
Authorization In Practice

Managing authorization for your app doesn’t have to be a headache or be an anxiety point for code reviewers. With some conventions and abstractions, you can navigate the vast majority of use-cases.
For those not familiar with the difference, we’ll be talking about Authorization, not Authentication.
- Authentication: who the user is. e.g. passkey, “Login with Google,” etc. Shorthand:
authn - Authorization: what they can do. Admins, permissions, etc. Shorthand:
authz
There is no one perfect answer to authorization. However, there are a few great approaches that can be used and combined to fit different app needs. We’ll walk through the landscape, moving from user interfaces to database access, and show practical examples.
Working definition
For the purposes of this article, let’s define authorization as defining controls based on the authenticated entity.
Controls
Note I don’t say “per-document permissions” or “table access” explicitly. In many cases, the control may be a combination of accessing or modifying documents from multiple tables, with some fields stripped out or modified. Applications often want to reason about data at a layer of abstraction higher than individual documents. For instance, one user might be able to see other users’ names but not their email, or see the number of people online but not see who those people are.
Controls also imply non-data capabilities, like sending requests to third parties, consuming LLM tokens, or loading and running code on a local GPU.
Entities
While authorization often refers to human “users,” there are many other entities that may take action, such as a background service running in a trusted environment, a remote server acting on behalf of a company or user, or even an AI Agent acting autonomously. You’ll often hear these referred to as “service accounts.”
Note: In asynchronous environments, you will often not have one clear “user” or entity you’re acting on behalf of within a single database transaction, and instead need to understand which operations refer to which entities. In Convex, asynchronous functions don’t currently return any auth data from the function context. Instead, you explicitly pass parameters around about the associated user(s).
Layers of authorization
As apps mature, they generally introduce multiple overlapping strategies, to avoid inevitable mistakes. For instance, authorizing requests when they come in based on user intent, then again in a library abstraction or micro-service, and a final (usually crude) row-level check. Modifications might be logged automatically and scanned for policy violations. When you’re getting started, I recommend co-locating authorization with user intent as much as possible, and adding additional layers as you go.
Authorizing on the client (insecure but friendly)
In clients, you can try to prevent a user from going to a URL or requesting some resource they shouldn’t have access to. This is nice for user experience, not a security strategy.
- The quality of feedback you can provide to a user degrades the further you go from the user’s action. Showing feedback right by a button is great. Showing a specific toast is nice. Showing a generalized “Oops, something went wrong” banner is less good. Of course all of these are superior to the page crashing, an error getting swallowed in the backend, or a confusing “no rows returned” experience.
- Users ideally never see these errors. For example, when a user is logging out or losing some permission (e.g. leaving a chat) you should redirect them to somewhere else where they do have permissions. If they can’t click the button, disable it. They can technically try to load the old resources and get errors (because you are authorizing on the server, right? Right?), but that should require them mis-using your app. I designed the Rate Limiter component to have an associated React hook that automatically updates when there’s enough capacity for a request (the actual validation happens on the server).
- Important: you should not assume that hiding UI or any logic around code-driven navigation will prevent users from accessing the raw underlying endpoints and APIs. In general assume that the client might be running code you didn’t write.
See below for an example of conditionally rendering UI.
Authorizing in middleware (broad, centralized)
Middleware is a common place to insert authentication and authorization for traditional servers. It is usually responsible for transforming HTTP headers into a “user” or “actor” or “viewer” or “account” etc., then propagating that through. When serving web pages, this can authorize what server-rendered pages a user can retrieve. For data access and API endpoints, it can have nested layers of rules.
The benefit of centralizing these checks is to add default protections - you don’t have to remember to add auth checks to every new endpoint.
