Efficient COUNT, SUM, MAX with the Aggregate Component
Counting, summing, finding the min or max value is quite frankly one of the most confusing aspects for people new to convex. Before I became an official Convex fanboy, I flagged it as one of the things that I really don't like about Convex when I first encountered it. This is more of a technical issue, but there are no aggregate queries in the database. So, this means it's not possible to count the number of items in a query without explicitly iterating them. If you are like me and you come from the SQL world, then you're probably used to doing something like select count star from some table, but no such thing like this exists on convex. Why? Why on earth not? Well, I did just do a whole video on the why of that. So, you might want to check that one out first if you want to dive deep into that particular question. But, they're too long, didn't watch. is that to perform aggregates such as count or sum, you kind of have to scan all the rows in the database which can really cause performance issues as your data grows. So, Convex kind of takes the philosophy of forcing you to think upfront about how to manage those aggregates yourself. In the solution section to that video, I briefly mentioned that you could use something called the aggregate component to help out. And I said if people want to have more information upon the aggregate component, they leave me a comment down below. Well, the people have spoken. So, if you are one of those commenters or you're somebody who's looked at the aggregate component before and noped out of there or you're totally new to convex and have no clue what I'm talking about, then this is the video for you. We're going to go through how to get started with it, how to do some basic aggregations like counts and sums before progressing onto some more advanced use cases. Then, if we have time at the end, we're going to talk a little bit about how it works underneath the covers. Oh, and do stick around to the end as I'm going to give what might be a bit of a spicy take on all of this. So, once you've dropped me a like and sub, let's get into it. All right, so I'm going to assume that you have a Convex project already running. If not, check out one of the quick start guides for how to get started there. Then, you're going to want to install the aggregate component with npm install at convexdev/agregate. And then, you're going to want to tell Convex how to use the component by creating a convex.config.ts ts file in your convex directory and popping in something like this. Note here, it's a bit more complicated than you would probably typically have it. For this video, we're going to be using the same component multiple times with different names. So, it allows us to easily identify the component um within the convex dashboard. Right now, you got the component set up. Let's have a look at how to use it. So, let's imagine we're going to build a game that is going to show a leaderboard, something like this. So here we want to show the player name, the score, and rank. Oh, and by the way, if you want to try out any of these demos that I'm going to show in this video yourself, they're all available in the example folder in the aggregate component repo. I've left a link to it down below. Anyways, hopping back into the code. First thing we need to do is define a normal convex table for recording our scores in our leaderboard like this. And then of course, we're going to need a mutation uh a way to insert our score into the database. So here we define our ad score mutation and we push a record into our leaderboard table. All right. So now the question is how are we going to display a page of data in our leaderboard table? I guess we could do something like this. Here we use the dot collect function to grab every single row in the table. We sort them and then we just slice off a page of items. And this would work, but as you've probably already guessed, this isn't going to scale too well as we get thousands, tens of thousands, millions of scores added into our database. We have to read every single row just to get back one page of results. What we kind of want to do is something a bit like this. Here, we're trying to order the scores by descending, skip to our offset, and then take just what we need. But as you may have noticed, there's some red squiggles here because convex doesn't have an order by or a skip. Well, comics does kind of have an order by if you use an index. Um, but it definitely doesn't have a skip. And related to this issue is the one of how we go about ranking our scores. So, just think about this for a second. How would you go about efficiently ranking these scores? Say I add another score here. Let's say Mikey C with a score of 99999. Well, how am I going to determine my rank? Well, I guess as long as the table's sorted, I could loop through all the scores until I find the one that I'm above and that's my rank. But h this doesn't sound very efficient. If we're going to have millions of scores in the database, that could be millions of scans just to find out what rank I am. But then the issue is I'm going to insert myself into the position here and give myself a rank, but then everybody below me is going to have to then move down one slot, which is going to cause a lot more um mutations into the database. This really doesn't sound very efficient, does it? But fear not, as this is precisely where the aggregate component steps in. So now let's define a table aggregate at the top of our file like this. Here we tell it that we're going to want to sort by the score from the leaderboard table and it's going to be a number. Note that we are using a negative value here because the aggregate component by default sorts its entries in the ascending form. So that's from the smallest to largest. But we actually want to sort in the descending form. So from largest to smallest. So by negating the score here, it kind of does that. It'll make more sense in a minute. So now when we insert a new score, we must also remember to insert it into the aggregate component like this. For now, we're going to assume that there's no existing scores in the table. And we'll talk a little bit later about what happens if you have a table with existing data in it. So now we're inserting data into our leaderboard table and our aggregate component. We can update our paging query to look like this. So it's pretty simple. We're going to use the aggregate components.app app function to find the score that is at the given offset in our page. So once we have that first item in the page, we can then use the pageionate function to define the lower bound that we're going to pageionate over and the page size as our number of items. And once we have that, we can then go through each of those items in the page, look up in our own leaderboard table, uh, the document, and return the results. Cool. So, let's try it out. We have our first five scores here, and we can flip through the pages, and the scores go down, and everything feels nice and snappy. We can change the uh number of items that we want in a page, and it all just works. Awesome. And up here we can add another score and it should be entered into the right place. Cool. And we can remove some entries and it all just updates nicely. Okay. So I guess what we've done here is to say what is going to be the given score for this particular rank we're interested in, right? So as long as our leaderboard scores are ordered in a descending form, we can just grab five or whatever items and just show them. And this kind of makes sense, right? You can see how this would be slow if we were to do this without the aggregate component. Like for page 100, for example, we would have to manually scan through 496 other rows if we wanted to get just that page that we were interested in. And this would not only be just slow, it would also be really problematic due to the way that the transactional nature of convex works. So like if any of those 496 rows uh that we scan through change then it's going to invalidate our page and so just even a simple name change would cause the row to be invalid validated which causes our query to be invalidated and yeah it could get expensive very quickly. So the way that the aggregate component works is it stores the data in such a way that allows us to skip lots of those document reads and get right to the part that we are interested in. But I'm getting a little bit of ahead of myself here. We're going to talk about how the aggregate component works a little bit later on in this video. But for now, let's just see what else we can do with the component to help us out. So now let's say uh that instead of wanting to look up a score from a given rank, we want to do the inverse of that. We want to find out what rank I would be g would be given if I had a specific score. So we can do this really easily with the index of function on the aggregate. Oh, and not forgetting to invert the score as we're actually storing our keys in inverted form in aggregate that we've talked about before. And now if we take this for a spin, we can enter a score here and we get the correct rank. And again, this is reactive just like everything in convex. So if we add new scores or remove them, then it's instantaneously reflected. And finally, what happens if we wanted to get some stats on a particular player like find out what my average score is or my higher score? Well, we can do that pretty easily if we pull in another aggregate. So now, um, we've changed the sort key from being just a score to being this array, this tupil of the name of the person who got the score and the score. So, it's first sorted by the name and then sorted by the score within that name for that person. We could also potentially do this using namespaces, but we'll talk about namespaces in a minute. We've also added this sum value here, which is going to sum all the scores up and cache them inside the aggregate component as you will see in a minute. Okay. So, then to show the average score for someone, we can do this here. Here we use the component to count the scores belonging to the player and the sum of the scores and then just returning the average from that. And don't forget because of the way the aggregate component stores these values, this lookup is super fast and efficient and doesn't have to scan