I am migrating away from convex. If you need to select account or select all ids, then you will literally select star and make your count. This was a comment from Theo's latest epic video on databases and convex. The video was great, by the way, so you should totally check that out. But while I was perusing through the comments, this one really caught my eye as it has a kind of a good point. Why doesn't convex support select or count? To show you what I mean, let's take a look at this really simple schema. So here we have a convex schema with two tables. Small table just has a single value small value and it's only going to have a small string in it. And then we have big table that also has a small value and a big value which is going to contain a really large string like 100 kilobytes or so. Now I've gone ahead and populated both tables with a bit of data. So now we can see that both tables have got a thousand rows in them and the small value is just a small string with some random number in it. And then big value is this big long random string here. Right now let's say we want to do a query that is like the SQL equivalent of select star from small table. Um this is how you would go about it in convex. And then kind of this is the same thing for the big table. So let's take these functions for a spin in the dashboard. So if we go to the functions tab, we can then select our select star from small table function uh and run it and it takes roughly 900 milliseconds or so. Then if I run the select star from big table function, I can run it a couple of times. It takes roughly two to 3 secondsish. This makes sense, right? Cuz well the big table is bigger, so it's going to take longer to fetch that data. Oh, and just quickly, if we just hop back to the the code a sec, the keen eyed amongst you might be wondering why I'm doing these queries inside of a mutation rather than a convex query where they probably should be. Well, it's because of two reasons really. So, the first one is caching. And spoiler alert, this is going to come up in a bit in this video, but you see, Convex's um queries are automatically cached. So, as long as none of the inputs change to a query, then it doesn't need to rerun it. I can show you what I mean here by if I just create a query and I hop over to the dashboard and then I go to the logs tab and now I select my query then it's going to run it but then I have no way to run it again. So this is the second reason why I'm using mutation because when I do mutation I actually get a button here that can run with a time output. Um so when I'm doing a query though for a quick way to test it is I can just change the function in the dropown here and then go back to it and select it again and rerun it again. But we will see in the logs that it's going to say the word cached in there. That's because it didn't need to rerun the body of this query because nothing changed about the inputs. So that means this time round, the second time around, we're going to get an almost instantaneous response rather than having to wait for convex to do its query. Right? So I guess now the question is how do we go about doing a select then? Um, if I'm looking at the big table, for example, how can I make it so I'm just want to pull out the small value from the big table and just ignore this big value? Well, if I just press dot here on the query, um, we can see that there's no select or project or anything like that. But what we can do is because convex queries and mutations are effectively like stored procedures, we can actually just do a map over the value inside of the mutation itself. All right, so let's try this one out now. All right. Well, that certainly seems faster, like