
Convex: The Database that Made Me Switch Careers

Today is my first day working for Convex 🎉, so I thought I’d take the opportunity to share my thoughts on why I decided to join and what excites me about the technology. So for my first post, I'll discuss the reasons behind my decision, explore some interesting features of Convex, and reflect on how I think this technology could impact the future of web development.
My Background
Most of my career has been games and web development focused. I wrote my first game at 7 then my first paid website at 13 (thanks dad for that opportunity!) and I never really stopped. I went on to be one of the founding members of Playdemic working on some of their biggest games like Gourmet Ranch and Village Life.
 Gourmet Ranch - a Facebook game
Gourmet Ranch - a Facebook game
After moving to Australia in 2014, I continued my journey in game development. I created my own titles, including Mr Nibbles Forever. Later, I broadened my horizons by joining a local gaming company, followed by roles at a machine learning company and a blockchain payments company.
Six years ago my co founder and myself started a small gaming company and produced an innovative web game called BattleTabs that has been played by millions of players.
Here is the trailer for the game:
Discovering Convex
It was while working on BattleTabs that I discovered Convex. You see, I try to write at least one thing on my blog per month and have surprisingly managed to keep this up for the past 17+ years. I find this practice helps hone my writing and communication skills while simultaneously forcing me to experiment with and stay on top of whatever's currently hot in the technosphere.
I'm not exactly sure how I first heard about Convex, but after tinkering with it for a couple of evenings, I was totally sold. I ended up building a little demo app called ThreadX, which was a Threads / X clone (remember when those were in the zeitgeist?).
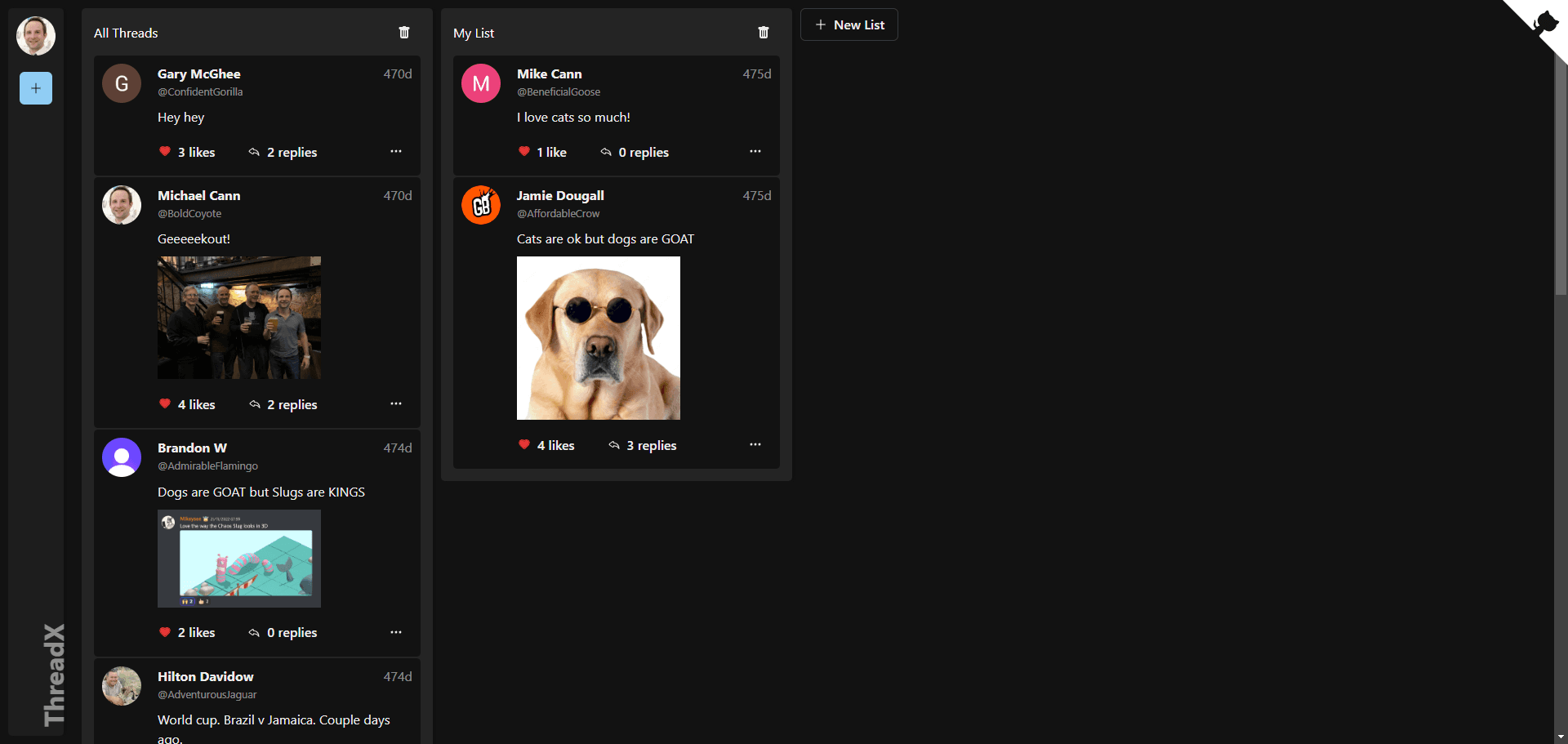 A screenshot of ThreadX a lightweight X or Threads clone
A screenshot of ThreadX a lightweight X or Threads clone
Need for Speed
What struck me was the sheer speed at which I was able to get this thing up and running and not only that it had features that I had been struggling with implementing myself for BattleTabs.