all the rows. If we want to show the highest score the user's ever gotten, then we can use the max function like this. Once we have the item, we can pull off the sum value. This maybe should be called max value, but anyway, it's called sum value. Okay, let's take this for a spin now. So, I can enter my name in here and cool, it works. I can see my average and highest score. And of course, if I change it or add something else, uh, then it's going to update. Awesome. Love it. All right. So, so far so good. What else can we do with the aggregate components? Well, if you know that your data is going to be clearly separated, uh, like the albums in this photos demo here, then you can use namespacing to more efficiently segregate your data cuz this is going to reduce the amount of reads and writes uh, by just segregating it by namespace. So when you define your aggregate at the top, just tell the component what namespace we're going to be using for this given document. Then you can use that namespace when calling into the component. So here you see we have a um query that is going to get the number of photos in a given album and by using the name space it means that if um somebody adds a photo to another album then it's not going to cause this query to rerun. We could also use the aggregate component to do efficient randomization like in this demo. So we can click this button to get a new random song or we can show a page of randomized playlist. To do something like this, we need to use a null as our sort key. And basically what this is going to do is it's going to cause the component to order the values in its structure by the ID of the document which is effectively random because it's a gooid. Then we can use the dotrandom function to efficiently get some random song. Now the final demo here is um showing various stats that we can get from the aggregate. We can add values here and you can see that the numbers change as I add more latencies. And this one is demoing a lower level API called the direct aggregate. So with this one we don't actually tie our aggregate to any specific table. Instead we're going to tell it what our key and value is directly. So this is the mutation um that you would call when you wanted to report uh a latency. So here we insert with a key of our latency. Our ID is just anything and our sum value is uh our latency. We're going to add up our latencies to get our sum. And here's how we uh return that data to the user in the query. We're using our count. We're using a sum. We're using our min max. combine it all together to get a bunch of stats and then we can just show that on the client. Easy. Okay. So, before we pop the hood of the component and work out how it does its magic, um let's talk about a couple of issues that you might encounter with the aggre aggregate component. Now, you may have noticed what should we call it an operational issue uh when working with the component. Whenever we add a document into a table like the leaderboard here, we must also remember to add it into the aggregate. And the same goes for when we remove something or when we update something. We always have to remember to update the aggregate component because the keys and values could cause it to get corrupted or out of sync if we don't. This required coupling is necessary, but it is also very errorprone. If you or one of your teammates forgets to include the aggregate component line somewhere, then you can easily end up with an aggregate component that's out of sync or corrupted. Fortunately though, there is a solution to this problem in the form of triggers and custom functions. Triggers, if you're not familiar with them, are a library that's provided by the Convex helpers repo and allows you to wrap your database so that whenever you make a change to it, it can also trigger something else to happen somewhere else. I'll show you what I mean. So, here we're going to create our triggers object by registering it on our leaderboards table and then attaching both aggregates like so. We can then pull in um the custom functions library from the convex helpers repo um as it's going to allow us to write a custom mutation that looks like this. We can then go ahead and replace our mutations in here with our mutation with triggers custom function. And then we can go ahead and remove all those lines where we were having to update or insert into the aggregate because our triggers are now going to cause the aggre aggregate component to be automatically kept in sync whenever we make a change to our leaderboard table. And this is really nice as it allows us to massively simplify our code and remove that errorprone nature of our aggregate getting out of sync from our table. All right, so let's just make sure this all works by taking it for a spin. Cool. Yep. I can add, remove, update entries as before. Very nice. Now, as we are talking about issues, uh there is one other issue with aggregate component that I should point out that might bite you if you're not careful. So, as you're probably aware, every single convex project comes with a dashboard. So you can go into it and you can go in and edit the data inside the table and it instantaneously reflects on the UI because that's how convex works. But now that I've updated the name of this score here watch what happens if I try and delete this row. Now bam, error. The issue is is that our aggregate has now gone out of sync with our leaderboard. But Mike, why? We've just used triggers. Why? How has it got out of sync? You told me that there was going to be automatically kept in sync. Yeah. Well, unfortunately, triggers don't work when you make changes to the data from the convex dashboard. And right now, unfortunately, there is no work around this. You just have to be really careful. Make sure that if you're going to change data through the dashboard that you also remember to either update the aggregate component or reync it or something like that. We have been talking internally about ways to fix this maybe with platform level triggers. So the the dashboard would al also cause triggers to be fired, but unfortunately that's probably going to be a little bit way off before we get to a solution there. If you're keen to see a proper solution to this being developed, then leave me a comment down below and we'll see if we can bump up the priority on that. So hopefully at this point you should have a good idea what the aggregate component is and how you can use it in your own project. But what happens if you have some existing table with some data in it already that you want to incorporate into your component? How can you go about adding the aggregate component on after the fact? Well, to solve that issue, we can pull in another component, the migrations component. We can then create a migration that will iterate over every row in the leaderboard table, for example, and populate our aggregate in a safe way. If you're interested more in this, then I recommend you check out the documentation as there's full step-by-step instructions of the sequence that you should follow. Okay, so now if you're anything like me, you're probably wondering at this point, how is this wizardry performed? Well, I started to go deep on this topic and put together a whole demo that shows how the data structure evolves over time as you add and remove items. But the hours started turning to days. Uh, so I had to reluctantly park this this project for now. But if you would like me to spend some more time on this and continue on this demo or dive a bit deeper into this this topic in the future, then leave me a comment down below. But having said that, the TLDDR is that the aggre aggregate component works by storing the data in a really efficient data structure called a balanced search tree or B tree. This is a similar data structure that you might find in a regular database like Postgress and MySQL as an index. So what we are effectively doing is building an index that we can control inside of a convex table. So by constructing this B tree in the convex database, we can turn what would be O to the N um operation into an O to the log N which is obviously much more efficient. All right, so I promised a spicy take at the start of this video. So here it is. Convex chose explicitly not to offer aggregates in their core offering and instead offload it into userland or components like this one for some very good reasons that I elaborate in my dedicated video on the topic. By making users handle the aggregation of the data themselves rather than leaving it up to the whims of the almighty query planner, you end up with a more predictable performance and cost. On the other hand though, it is more work uh to manage these simple counts and other basic aggregations yourself manually via code or via the usage of this component. And unless you use triggers, it's very easy to forget to update the aggre aggregate component when you make a mutation to the underlying data, which would leave your um component in a corrupted state and you would basically have to migrate your way out of it. Or worse, one of your teammates could change a value in the dashboard as I showed earlier in this video. Uh that would leave your component again in a corrupted state. These kinds of easy to make mistakes is in my opinion anthetical to the typical ethos of the no foot guns found in the rest of Convex. So I do wonder whether there's something that Convex should do more here. Maybe bringing some of the aggregations to the platform level or maybe make the platform work better with triggers or something like that. Well, anyways, let me know what you guys think down below. I'm keen to hear what you think about this. Right, that's just about it for me for today. I hope you enjoy this video and if you did, please leave me a like and sub. And if you wanted to check out another video a bit like this one, then you might want to check out this one I did a while back on embeddings and vector search. I dressed up as a school girl. It was kind of fun. Anyways, until next time. Thanks for watching. Cheerio. All right. So hopefully at this point you should have a good idea of what the aggre hopefully you have a good idea of what the aggre aggregate you should have a good idea of what the aggre aggregate
Counting, summing, and finding the min or max value are some of the most confusing aspects for people new to Convex.