about 600 millisecondsish compared to the 2 to 3 seconds from before. But looks can be deceiving. There's a lot going on when we press the button here. So let's have a quick look at a diagram. So, I have my browser down here in Australia. Actually, should just turn this upside down because, you know, Australians live in upside down land. Anyway, when I press the button, my browser that is running the Convex dashboard is going to make a request to the Convex back end. So, Convex is then going to spin up a small little VM to run our function. It's called a VA isolate. you don't need to worry about that really. But um what it's actually then going to do is it's going to make a request to the underlying storage or the database um and return the data back to the query which then is eventually going to return it back to us in down here in the dashboard. So now the comx dashboard is going to record how long that whole roundtrip time which is like you know 600 millonds in this case which makes sense is that's kind of what you usually want. um you want to time how long the user is going to experience the roundtrip time. But for us testing purposes here, this is not actually what we want. What we're interested in really is how long it takes for this function to go to the underlying storage and back again. So what we're interested in is is this going to be faster than doing our normal select all um version of the query. Is Convex doing something funky under the cover that optimizes the query because it knows we won't need the big value? Well, unfortunately, Convex's dashboard doesn't actually expose this information to us. But all is not lost because we can go into the integrations tab in the Convex dashboard and enable one of these log providers to get more detailed information about each call. So, I'm going to hook up Axiom. Um, if you're not familiar with Axiom, it's an incredible log streaming service that I adore and I've used extensively in the past for my game Battle Tabs. I mean, just check out this pricing. 25 gig per month of free storage and 500 GB of bandwidth is just insane. To put that in perspective on Battle Tabs, we're sending millions upon millions of log rows every month and we're just barely barely scratching our usage. It's unbelievable. Anyways, so once I've hooked up Axiom to our convex back end, um we can try our select star from small table function again and hop back into Axium and check out our log line in our stream here. Right, so we've got a lot more information here now. So we can see that our deployment name is here. Um it's got our function and a bunch of other stuff. But what we're interested in for right now is this data.execution time ms and data do usage database readbytes. So I'm just going to grab both of those and pop them into this table. Right now let's do the same for the other functions. All right. Interesting. So we can see that when we select just the small value from the big table and return it that it is indeed faster. But the question is how much of that time is spent serializing the data when we return back from the function versus what we're actually saving on the query. H unfortunately it's kind of impossible to tell that from this data. But what we can say though is that the number of bytes that is read from the underlying database is the same in both scenarios. So if the data that is read is the same in both scenarios then we know that convex must not be doing some clever selecting of only the data required from the underlying database. So I think in the end that kind of validates what source code deleted was saying. You must select that entire row each time and you charged for the bandwidth usage and convex does indeed