Because Convex is a bundler, API layer, server-side route handler, database AND client-side query handler then you get incredible synergies from all of that.
For example here is the server-side mutation to send a message:
1export const send = mutation({
2 args: {
3 body: v.string(),
4 imageId: v.optional(v.string()),
5 },
6 handler: async ({ auth, db, storage }, { body, imageId }) => {
7 if (body.length > 1000) throw new Error("message too long");
8 if (body.length < 5) throw new Error("message too short");
9 const user = await getMe({ auth, db });
10 await db.insert("messages", {
11 body,
12 authorId: user._id,
13 likes: BigInt(0),
14 replies: BigInt(0),
15 imageId,
16 });
17 },
18});
19
20Once you write the above code, the bundler automatically creates a type-safe API that you can call directly from your frontend.
1export const NewMessageModal: React.FC = ({}) => {
2 const sendMessage = useMutation(api.messages.send);
3
4 return (
5 <Modal>
6 <Button onClick={() => sendMessage({ body: text, imageId: storageId }).then(onClose)}>
7 Post
8 </Button>
9 </Modal>
10 );
11};
12
13It's fantastic, especially if you've ever had the "pleasure" of working with GraphQL codegen in a project of any size—this way of working is dramatically faster.
Queries are "Computed" Values
I've invested considerable time contemplating and implementing various real-time systems for both BattleTabs and other projects. Let me tell you, it's never straightforward and rarely "just works." There are invariably caveats and challenges.
Some issues I've grappled with include:
- Functionality involving lists of entities
- Inefficiency and high costs
- Scaling challenges and maintaining vast numbers of WebSocket connections
- Limited "application-level" functionality, missing database changes from dashboards, migrations, or other sources
- Achieving a smooth developer experience
So, I was thrilled to discover that with Convex, I could simply write this on the server:
1export const listAll = query({
2 args: {},
3 handler: async (context) => {
4
5 // This query is automatically kept "live" so that if new messages are added
6 // or removed or if one of the documents' isReplyToMessageId value changes
7 // it is updated to reflect that
8 const messages = await context.db
9 .query("messages")
10 .filter((q) => q.eq(q.field("isReplyToMessageId"), undefined))
11 .take(10);
12
13 return messages;
14 },
15});
16
17and this on the client:
1export const AllMessages: React.FC<Props> = ({ }) => {
2
3 // This is updated whenever the listAll query changes and cached when its not
4 const messages = useQuery(api.messages.listAll) || [];
5 if (!messages) return <Spinner />;
6
7 return (
8 <>
9 {messages.map((message) => (
10 <Message key={message._id} message={message} />
11 ))}
12 </>
13 );
14};
15
16The client is now ALWAYS kept in sync with the listAll query.
🤯
The above looks deceptively simple, but it's solving some incredibly complex problems. Just imagine how you'd tackle this using Postgres and NodeJS!
In my opinion, this is the perfect developer experience. You simply declare the data you want in an easy-to-understand query, and the platform handles the rest. It ensures that "messages" updates whenever there's something new or modified.
What's even more impressive is that this works for queries referencing other documents (JOINs). If any of those joined documents change, the parent query is invalidated and updated accordingly.
I like to think of Convex queries as akin to MobX computeds. They're essentially a derived form of state that's automatically kept up-to-date.
Flexible, Type-Safe Database That Scales Infinitely
Throughout my career, I've worked with a wide array of databases.
I began with MySQL and MSSQL, then jumped on the NoSQL bandwagon with MongoDB. When the hype subsided, I shifted to Postgres. Along the way, I experimented with hosted solutions like Parse, DynamoDB, and Firebase.