If you're coming from the SQL world like me, you're probably used to running SELECT COUNT(*) FROM someTable. But Convex doesn't offer this functionality. Why not?
I just created a video explaining the reasons behind this decision, so definitely check out that video if you want a deeper dive.
The TL;DW is that performing aggregates like COUNT or SUM requires scanning all rows in the database, which creates serious performance issues as your data grows. Convex deliberately forces you to think about this challenge upfront by making you handle aggregation yourself.
In the solutions section of the video, I briefly mentioned using the Aggregate Component and offered to create an entire video on just that topic if there was interest.
Well…
… the people have spoken.
If you were one of those people who voted, or if you've looked at the Aggregate Component before and quickly backed away, or if you're completely new to Convex and have no idea what I'm talking about, this post is for you!
Setup
Alright, so I'm going to assume you have a Convex project running already. If not, check out one of the QuickStart guides for how to get started there.
Now you're going to want to do npm install @convex-dev/aggregate then tell Convex you want to use the component by creating a convex.config.ts file in your convex directory and adding this code:
I've included more configurations here than you would typically need. For this post, I'm using the same component multiple times with different names to help you easily identify each component in the Convex dashboard.
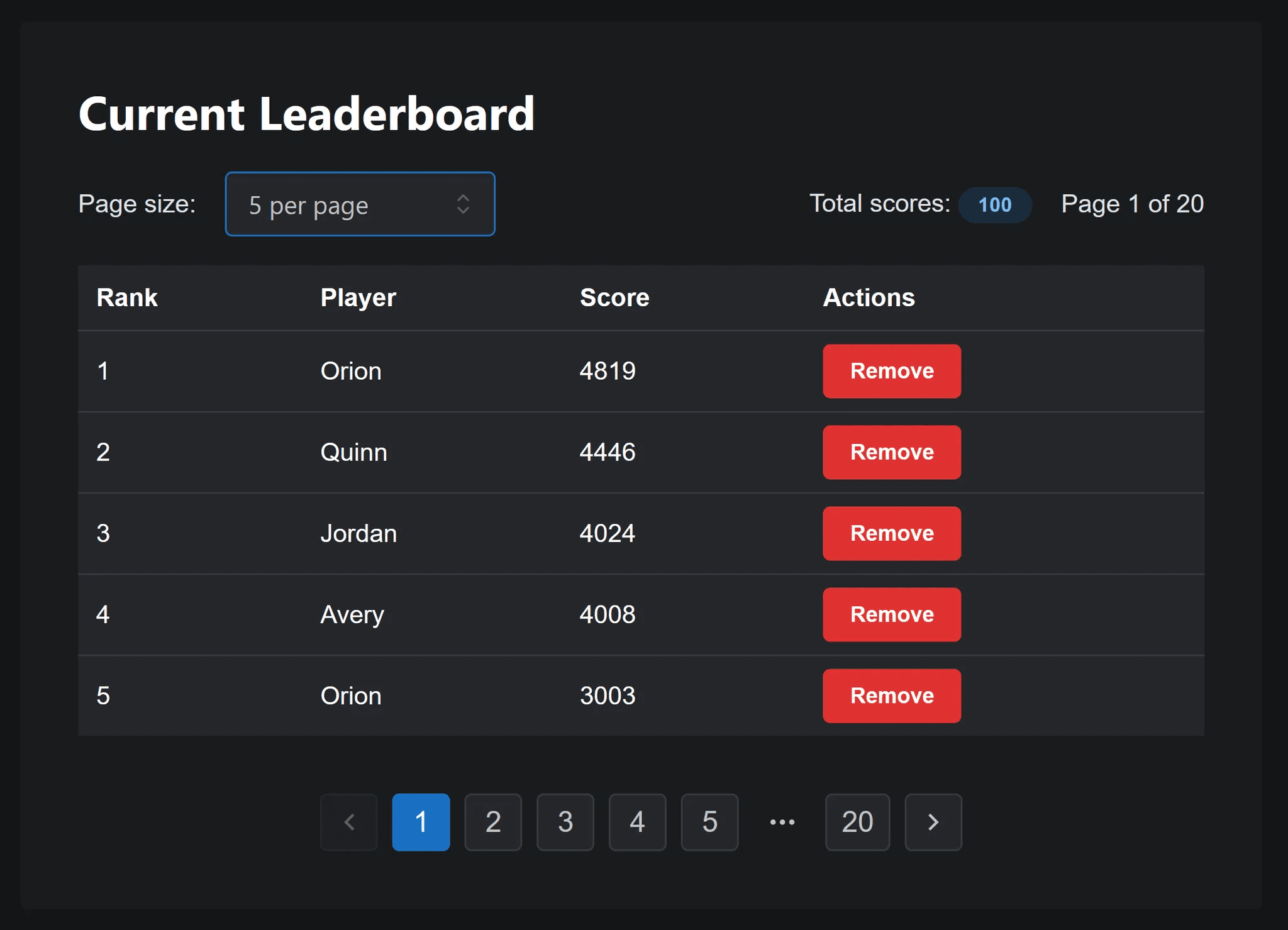
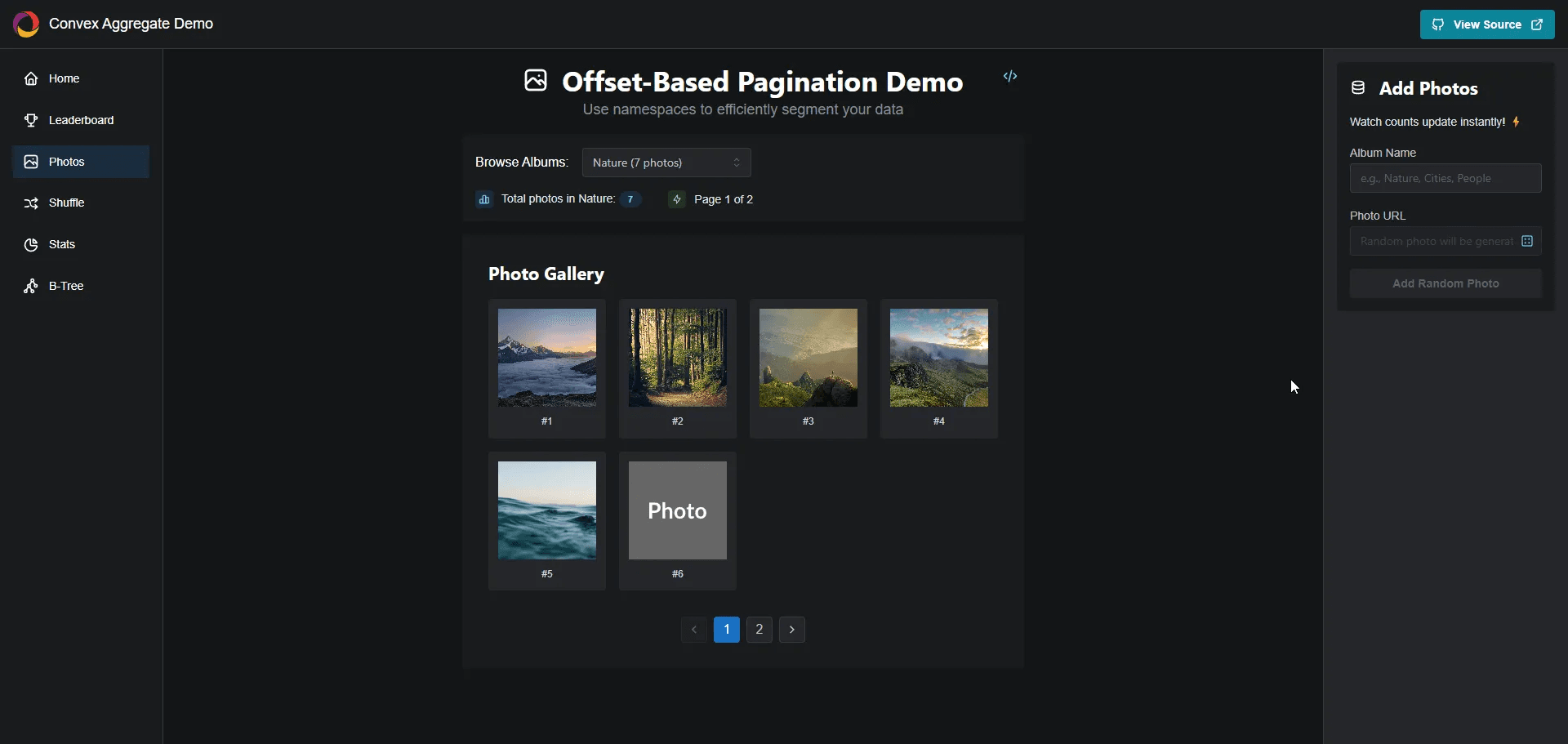
Now that you have the component set up, let's take a quick look at how to use it. Let's imagine we're building a game that will show a leaderboard like this
Our goal is to display the player's name, score, and rank on the leaderboard.
In this approach, we retrieve all rows from the table, sort them, and then extract just the page of items we need.
This works for small datasets, but it won't scale well as our database grows to thousands or millions of scores. The inefficiency comes from having to read every single row just to display one page of results.
Related to this issue though is the one of Ranking our scores.
Think about this for a second: how would you efficiently rank these scores?
When I add a new score, how do I determine its rank?