Let’s trace the flow of a request from a user through various code touch-points before modifying data:
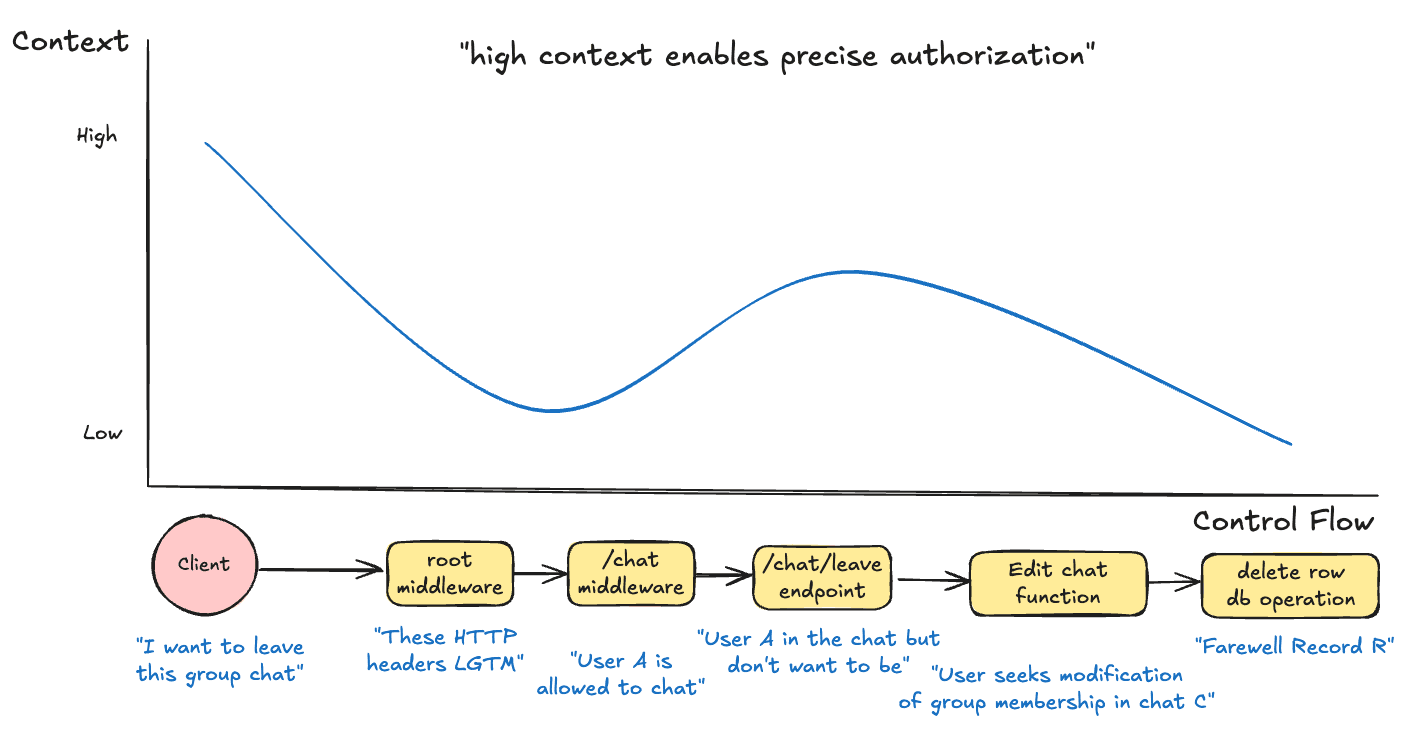 As requests traverse from clients through middleware to the endpoint, functions and the database, their intent is most clear in the client and endpoint
As requests traverse from clients through middleware to the endpoint, functions and the database, their intent is most clear in the client and endpoint
Note that while there’s a lot of context on user intent in the client, once you’re in a trusted environment, there’s an odd curve: as you go from catch-all middleware towards a specific endpoint, your context actually increases, and then as you go further towards shared utility functions and raw database operations, you lose context on the original intent.
Low context makes it hard to be precise about capabilities. For instance, a user should be able to modify their own chat membership status to leave a chat, but not change their membership to promote themselves to an admin or join a private chat.
