Alonso, Michael Cann, Martin Casado, James Cowling, Simón Posada Fishman, Derrick Harris, Ian Macartney, Sarah Shader, and Jamie Turner for feedback on an early draft of this post.
Footnotes
-
FastAPI doesn't provide its own Project Rules, so we used this entry from Awesome CursorRules. ↩
-
We let Cursor Composer write to files, run commands, and delete files without approval.
 ↩
↩ -
This process is currently very manual to run, but we’d like to eventually automate error reporting and grading with tools like browser-use. Detecting that the agent isn’t making progress and providing a hint is also very manual, but we'd like to explore automating this with a stronger reasoning agent that has private access to a solution. ↩