I suppose I could loop through all existing scores to find which ones are above and below mine—that's my rank. But then everyone ranked below this new score would need their rank updated since they've been bumped down the leaderboard.
This doesn't sound efficient at all, especially as our data grows.
Fear not! This is exactly where the Aggregate Component saves the day!
To start using it, we need to add a TableAggregate at the top of our leaderboards.ts file like so:
Here we tell the component that we want to sort by the score from the leaderboard table, which will be a number.
Note that I'm using a negative value for the sortKey. This is because the aggregate component sorts in ascending order (smallest to largest), but we want to rank from largest to smallest. Using the negative value makes our intention clearer, as we'll see shortly.
Now when we insert a new score, we must also add it to the aggregate component like so:
For now we are going to assume there are no existing scores in the table. We will talk a bit later in this post about what happens if you want to use the Aggregate component with an existing table.
Now we are inserting data into our aggregate component we can use it like so:
Here's how it works: First, we use the aggregate component to find the score at our desired offset. Then we use that score in our paginate query to define our page's starting point and specify how many items we want. Finally, we look up each item in our leaderboards table and return the results.
What we're essentially doing is finding the score at a specific rank. With our leaderboard scores ordered in descending order, we can efficiently retrieve 5 (or any number of) items for display.
Simple, right? This approach highlights why the aggregate component is so valuable. Without it, fetching page 100 would require scanning through 496 rows before reaching the data we need.
This manual scanning would be not only slow but also inefficient because of Convex's transactional nature. If any of those 496 values changed—even just a player's name—it would invalidate our entire page.
The Aggregate Component cleverly stores data in a way that lets it bypass unnecessary document reads and jump directly to where you need to be.
I'm getting ahead of myself though. We'll explore HOW the Aggregate Component works later in this post.