Note:
- The more nesting you introduce, the harder it is to track down where the authentication is happening, and what authorization has already been performed. Assuming that upstream1 middleware already checked certain permissions can be dangerous. And modifying those nested rules can be hard to audit what downstream routes they will affect.
- Be aware of middleware ordering - if you depend on certain upstream checks, refactors may break your app. For a look at best-in-class middleware, check out TanStack Start’s Middleware, as a good mix of composability, type safety, and transparency.
- I have more thoughts on middleware here.
See below for an example of basic authentication and team membership checks.
Authorizing the endpoint (strong intent signal)
When implementing an authorization strategy, your code generally moves from less trusted to more trusted environments.
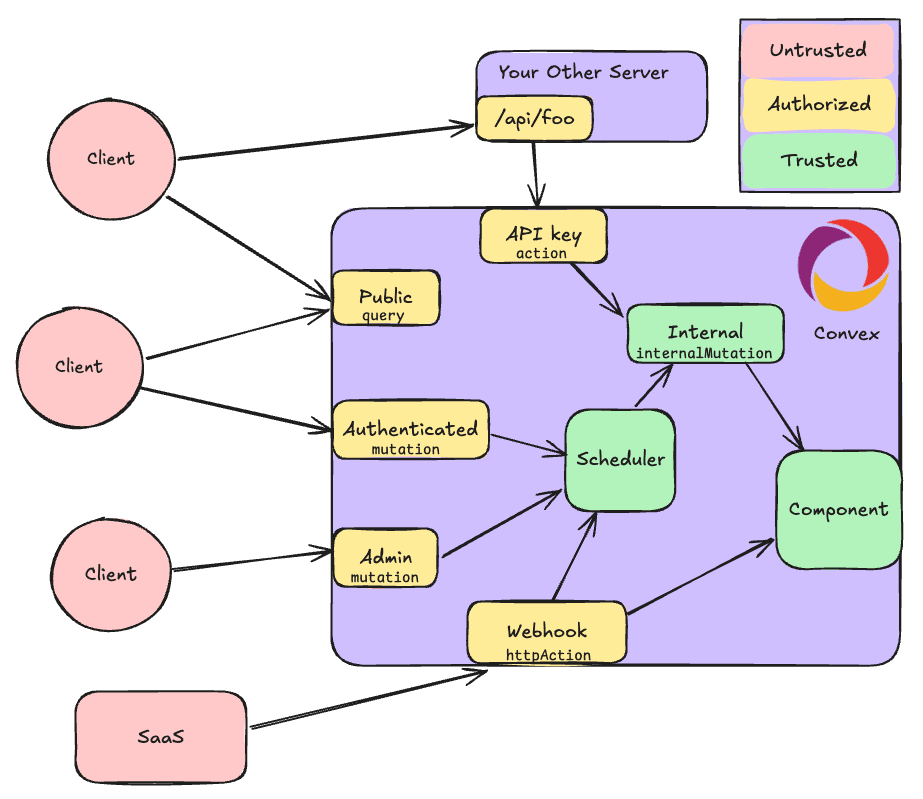 Authorization should happen within your server at the boundary before entering higher trust contexts.
Authorization should happen within your server at the boundary before entering higher trust contexts.
The boundary between untrusted and trusted domains is a high leverage place to enforce authorization by virtue of having the most precise user intent while also being in a trusted environment.
With this framing, it makes sense to add authorization at the boundary of your backend. When a request enters your Convex backend, function arguments are validated to prevent mistakes or malicious payloads. In the same way, one of the first things you should do in your functions is authenticate the entity, then authorize their request.
- Is this function public, or does it require an associated user?
- Is this endpoint intended for admins only? Are they who you’d expect to see calling this function?
- Are the parameters to the function referencing resources that they should have access to?
- Is the associated operation (add a team member, change a billing plan, etc) something they should be able to do?
- What other parameter-specific controls make sense?
See below for an example of conditionally rendering UI.