price its database bandwidth usage based upon this. Don't forget though in a real life scenario most of the time we're going to be doing these queries inside of a convex query function and therefore as long as the inputs don't change we're our value is going to get cached and convex doesn't charge for cached query database reads because there was no database that was read. So in real life probably the pricing is actually going to be a lot cheaper than you think because most of the time won't actually be hitting the database the underlying database. But back to the original question then why doesn't convex provide a select? I don't think it's actually an issue of convex not wanting to do something like this. It's more of a limitation around convex being both a relational and document database. You see other row based databases like Postgress benefit from some very specific optimizations because they have fixed columns. So for example in Postgress if a field gets too large um I think it's about 2 kilobytes then what it actually does is it replaces that value in the row with a special pointer to a place called the oversized attribute storage technique or toast area. So that means when you want to read uh a number of rows that might include a big value, it first has to do a lookup into this area to grab the entire row which is quite an expensive operation to do. So the optimization that select does in Postgress is if you only select the small value then it's going to allow us to skip that expensive lookup into the toast area. And this is something that Convex doesn't do because it's actually storing the entire document to its underlying storage, not columns. Oh, and things start to get super messy when we start talking about indices on both databases. So, let's not go there right now. The key thing to know here though is that while it might be possible for convex to do some sort of toastlike process internally, it doesn't actually want to for a more philosophical reason. That brings us to our second question. Why doesn't convex support count? If we return to source code deleters comment and take a look at the next thing they said. If you need to select account or select all ids, you will literally select star then make your count. And they are quite right. If we hop back into the code for a sec and try putting a dot again here, we'll see that there's no count function. So the only way to count our rows um from a query is as the author suggested to return back all our rows and then count them, which means reading a lot of extra data unnecessarily. So again, why doesn't convex support count? Postgress, MongoDB, Firebase all have these count primitives. So why not convex? So here we get down to it. What does the lack of select and the lack of count have in common? You see, both operations sound cheap, but actually usually require reading a lot of data. So count has to touch or at least index scan every single matching row and it has to do this on both relational databases and on convex. So in comics as well this means a lot of extra documents read which is going to blow out the cache and every single write and also cost you a whole heap of extra bandwidth and select would only be cheap if convex could skip reading those big fields from its internal storage layer. But convex stores the entire JSON document, not just column chunks like in Postgress or other relational databases. So it has to read the full blob back then throw away what you don't need. But the issue is is like that select statement can have unexpected performance changes as you scale up. If you were to put a value inside of that big value that is less than 2 kilobytes, then you'll get a very fast read. But if you