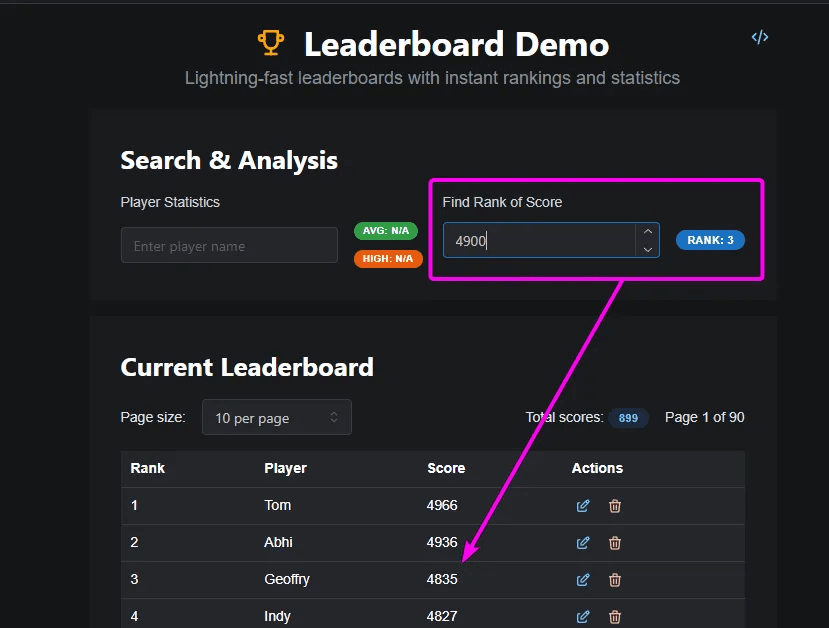
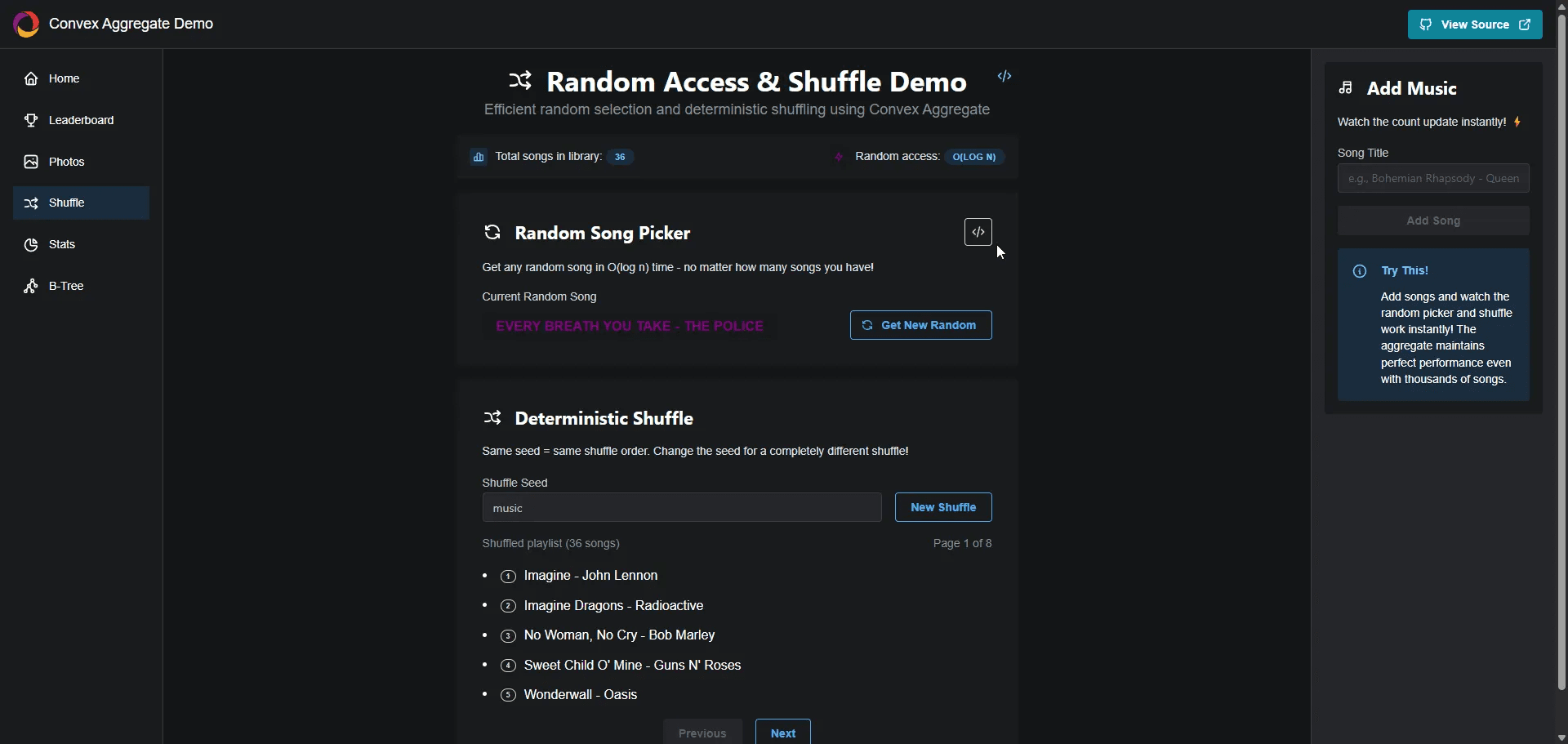
For now, let's explore another useful capability: finding a score's rank. What if instead of looking up the score at a given rank, we want to do the reverse—determine what rank a particular score would have?
We can do this easily with the indexOf function on the aggregate component. Just remember to invert our score as we did before.
When we test it out, we can enter a score and immediately see the correct rank.
Dont forget as this is Convex everything is fully reactive, so any time we add or remove scores, the rankings update instantly.
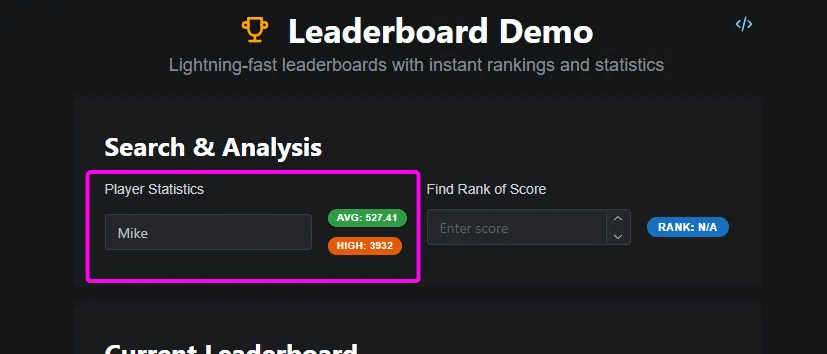
If we wanted to display statistics for a specific player such as their average or highest score we can also implement that efficiently with the aggregate component.