Authorizing with standard software abstractions
Recall that security often involves multiple overlapping strategies - often referred to as defense in depth. In addition to checks in custom functions or within specific endpoints, you can also layer on checks at other abstraction boundaries, while trying to maintain semantically meaningful operations. What I mean by “semantically meaningful” is a check like “Can user X invite user Y to team Z?”.
One approach teams will take is to centralize fetching and modifying certain resources into dedicated modules. For instance, if you always update user statuses via a meaningfully-named function in convex/users/update.ts, then you can consolidate the authorization and document update logic, while also making it clear at the call-site that authorization is being performed.
1// will ensure this is a valid operation internally
2await inviteUserToTeam(ctx, {
3 inviteeId: args.inviteeId,
4 invitorId: ctx.user._id,
5 teamId: ctx.teamId
6});
7The more you call well-defined functions rather than directly modifying data, the more specific controls and behavior you can define.
See below for an example of replacing a database interface with strict interfaces to avoid bypassing.
Authorizing at service boundaries
Related to normal software abstractions, strong isolation boundaries such as (micro)services, RPC, or Convex Components provide strong guarantees that an API can’t be bypassed. Often users ask why they can’t directly query a database table encapsulated in a Convex Component, or might wonder why patching globals in their calling code doesn’t affect component behavior. The reason is their tables are isolated, and the code runs in a separate javascript execution environment, providing strong isolation guarantees. If you authorize at the API boundary, you only need to reason about that interface and not worry that some far-flung code isn’t bypassing your API.
Authorizing database operations
While the optimal place to authorize might be at a higher level, it can be reassuring to add some basic low-level safeguards. This can look like enforcing rules on a per-row (per-document) basis.
This can be a good defense against bugs or gaps in higher layers. When done correctly, it can complement other strategies to give you more “defense in depth.”
It is also a practice that can make compliance easier to prove. Having centralized limits on certain behaviors (e.g. who can read a table with PII) can be easier to reason about than auditing all of the ways someone may indirectly get a reference to those sensitive tables.
My advice is that it should be a fallback - if you ever violate an data layer rule, it should indicate that there is a bug and a developer should get notified ASAP. It should not be the first or only line of defense protecting your data from clients.
See below for an example of implementing Row-Level Security (RLS), as well as some of the tradeoffs in practice.
Authorization in Practice
Rendering authenticated content conditionally
One easy way to avoid rendering content that requires authentication is to use the <Authenticated> and other utilities.
1import { Authenticated, Unauthenticated, AuthLoading } from "convex/react";
2
3<Authenticated>
4 <YourLoggedInContent />
5</Authenticated>
6<Unauthenticated>
7 <SignInPage />
8</Unauthenticated>
9<AuthLoading>
10 <ContentSkeleton />
11</AuthLoading>
12Recall that this is a UX consideration, not a security strategy!
Custom Functions as middleware
In Convex, there are helpers to define custom functions that wrap your serverless functions (queries, mutations, and actions). They can intercept arguments, inject arguments, run arbitrary code, all with runtime validation and type safety.
These are similar to traditional middleware, with some design choices to avoid common pitfalls. For instance, there is only one layer of wrapping. Instead of nesting behavior inside of behavior, the recommended pattern is to use composition: to consolidate logic into regular shared functions. That way you can cmd+click from the endpoint to the custom function site and see a single authoritative function of how the ctx and args were consumed & modified. It also allows AI coding tools to see everything in one place - they don’t have to sniff around for side effects in far-flung files.
They also don’t interfere with return values or return types. While standard arguments are easy to enforce, the return type of functions is very rarely similar enough to generalize, and introspecting with heuristics can lead to confusing results and unexpected.
We’ll use custom functions below in examples. You can read more about them here, see the docs here, or see the code here and tests here.
1import { customMutation } from "convex-helpers/server/customFunctions";
2import { mutation } from "./_generated/server";
3
4// Define a replacement for `mutation`.