While NoSQL databases offered flexibility and scalability, I often found myself building layers of abstraction to enforce a "schema"—essentially recreating a relational structure atop NoSQL, which felt counterintuitive. This led me to Postgres, which offered a blend of relational tables and JSON columns.
However, relational databases like Postgres aren't without their flaws. Issues with scaling, costs, and migrations frequently left me frustrated. Tools like Prisma can accelerate development, but they're still more rigid than NoSQL alternatives.
One particular pain point with relational databases was the inability to declare different "types" of rows within a single table.
To illustrate, in my demo app "ThreadX," users can create various lists of messages.
If you were designing a Postgres schema for a “List” this, how would you structure it?
At first glance, it might seem straightforward. We could create a table called List where each row represents a single list with columns such as name and ownerId.
1CREATE TABLE List (
2 id SERIAL PRIMARY KEY,
3 owner_id UUID NOT NULL REFERENCES Users(id),
4 name TEXT NOT NULL
5);
6Now, let's consider how a product like ThreadX might evolve over time...
Imagine management approaches you with a request: they want users to create different "kinds" of lists. Specifically, they're looking for lists that allow users to filter messages by a given search term in addition to the standard lists that just show a chronological order of posts.
This is relatively simple to implement in the UI—we'd just add a radio button that lets users select what "kind" of list they want to create.
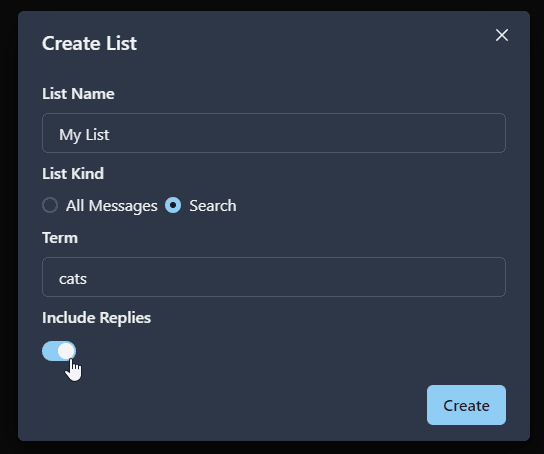
This is really easy to model in Typescript simply as a union:
1type List =
2 | {
3 kind: "all_messages";
4 ownerId: string;
5 name: string;
6 }
7 | {
8 kind: "search";
9 ownerId: string;
10 name: string;
11 query: string;
12 includeReplies: boolean;
13 };
14
15But what about the database? Well, it becomes tricky with Postgres as a relational database. It doesn't allow adding or removing columns based on the "kind" of row. Instead, you have to make some columns nullable and provide nulls for fields that don't exist on that row "kind."
1CREATE TABLE List (
2 id SERIAL PRIMARY KEY,
3 kind TEXT NOT NULL CHECK (kind IN ('all_messages', 'search')),
4 owner_id UUID NOT NULL REFERENCES Users(id),
5 name TEXT NOT NULL,
6 query TEXT, -- Nullable, used only for 'search' kind
7 include_replies BOOLEAN -- Nullable, used only for 'search' kind
8);
9Now imagine we add many more "kinds" of lists where some properties CAN be null as a value. Things start to get messy, and managing this becomes quite a cognitive burden.
So how does Convex handle this? Well let me show you the schema:
1export default defineSchema({
2 lists: defineTable(
3 v.union(
4 v.object({
5 kind: v.literal("all_messages"),
6 ownerId: v.id("users"),
7 name: v.string(),
8 }),
9 v.object({
10 kind: v.literal("search"),
11 ownerId: v.id("users"),
12 name: v.string(),
13 query: v.string(),
14 includeReplies: v.boolean(),
15 })
16 )
17 ).index("by_ownerId", ["ownerId"]),
18});
19
20As you can see, this mirrors our TypeScript types above, which is incredibly convenient. It perfectly aligns with how we ideally construct concepts on the UI side.
Convex also supports "optional" types and unions in its database schema, enabling "migrationless" changes to your database. It does this in a super-safe way, ensuring your DB can't have a schema that conflicts with the data within it.

This is crucial because if you've ever worked with a NoSQL DB like Mongo or Dynamo, you've likely encountered that one pesky document that somehow doesn't match the expected type—causing numerous headaches at runtime.
Transaction Guarantees
One of the key advantages of Convex DB is its guarantee of atomic data changes. This transactional nature has proven invaluable, especially given my past experiences with data corruption issues in Postgres.