First, we need to modify our aggregate. Instead of using just the score as the sortKey, we're now using an array containing both the player name and score. We've also added a sumValue parameter so we can track the total points a player has earned.
Now, to calculate the average score for a player, we can do this:
1exportconst userAverageScore =query({2 args:{3 name: v.string(),4},5handler:async(ctx, args)=>{6const count =await aggregateScoreByUser.count(ctx,{7 bounds:{ prefix:[args.name]},8});9if(!count)returnnull;10const sum =await aggregateScoreByUser.sum(ctx,{11 bounds:{ prefix:[args.name]},12});13return sum / count;14},15});16
Here we use the aggregate to count the scores belonging to this player and sum their scores, then simply return the average.
Don't forget that because of how the Aggregate stores these values, this lookup is super fast and efficient, it doesn't have to scan all the rows.
If we want to show the highest score a user has ever achieved, we can use the max function
Interestingly, we need to access the value through the sumValue property.
If we take this for a spin now, we can enter my name, it works! We can see my average and highest score. Just like before we can add a new score with my name and these values instantly update.
Other Demos
Now that we understand the basics, what else can we do with the Aggregate Component?
If your data has clear categories (like photo albums in this demo), you can use namespacing to efficiently segregate your data. This approach reduces the number of reads and writes when working with a specific namespace.
To do this, we need to "null" our sortKey. This causes the aggregate component to order values in its structure by the document ID, which is effectively a random GUID.
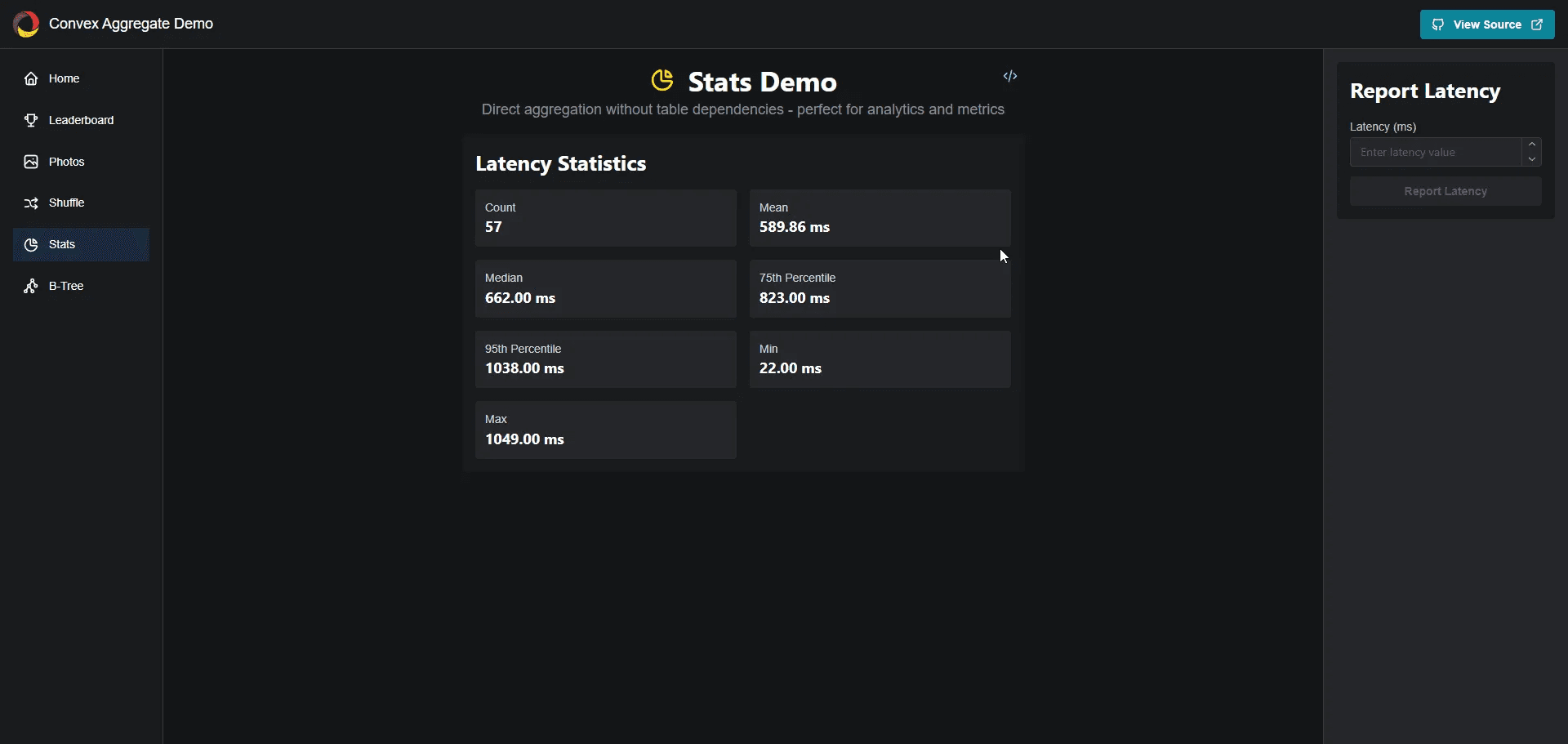
1exportconst getStats =query({2 args:{},3handler:async(ctx)=>{4const count =await stats.count(ctx);5if(count ===0)returnnull;67const mean =(await stats.sum(ctx))/ count;8const median =(await stats.at(ctx,Math.floor(count /2))).key;9const p75 =(await stats.at(ctx,Math.floor(count *0.75))).key;10const p95 =(await stats.at(ctx,Math.floor(count *0.95))).key;11const min =(await stats.min(ctx))!.key;12const max =(await stats.max(ctx))!.key;13return{14 count,15 mean,16 median,17 p75,18 p95,19 max,20 min,21};22},23});24
Retrieving data from it is just like using the TableAggregate.
We can perform the same operations like count, sum, min, max and so on.
Potential Issues & Triggers
Okay before we pop the hood of the aggregate component and have a look at how it does its magic lets just quickly talk about an issue with the Aggregate Component.