5// i.e. `export const myFn = myMutation({ args, handler });`
6export const myMutation = customMutation(mutation, {
7 args: {
8 alwaysRequiredArg: v.string(),
9 alwaysOptionalArg: v.optional(v.number()),
10 },
11 input: async (ctx, args /* args only include those declared above */) => {
12 const user = await commonAuthorizationLogic(ctx, args);
13 const wrappedDB = wrapDatabaseAccess(ctx, args);
14 // Values returned here get added to the function's ctx and args
15 return {
16 ctx: { db: wrappedDB, user },
17 // pass through the two intercepted arguments.
18 // args: {} would mean none of the functions would get either arg
19 args: { ...args },
20 };
21 }
22}
23Note: To enforce usage of the custom functions variants, set up ESLint rules to error if you try to import the “raw” query/mutation/action builders, to ensure you always pick an option that has been intentionally curated.
Tip: use CustomCtx<typeof yourBuilder> to get the type of the ctx after it’s been modified by myMutation custom function, e.g. for use in helper functions:
1type MyMutationCtx = CustomCtx<typeof myMutation>;
2
3async function sendWelcomeEmail(ctx: MyMutationCtx) {
4 console.log(ctx.alwaysRequiredArg.toLocaleLowercase()); // type-safe
5 await ctx.scheduler.runAfter(0, internal.onboarding.sendEmail, {
6 userId: ctx.user._id,
7 });
8}
9If this seems confusing, don’t worry. More concrete examples will follow.
Basic authentication checks
You can define your own version of a public mutation that requires authentication:
1import { customMutation } from "convex-helpers/server/customFunctions";
2import { getAuthUserId } from "@convex-dev/auth/server";
3import { mutation } from "./_generated/server";
4
5// Define a replacement for `mutation`
6export const userMutation = customMutation(mutation, {
7 args: {}, // Define arguments common to all userMutations here
8 input: async (ctx, args) => {
9 const userId = await getAuthUserId(ctx);
10 const user = await ctx.db.get("users", userId);
11 if (!user) throw new Error("Unauthenticated");
12 // Values returned here get added to the function's ctx and args
13 return { ctx: { user }, args };
14 }
15}
16For endpoint functions that want to interact with a user, they use the userMutation, and internally can access the authenticated ctx.user:
1import { userMutation } from "./functions.js";
2
3// available to clients as api.notes.addNote (defined in convex/notes.ts)
4export const addNote = userMutation({
5 args: { note: v.string() },
6 handler: async (ctx, args) => {
7 console.log("inserting note for user", ctx.user);
8 await ctx.db.insert("notes", {
9 note: args.note,
10 authorId: ctx.user._id // type-safe!
11 });
12 }
13});
14Membership checks
To check that a user is a member in the right team or organization, we can use database records to track their membership status. Here we check a teamMembership ”join” table that tracks what users are on what teams, and what their status is:
1// in convex/schema.ts
2export default defineSchema({
3 //...
4 teamMembership: defineTable({
5 teamId: v.id("teams"),
6 userId: v.id("users"),
7 status: v.union(
8 v.literal("invited"),
9 v.literal("active"),
10 v.literal("suspended"),
11 ),
12 }).index("by_teamId_userId", ["teamId", "userId"]),
13});
14We can then check team membership in a function:
1// with a QueryCtx, this function can be shared between queries & mutations
2async function ensureUserIsOnTeam(ctx: QueryCtx, args: { user: Doc<"users">, teamId: Id<"teams"> }) {
3 const membership = await ctx.db.query("teamMembership")
4 .withIndex("by_teamId_userId", q =>
5 q.eq("teamId", args.teamId).eq("userId", args.user._id)
6 )
7 .unique();
8 if (!membership || membership.status !== "active") {
9 // ConvexError allows error data to propagate to the client.
10 // By default error data is hidden from the client to avoid leaking anything unintentionally.