In scenarios where multiple users (or even the same user on different devices) might simultaneously write to the same record, not using transactions can lead to data corruption. While it may seem unlikely due to the speed of database operations, increased traffic inevitably leads to such issues, resulting in unpredictable and hard-to-replicate bugs.
Although solutions like Prisma Transactions or Sequelize Transactions exist, they require careful implementation throughout the development process. The common pitfall is forgetting to include transaction parameters when splitting logic across files and functions, leading to operations outside the transaction boundary.
Let's look at a concrete example using Prisma:
1
2const prisma = new PrismaClient();
3
4// This looks correct at first
5async function createPostForUser(userId: string, content: string) {
6 return await prisma.$transaction(async (tx) => {
7 const user = await tx.user.findUnique({ where: { id: userId }});
8 if (!user) throw new Error("User not found");
9
10 return await tx.post.create({
11 data: {
12 content,
13 userId: user.id
14 }
15 });
16 });
17}
18Now imagine that at some point we decide to refactor the user lookup into a separate function for reusability:
1const prisma = new PrismaClient();
2
3// Uh oh, this function doesn't know about the transaction!
4async function getUser(userId: string) {
5 return await prisma.user.findUnique({ where: { id: userId }});
6}
7
8async function createPostForUser(userId: string, content: string) {
9 return await prisma.$transaction(async (tx) => {
10 // This query now happens OUTSIDE the transaction!
11 const user = await getUser(userId);
12 if (!user) throw new Error("User not found");
13
14 return await tx.post.create({
15 data: {
16 content,
17 userId: user.id
18 }
19 });
20 });
21}
22In this refactored version, the user lookup happens outside the transaction boundary, potentially leading to race conditions if the user is deleted between the lookup and post creation. This type of subtle bug can be hard to catch in development but cause issues in production.
Convex takes all these potential foot-guns away for you. All data updates occur within mutations, where every read and change is automatically part of a single atomic transaction. This approach makes the process explicit and easy to reason about.
Here is another, slightly more complex example in Convex:
1export const createLikeForMessage = mutation({
2 args: {
3 messageId: v.id("messages"),
4 },
5 handler: async ({ auth, db }, { messageId }) => {
6 const user = await getMe({ auth, db });
7 const message = ensure(await db.get("messages", messageId), `couldnt get message ${messageId}`);
8
9 const existing = await db
10 .query("likes")
11 .withIndex("by_messageId_likerId", (q) =>
12 q.eq("messageId", messageId).eq("likerId", user._id),
13 )
14 .unique();
15
16 if (existing) throw new Error("cant like same message twice");
17
18 await db.insert("likes", { likerId: user._id, messageId });
19
20 await db.patch("messages", message._id, { likes: message.likes + BigInt(1) });
21 },
22});
23Without a transaction, it would be possible to "like" a message twice if triggered simultaneously from different devices, potentially causing runtime issues. Convex, however, ensures all mutations are within a transaction. If changes occur before completion, the mutation is re-run, preventing duplicate likes and maintaining data integrity.

Reducing Cognitive Overhead
As applications grow, managing complexity becomes increasingly challenging. New team members join, others leave, and knowledge about system functionality can get lost. Without diligent management of technical debt, even the most elegantly designed initial version can devolve into a tangled mess.

This is where Convex's simplicity shines. Its three functional categories - Queries, Mutations, and Actions - provide a clear, logical separation. This structure makes it easy to understand the purpose of each piece of code at a glance.
By restricting side effects in Queries and Mutations, Convex encourages a deterministic and functional code structure. This approach naturally prevents many common pitfalls that lead to convoluted codebases.
The philosophy aligns well with React's unidirectional data flow and controlled side effects, creating a cohesive and intuitive development experience across the stack.
Conclusion: Why I'm Excited About Convex
I've only scratched the surface of what Convex offers. From Scheduled Functions with Exactly Once guarantees to its VectorDB capabilities and the new Components system, there's so much more to explore. But I don't want to overwhelm you with details in this already lengthy post.
When I tell people I'm joining Convex, many haven't heard of it. I jokingly describe it as "Firebase for adults" but that doesn't do it justice. It's challenging to convey its full potential without diving into technicalities.
That's why I'm thrilled to join Convex as a Developer Experience Engineer. I can't wait to share my excitement and help others discover the power of this platform. There's something special brewing here, and I'm eager to be part of it. If you're curious about Convex or have any questions, feel free to reach out. Let's explore this journey together!
Convex is the backend platform with everything you need to build your full-stack AI project. Cloud functions, a database, file storage, scheduling, workflow, vector search, and realtime updates fit together seamlessly.