You may have noticed an operational issue with the Aggregate component. Whenever we add a document to a table like this leaderboard score, we must also remember to insert it into the aggregate.
And the same goes for when we remove a score like this.
Or if we update a score like this
1exportconst updateScore =mutation({2 args:{3 id: v.id("leaderboard"),4 name: v.string(),5 score: v.number(),6},7handler:async(ctx, args)=>{8const oldDoc =await ctx.db.get("leaderboard", args.id);9if(!oldDoc)10thrownewError(`Score with id '${args.id}' could not be found`);1112await ctx.db.patch("leaderboard", args.id,{13 name: args.name,14 score: args.score,15});1617const newDoc =await ctx.db.get("leaderboard", args.id);18if(!newDoc)19thrownewError(`Updated score with id '${args.id}' could not be found`);2021// Update both aggregates with the old and new documents22await aggregateByScore.replace(ctx, oldDoc, newDoc);23await aggregateScoreByUser.replace(ctx, oldDoc, newDoc);24},25});26
we need to remember to update the aggregates because the values being changed could affect the aggregate.
This required coupling is necessary but potentially error-prone. If you or a team member forgets to include the aggregate lines somewhere, you can easily end up with aggregates that are out of sync or corrupted.
Fortunately, there's a solution to this issue in the form of triggers and custom functions.
We can now replace our mutations with this mutationWithTriggers and remove all those places where we manually insert or update our aggregates. Our triggers will automatically update the aggregates whenever the leaderboard changes, which greatly simplifies the logic in our functions.
Very nice!
Dashboard + Triggers Issue
While we're discussing issues with the Aggregate Component, I want to point out another potential pitfall you should be aware of.
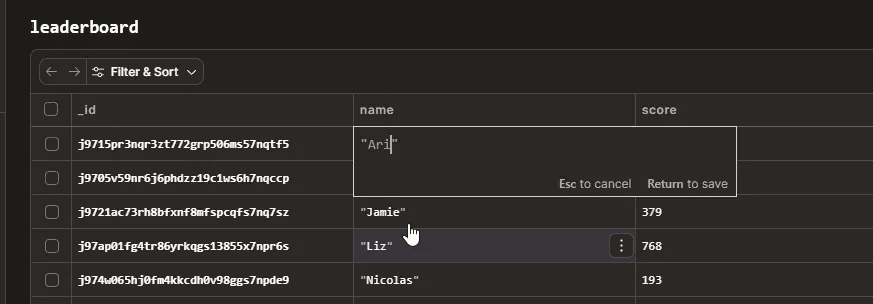
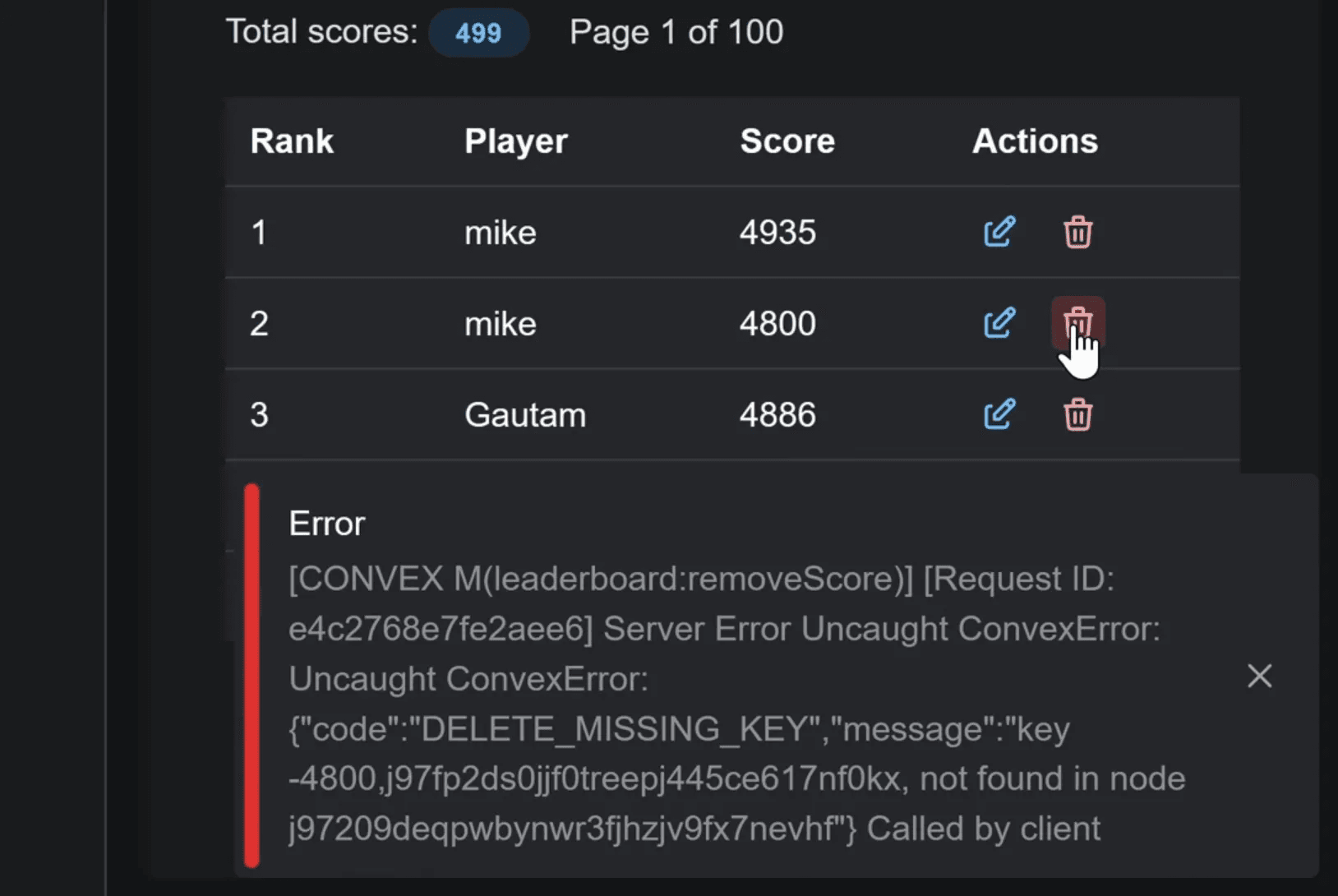
As you probably know, you can open the Convex dashboard for any project, go to the data tab, and change a value, like a player's name, and it instantly updated in the leaderboard.
But now if we try and delete this row from in the UI:
Boom! Error!