11 throw new ConvexError({ kind: "authorization", error: "User is not an active team member" });
12 }
13 return membership;
14}
15To unify the check, we can do this check in a shared custom function that does additional checks. To avoid duplication, you can use shared helper functions and other regular software techniques. We’ll also see later how to parametrize a shared custom functions to avoid creating a new function for each variant.
1export const teamMemberMutation = customMutation(mutation, {
2 args: { teamId: v.id("teams") },
3 input: async (ctx, { teamId }) => {
4 const user = await ensureUserAuthenticated(ctx);
5 await ensureUserIsOnTeam(ctx, { user, teamId });
6 // See below for a note on returning "args: {}"
7 return { ctx: { db, user, teamId }, args: {} };
8 }
9}
10
11Note that by returning args: {}, instead of args: { teamId }, teamId is not passed through, meaning the teamId doesn’t show up in args in the function. This policy can help your code differentiate authorized variables from user-provided arguments.
Using teamMemberMutation:
1// in convex/notes.ts
2export const addTeamNote = teamMemberMutation({
3 args: { note: v.string() }, // note: no teamId validator needed here
4 handler: async (ctx, args) => {
5 console.log("adding note for team", ctx.teamId);
6 await ctx.db.insert("notes", {
7 note: args.note,
8 authorId: ctx.user._id,
9 teamId: ctx.teamId,
10 visibility: "team-only",
11 });
12 },
13});
14Next we’ll look at endpoint-specific authorization, where you know more about what the user is trying to do.
Role Based Access Control
In many applications, there are distinct categories of users that are allowed to access different endpoints. For example an admin can do anything, an anonymous / unauthenticated user can only see public data, and users are somewhere in the middle. We could track this in our teamMembership database table:
1// in convex/schema.ts
2export default defineSchema({
3 //...
4 teamMembership: defineTable({
5 teamId: v.id("teams"),
6 userId: v.id("users"),
7 role: v.union(
8 v.literal("admin"),
9 v.literal("user"),
10 v.literal("anonymous"),
11 ),
12 status: v.union(
13 v.literal("invited"),
14 v.literal("active"),
15 v.literal("suspended"),
16 ),
17 }).index("by_teamId_userId", ["teamId", "userId"]),
18});
19Then we can check their role in a function:
1// ordered least privileged to most
2const roles =["anonymous", "user", "admin"];
3
4async function ensureUserHasRoleOnTeam(
5 ctx: QueryCtx, user: Doc<"users">, teamId: Id<"teams">, role: Role
6) {
7 const membership = await ensureUserIsOnTeam(ctx, teamId, user._id);
8 const required = roles.indexOf(role);
9 const actual = roles.indexOf(membership.role);
10 if (required > actual) {
11 throw new ConvexError({ kind: "authorization", error: `User is not a ${role}` });
12 }
13}
14Parametrizing custom functions to consolidate shared logic
While you could create a new custom function type for each permutation, you can also parametrize a custom function to take extra arguments at each function definition site. For instance, we could require the developer to specify the necessary role for each publicly accessible mutation:
1type Role = "admin" | "user" | "anonymous"
2
3export const teamMutation = customMutation(mutation, {
4 args: { teamId: v.id("teams") },
5 input: async (ctx, args, opts: { role: Role ) => {
6 const user = await ensureUserAuthenticated(ctx);
7 await ensureUserHasRoleOnTeam(ctx, user, args.teamId, role);
8 // See below for a note on returning "args: {}"
9 return { ctx: { db, user, teamId: args.teamId }, args: {} };
10 }
11}
12Then, when using teamMutation, it will require that argument:
1export const suspendUser = teamMutation({
2 role: "admin", // <-- new type-safe required argument
3 args: { targetUserId: v.id("users") },
4 handler: async (ctx, args) => {
5 const membership = await ensureUserIsOnTeam(ctx, ctx.teamId, args.targetUserId);
6 await ctx.db.patch("teamMembership", membership._id, { status: "suspended" });
7 },
8});
9If you don’t supply it, the type error will force you (and LLMs) to select what role the endpoint needs.
