
Background Job Management
What do you do when the work you want to perform should happen after a request?
How can you see incremental progress on workflows that may take a while? Or cancel a job scheduled for the future?
In this post, we’ll look at a pattern for managing asynchronous work that allows you to:
-
Start a long-running job and respond quickly to a client.
-
Track incremental progress on multi-stage tasks.
-
Subscribe to the status and result of a background task from multiple clients.
-
Cancel a request transactionally (i.e., without race conditions).
-
Monitor job timeouts.
-
Implement custom retry logic in the case of transient failures.
As an example of this pattern, I’ll be referencing a multiplayer game using Dall-E. While building it, I found that OpenAI’s image endpoint could sometimes take over 30 seconds, timing out and giving a bad user experience. Rather than have the client wait on a single request, I schedule the work to be run asynchronously using Convex’s function scheduling. You can see the code here.
Tracking status in a table
The high-level approach uses a table to keep track of a long-running task’s state. For my example, I made a “submissions” table to track generating an image using OpenAI based on a prompt:
1// in convex/schema.ts
2submissions: defineTable({
3 prompt: v.string(),
4 authorId: v.id("users"),
5 result: v.union(
6 v.object({
7 status: v.literal("generating"),
8 details: v.string(),
9 }),
10 v.object({
11 status: v.literal("failed"),
12 reason: v.string(),
13 elapsedMs: v.number(),
14 }),
15 v.object({
16 status: v.literal("saved"),
17 imageStorageId: v.string(),
18 elapsedMs: v.number(),
19 })
20 ),
21 }),
22Depending on the status of the work, we capture different information.
1. Starting a job without waiting for it
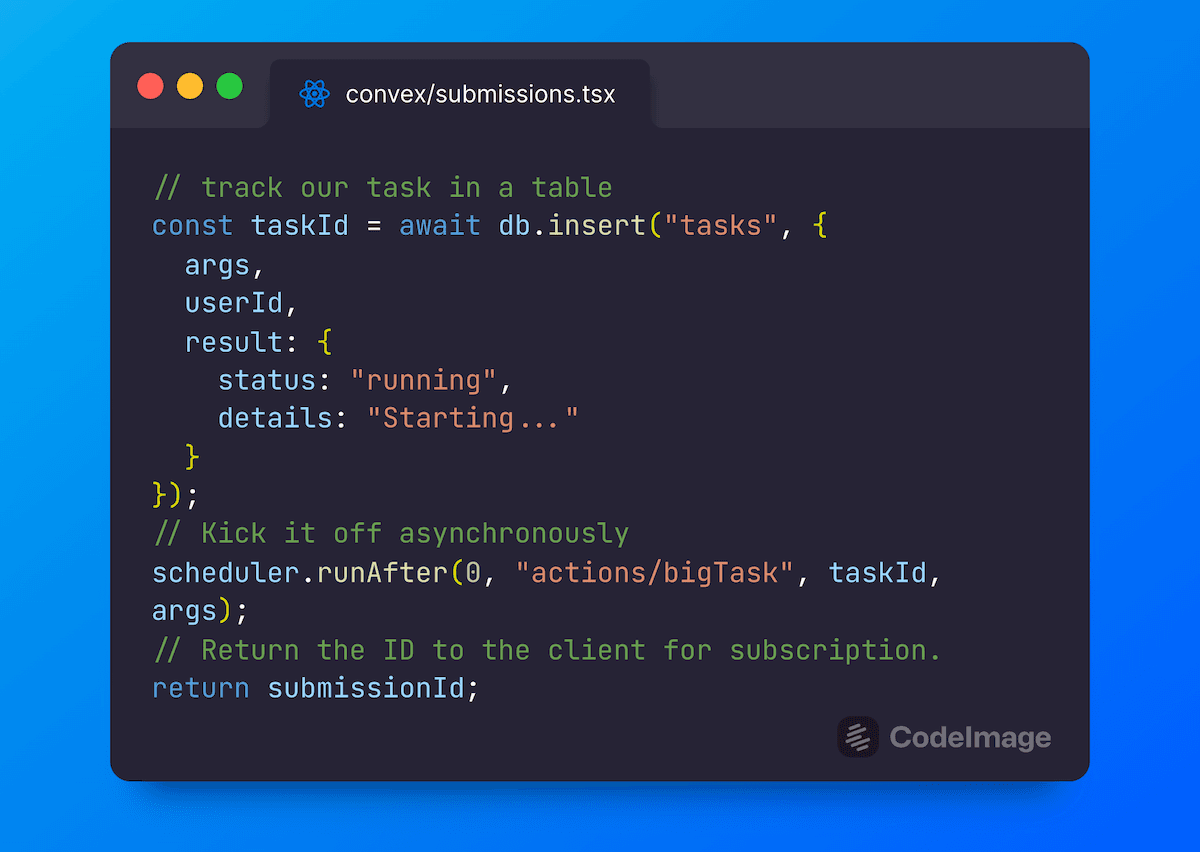
To start the process, the client calls a mutation, which creates the submission document, schedules the work to start immediately, and returns the ID:
1// in convex/submissions.tx "start" mutation
2const submissionId = await db.insert("submissions", {
3 prompt,
4 authorId: session.userId,
5 result: {
6 status: "generating",
7 details: "Starting...",
8 },
9});
10// Kick off createImage in the background
11// so we don't block this request.