The problem is that dashboard changes don't trigger your code, so the triggers aren't fired. This leaves your aggregate corrupted because the keys no longer match.
Unfortunately, there's no easy workaround for this issue right now other than being extremely careful with dashboard edits.
We've been discussing potential platform-level triggers internally, but they're still quite a way off.
Existing Data & Migrations
By now, you should have a good understanding of what the aggregate component is and how to use it in your new project.
But what if you already have existing data? Can you incorporate it into your project?
By pulling in the migrations component, we can create a migration that will iterate over every row in the leaderboard table and populate our aggregates in a safe way. Then we can run it directly from the dashboard or CLI:
1npx convex run migrations:backfillAggregatesMigration
2
Okay now if you're anything like me, at this point you're wondering how this wizardry is performed.
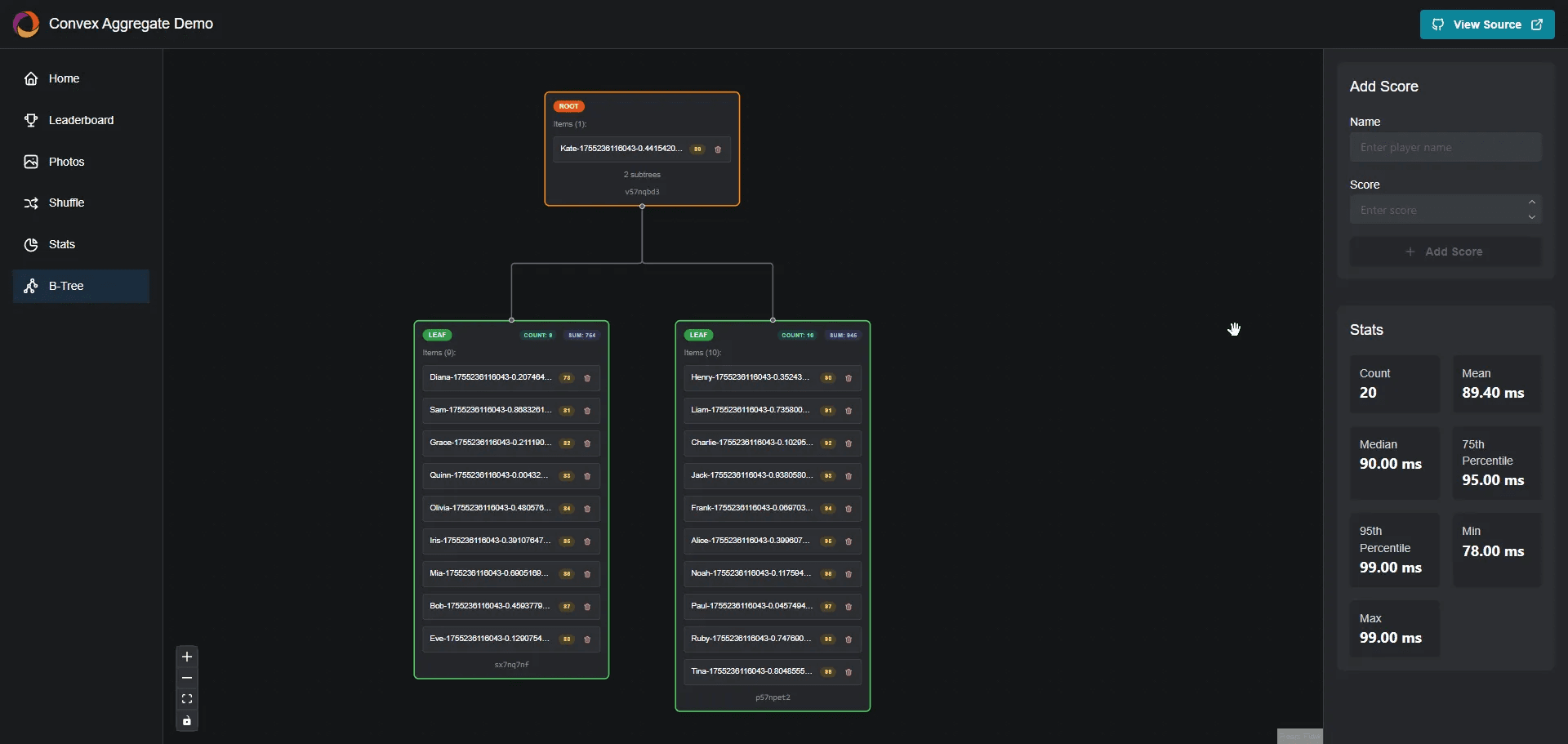
Well, I started to go deep on this topic and began putting together a whole demo that shows how the Btree evolves over time as you add and remove items.
But the hours started turning into days so I reluctantly decided to park this little demo for now.
If you would like to see me dive a bit deeper into this in another video then come find me on Discord or X :)
The TL;DR is that the aggregate component works by storing data in a highly efficient data structure called a Balanced Search Tree or BTree. This is the same type of data structure typically used in database indices like those in Postgres or MySQL.
By constructing a BTree and storing it in the Convex database, you can transform reads from an O(N) operation to an O(log(N)) operation.
We're essentially building our own custom index that we can control.
Final Thoughts
Alright, now I promised a spicy take at the start so here it is.
Convex chose not to include aggregates in their core offering and instead offloaded it into user-land or components like this one for some very good reasons that I elaborate on in my dedicated video on the topic.
By making users handle the aggregation of their data themselves rather than leaving it up to the whims of the almighty Query Planner, you end up with more predictable performance and costs.
On the other hand, it's admittedly a pain to manage simple counts and other basic aggregations yourself, whether manually via code or through the Aggregate component.
Unless you use triggers, it's very easy to forget to update the Aggregate component when you make a mutation to the underlying data, leaving your aggregate in a corrupted state that you then have to migrate your way out of.
Or worse, if you or one of your teammates changes a value in the dashboard as I showed previously, this leaves your aggregate in a corrupted state.
These kinds of easy-to-make mistakes are, in my opinion, antithetical to the typical ethos of "no footguns" found in the rest of Convex.
So I do wonder if there's something more Convex should do here, perhaps bringing some of these aggregations to the platform level, or maybe putting more work into platform-level triggers?
Well anyways I think we will have to leave that discussion for another day!
All gas, no breakages
Convex is the reactive backend platform that keeps up with you and your agents. Database, functions, workflow, sync, search, file storage, and more. All TypeScript, zero glue.


 … the people have spoken.
… the people have spoken.