put a big value in there, then it could be a slow read. So sometimes it it could be fast, sometimes it can be slow. It's kind of inconsistent. So convex philosophy is no pretend cheap primitives. Instead, you model what you really need and thus you get consistent performance and pricing as you would expect. So could convex theoretically add these? Sure, probably. But the easy API would mask the real costs and thrash the cache and create unpredictable performance. Convex prefers explicit modeling over magic that SQL and its underlying query planner present. Okay, so finally then what are the solutions in convex land to these two issues? So firstly for the select issue what I personally would probably do is split up my data so that I have my big values stored in another table and then I would only pull in that data when I need to and then I might write a query that would look something a bit like this. So if you really think about it, what we're doing here is kind of what to Postgress does for you under the covers, which with its toast, we're just pulling it in manually when we want to and we get our explicit understanding of how the performance implications of doing this. As for count, what I would probably do is I would keep a count somewhere in my database. So when I change something in a mutation, I increment or decrement that count at the same time as changing the the data. So like here for example we have a mutation liking a post. We record the like as a row in the database but at the same time we also record the number of likes as a count on the post object. That way when we read posts we don't have to query the likes table at the same time to find out how many likes a given post has. It's just right there on the post. But for more complex scenarios um you can check out the convex aggregate component that's designed for this exact purpose really. It not only counts, sums, does maxes, bounds based, ranking, things like that. It's kind of perfect for like leaderboards or other things like that. By the way, make sure you are subscribed because I'm probably going to be doing a video on this component very soon as it's really powerful. Oh, and one last little thing I learned from a colleague, but um don't tell anybody is there is actually a cheeky little uh count for tables in convex and that's how the Convex dashboard is able to show this number. It's not documented and not officially visible through the types and TypeScript, but it's there. Um, I just wouldn't use it in production if I was you, unless you wanted your app to break at some point without warning. All righty ho. Well, that's about it for me for today. I hope you enjoyed this video, and if you did, don't forget to drop me a like. And if you have any questions or comments, then please do leave them down below. I read every single one. And if you enjoyed this video, then you might want to check out this one. It's another Convex internals video that I did where I dove deep down into how the Convex codegen process works. Anyway, until next time, thanks for watching. Cheerio.
The video was great by the way you should totally check it out, but while I was scrolling through the comments this comment really caught my eye as it has a good point.
Why DOESNT Convex provide a “SELECT” or a “COUNT”?
To show you what I mean lets take a look at this really simple schema.
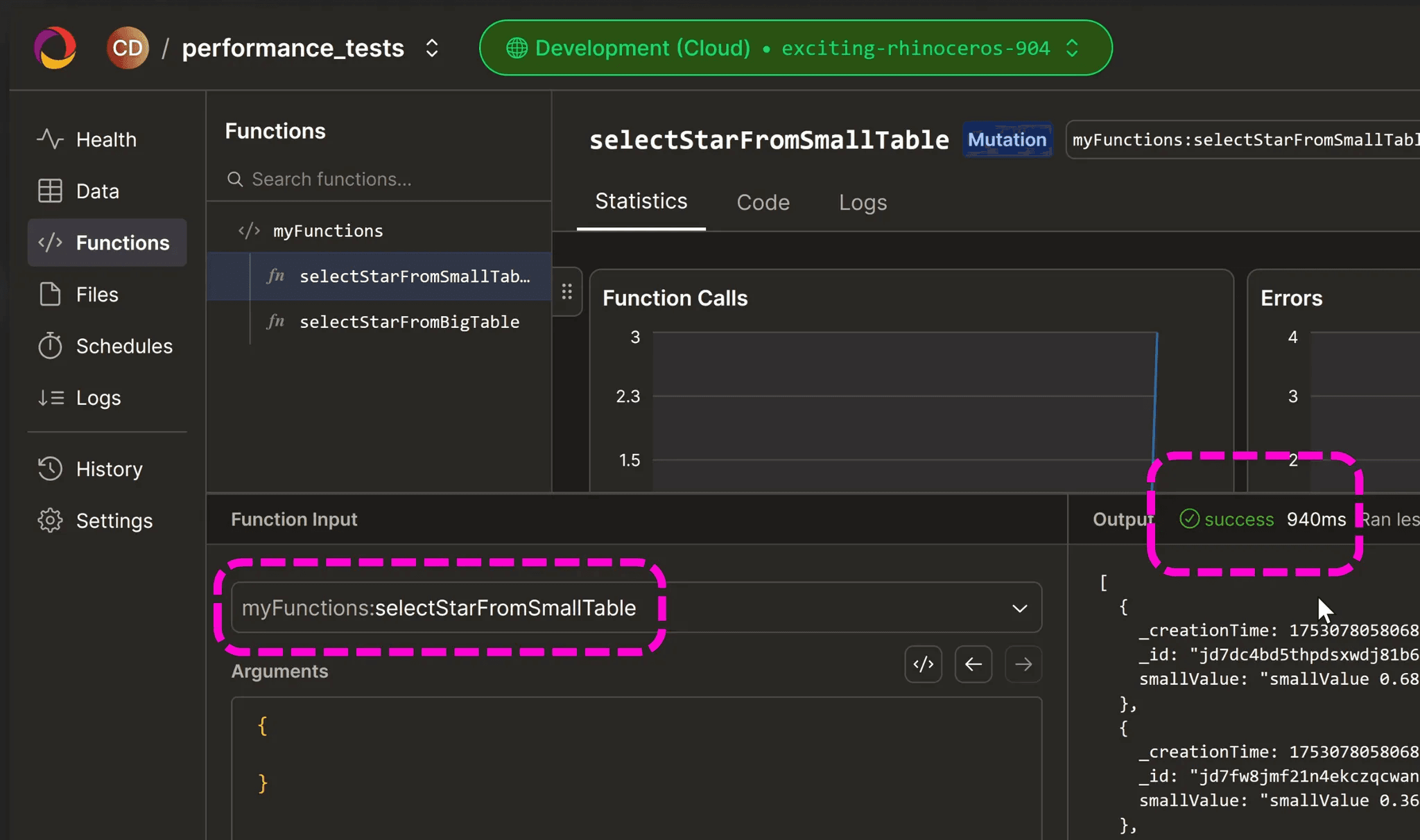
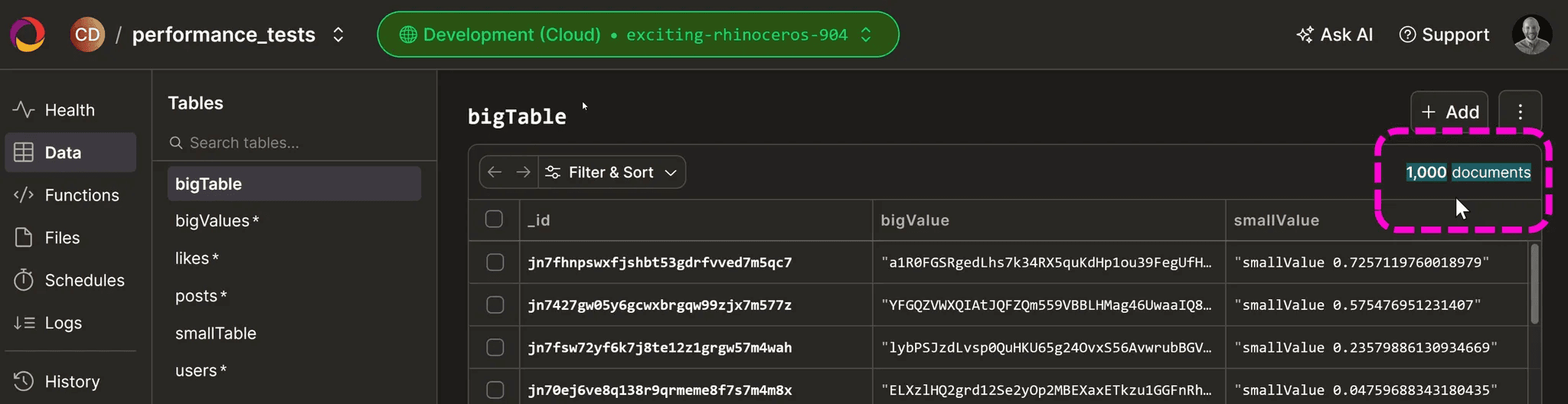
If we go to the functions tab in the Convex Dashboard we can run the function which turns out to be about 900ms.
If I do the same for the bigTable it takes 2-3 seconds. Makes sense right? as the bigTable is.. well bigger so its going to take longer to fetch that data.