Bespoke endpoint authorization
When you have specific endpoints that each have a specific set of requirements, stuffing all those permutations into a complicated rule system can feel over-wrought and clunky. Having a few lines at the start of each endpoint that do endpoint-specific authorization can greatly simplify things. You can still leverage the generic checks, but can add a more precise layer.
1export const reviewSubmissions = userMutation({
2 args: { assignmentId: v.id("assignments") },
3 handler: async (ctx, { assignmentId }) => {
4 const assignment = await ctx.db.get("assignments", assignmentId);
5 if (!assignment) throw new Error("Assignment missing", assignmentId);
6 if (assignment.status !== "submitted") {
7 throw new Error("You cannot review until all assignments are submitted");
8 }
9 if (!assignment.judgeIds.includes(ctx.user._id)) {
10 throw new Error("User is not a judge", ctx.user._id, assignmentId);
11 }
12 const submissions = await ctx.db.query("submissions")
13 .withIndex("by_assignmentId", q => q.eq("assignmentId", assignementId))
14 .collect();
15 await gradeSubmissions(ctx, submissions);
16 }
17});
18A benefit here is that when you’re reviewing this code, you can think through various scenarios and audit whether it’s accounted for, without jumping around to various wrappers. See below for a comparison with RLS on this point. Also recall that co-locating these checks will also make it easier for an LLM to look for gaps.
Row level security (RLS)
As mentioned above, having data access controls works as a last line of defense and can unify sanity checking. It works by enforcing some policy on every database document read or written.
Using the RLS helper, we could wrap database operations with rules:
1import {
2 Rules,
3 wrapDatabaseWriter,
4} from "convex-helpers/server/rowLevelSecurity";
5
6async function rlsRules(ctx: QueryCtx, authUser: Doc<"users">) {
7 return {
8 users: {
9 read: async (ctx, user) => {
10 // Unauthenticated users can only read users over 18
11 if (!authUser && user.age < 18) return false;
12 return true;
13 },
14 insert: async (ctx, _user) => {
15 // Anyone can create a user, otherwise how do you sign up?
16 return true;
17 },
18 modify: async (ctx, user) => {
19 if (!authUser) {
20 throw new Error("Must be authenticated to modify a user");
21 }
22 // Users can only modify their own user unless they're an admin
23 return user._id === authUser._id || authUser.role === "admin";
24 },
25 },
26 } satisfies Rules<QueryCtx, DataModel>;
27}
28
29const mutationWithRLS = customMutation(mutation, {
30 args: {},
31 input: async (ctx) => ({
32 ctx: { db: wrapDatabaseWriter(ctx, ctx.db, await rlsRules(ctx)) },
33 args: {},
34 })),
35});
36Downsides
While RLS has its benefits, it also can go off the rails in a few ways that are useful to know about ahead of time.
Bandwidth usage
Trying to be too comprehensive in RLS can lead to unnecessary database bandwidth usage and hairy code, especially if you have normalized data.
Convex caches database query results within a query or mutation, for instance a db.get(id), but if database queries access similar documents via different indexes or bounds, then you’ll be re-fetching them multiple times.
If every document needs to traverse a tree of relationships, then you can end up fetching a lot more data than you expect, making it hard to intuit what operations may be slow or expensive. It also can mean needing to define extra indexes to efficiently look up related data. For instance if each user has an ID to a “preferences” document, you might not already have an index to allow looking up a user by their preferences, but need one to enforce rules on a specific preference document.
It’s easiest to enforce when the documents being authorized already have the relevant properties accessible directly.
Convoluted rulesets
When defining rules, try to cover the basic risks. If the logic is getting convoluted, it might be time to push some of that enforcement up a layer (see previous sections).
Below we have an example of “bespoke endpoint authorization” where we’re allowing judges to grade submissions for an assignment. Think about what the access rule for submissions would need to be, if it was enforced on each individual submission access:
- Look up the assignment associated with every submission. (On the per-document context, it isn’t clear that it is all the same shared assignment).