12scheduler.runAfter(0, internal.actions.createImage, { prompt, submissionId });
13return submissionId;
14Mutations are transactional, so we could have also checked if there was an ongoing submission for the user or a duplicate request. Importantly, we pass the submission ID to the client and the action that will update the submission.
2. Tracking incremental progress
Once the client receives the submission ID, it can update its UI reactively based on the submission status:
1const Submission = ({ submissionId }) => {
2 const result = useSessionQuery(api.submissions.get, { submissionId: props.submissionId });
3 switch (result?.status) {
4 case "generating":
5 return (
6 <figure>
7 <article aria-busy="true"></article>
8 {result.details}
9 </figure>
10 );
11 case "failed":
12 return <p>{result.reason}</p>;
13 case "saved":
14 return (
15 <figure>
16 <img src={result.url} />
17 Generated in {result.elapsedMs / 1000} seconds.
18 </figure>
19 );
20 }
21 return null;
22};
23As a reminder, Convex queries are re-run automatically whenever the underlying data changes. So as the submission is altered, this React component will re-render with the latest results.
On the server, it can update the status from the action by running the submissions:update mutation:
1// in actions/createImage.ts
2runMutation(internal.submissions.update, {
3 submissionId,
4 result: {
5 status: "generating",
6 details: "Generating image...",
7 }
8});
9Which can be as simple as:
1// in convex/submissions.ts
2export const update = internalMutation(async (ctx, {submissionId, result}) => {
3 await ctx.db.patch(submissionId, { result });
4});
5When the request is done, it’s up to you whether you write to the job table with the results or commit them elsewhere. In my case, I let the user decide whether they like the image before submitting it to the game, so the action is only responsible for generating it.
3. Subscribing from multiple clients
One nice side-effect of storing the data in a table and reactively querying it is that you can subscribe to the result from multiple clients. Anyone with the submissionId can wait for results. On a higher level, you can also see real-time statistics about the health of the jobs. Because Dall-E can be so slow, I decided to surface its status in the UI, to manage user expectations.
Here I query the latest five submissions and calculate their average time and average success rate:
1// in submissions.ts
2export const health = query(async (ctx) => {
3 const latestSubmissions = await ctx.db
4 .query("submissions")
5 .order("desc")
6 .filter((q) => q.neq(q.field("result.status"), "generating"))
7 .take(5);
8 let totalTime = 0;
9 let successes = 0;
10 for (const submission of latestSubmissions) {
11 totalTime += submission.result.elapsedMs;
12 if (submission.result.status === "saved") successes += 1;
13 }
14 const n = latestSubmissions.length;
15 return [totalTime / n, successes / n];
16});
174. Cancelling a request safely
When you schedule a job, it returns an ID of type Id<"_scheduled_functions">, which can be used to query the status and cancel it through the scheduler's ctx.scheduler.cancel function.
You can alternatively do this in your own table: you can check if it’s already started and, if it hasn't, update its status to “canceled” in the table otherwise. When the job runs, it can query the table and either return early or mark the task as “started.” With either approach, because mutations are transactional with serializable isolation, you are guaranteed that either the mutation to cancel the job will see that it has already “started” or the job will see “canceled” - you’ll never think that you canceled a task but find out it ran anyways.
For example, say you want to make a last-minute change to which email a user will get. It is important to send only one email. You can cancel the current pending email, and if you succeeded in canceling it, send an updated one instead.
5. Monitoring timeouts
To mark a job as timed out, you can schedule a follow-up mutation when you’re scheduling the job.
1// in submissions.ts "start" mutation:
2scheduler.runAfter(30, internal.submissions.timeout, { submissionId });
3The timeout could do something like:
1export const timeout = internalMutation(async (ctx., { submissionId }) => {
2 const submission = await ctx.db.get(submissionId);
3 if (submission.result.status === "generating") {
4 await ctx.db.patch(submissionId, {
5 result: { status: "failed", reason: "Timed out", elapsedMs: 30000 },
6 });
7 }
8});
9Depending on your application, you might want your background job to not save results if it ends up finishing anyways, so it could check that the status isn’t already “failed" and commit in the same mutation - similar to canceling a request above.
6. Implementing retries
Convex functions give you different guarantees around failure and retries. To summarize, Convex automatically retries your queries and mutations, but cannot automatically retry actions since they may contain side effects that may not be safe.
Sometimes, however, it does make sense to retry an action. Such as fetching resources from an external service that has transient failures.
See this article about implementing retries.
Whenever implementing retries, ensure you incorporate backoff and jitter to ensure you don’t exacerbate issues for the service you’re hitting.
Summary
In this post, we looked at some patterns for using a table to track scheduled functions to achieve a number of common behaviors for background tasks. As always, let us know what you think in our Discord!
Convex is the reactive backend platform that keeps up with you and your agents. Database, functions, workflow, sync, search, file storage, and more. All TypeScript, zero glue.