- For each assignment, see if any of their
judgeIds match some current user (what if the current context is asynchronous and doesn’t have one canonical “user” entity?). - Also check that the assignment is “submitted” so judges can’t peek at draft content,
- …unless the user is the submitter, in which case they can edit it,
- …but only if the assignment hasn’t been submitted yet (to enforce the deadline),
- …and only once the assignment has officially started,
- …unless there’s some mechanism whereby a judge gives them an exception to either,
- …or if there is another state in some other feature whereby a user can see another user’s work,
- …and only let the judge update the grade field of the submission.
Codifying all of this requires reflecting the nuances of this one specific use-case into a single ruleset that will be applied on every access.
Throw an error or pretend it doesn’t exist?
RLS implementations often will silently filter out documents, rather than throw an error. The rationale is that you might be leaking information to a user. If a user tries to fetch a user by their email, telling the user that they don’t have access indicates to them that there is a user with that email address.
Some downsides of this are:
- If you’re filtering out data while listing or paginating, you may need to read an unbounded number of records before you fulfill the request (or risk exposing that some documents in that range exist but they didn’t have access to them).
- Users getting empty or missing results might make it seem like their data is missing when instead they might no longer be authorized or not logged in.
My take is that the silent filtering behavior is a responsible approach when RLS is your first or only line of defense. If it is only catching bugs, then treating it like an error is a better default, and easier to surface into alerts and bug tracking systems. If you do want to silently filter, you can still log these events and use Log Streams to a service like Axiom to create alerts.
Authorization in the age of AI
Disclaimer: the below are based on heuristics developed by writing other evals, working with AI, and some of our learnings developing Chef, which needs to be excellent at writing full stack apps with built-in auth.
Local reasoning
LLMs are great at coding, provided they have the right context and can navigate the code effectively. Make endpoint definitions self-describing. If they expect a user to be authenticated, or to limit access to a resource, have that be explicit in the code at that site, not implicit based on side-effects happening elsewhere.
If you have side-effects like wrapping database operations, explicitly tell the LLM about it and where those side-effects are, so it knows what to check and where it should write new rules. This is less mission-critical if those are only used as a last resort.
Policies and abstractions
LLMs do well with well defined interfaces that convey intent. Having hidden side-effects or nuanced expectations around which functions are called in which order and what has been assumed to have been checked already is likely to lead to more issues. I haven’t tested or written evals for this, for transparency.
Type safety
When LLMs fail to one-shot a solution, having strong type safety can give it feedback before executing any of it, and the type errors are very effective at guiding it to correct syntax. It is very common in my experience to see AI coding helpers tab-complete a guess, then when there’s a type error, immediately suggest the correct syntax.
Having types that flow through your full control flow give the most consistent feedback for full stack development. From client API function types through type-safe middleware (such as TanStack Start or Custom Functions), through to type-safe endpoint handlers (with runtime validation) all the way to database validators (that enforce guarantees with data at rest), types can provide the map of how to start implementing a feature anywhere in the stack and have it propagate to the client and down to the database schema.
Takeaways
I genuinely hope this helps you reason through authorization and shows some powerful patterns to make your apps more secure. Keep in mind:
- Authorization is “what can they do,” authentication is the “who.”
- Co-locating authorization with user intent allows the most precise control.
- Use software abstraction boundaries to delegate responsibility and enable local reasoning.
I recommend starting at the endpoints and moving outward, creating abstractions as you go based on concrete needs.
I’d love to hear what you think in Discord, on Bluesky, or Twitter.
Footnotes
-
The “upstream” terminology can be thought of as a “flow” from a user’s request as it moves “downstream” through function calls. It’s easy to forget the physical analogies - but “control flow,” “data flow,” “streaming” and others all borrow from the same analogy. In the diagram above, “upstream” is to the left. ↩
Convex is the reactive backend platform that keeps up with you and your agents. Database, functions, workflow, sync, search, file storage, and more. All TypeScript, zero glue.