You might be wondering why im doing these queries in a mutation rather than a Convex query.
Well you see, Convex automatically cache’s queries so as long as none of the inputs change then it doesnt need to re-run it, so if I create this query instead
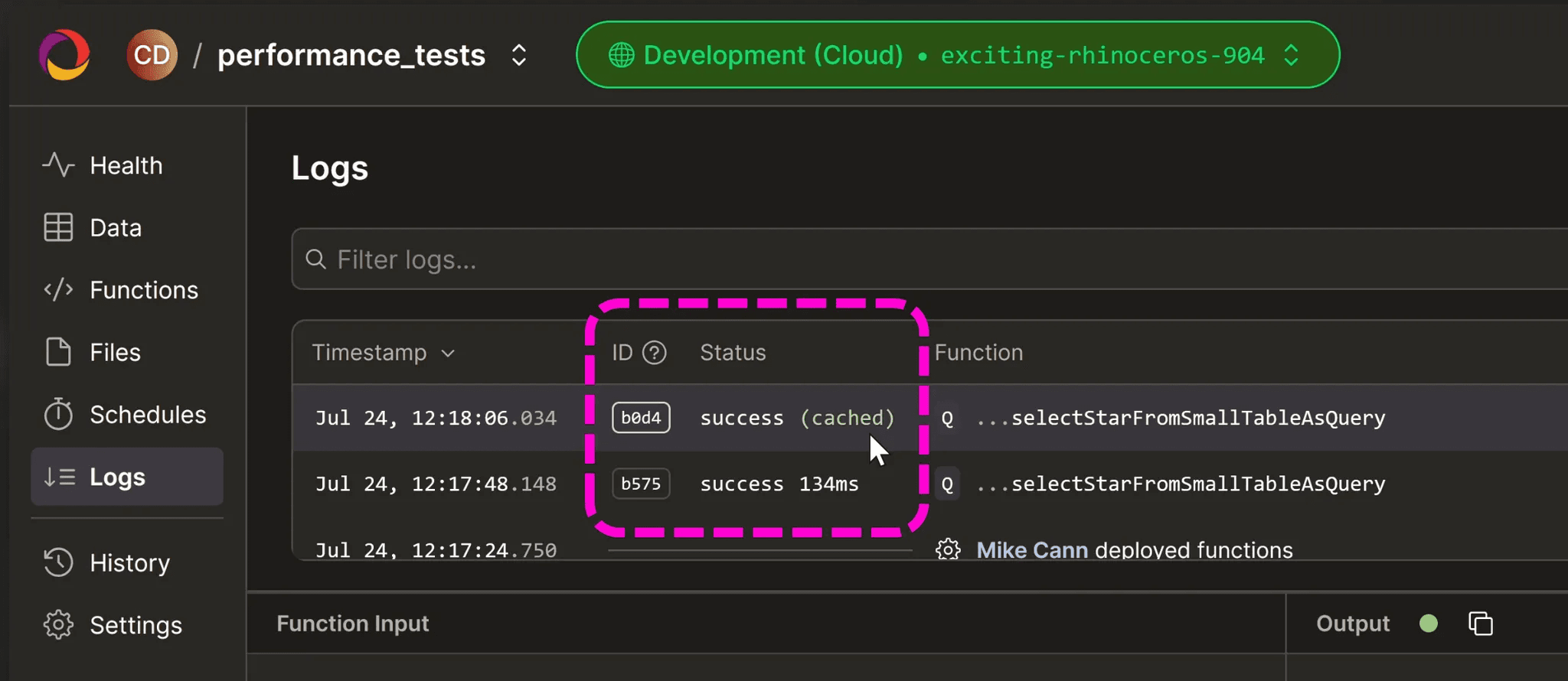
Then I hop open the dashboard, go to the Logs tab and run this query a couple of times by selecting it from the dropdown then we will see this:
You can see the first time its run then we get a success, then subsequent times, we get a cached status and a near-instant response.
Right, now the question is how do we go about doing a SELECT in Convex? If I'm looking at the bigTable and I'm not interested in bigValue can I make it so I just select the smallValue?
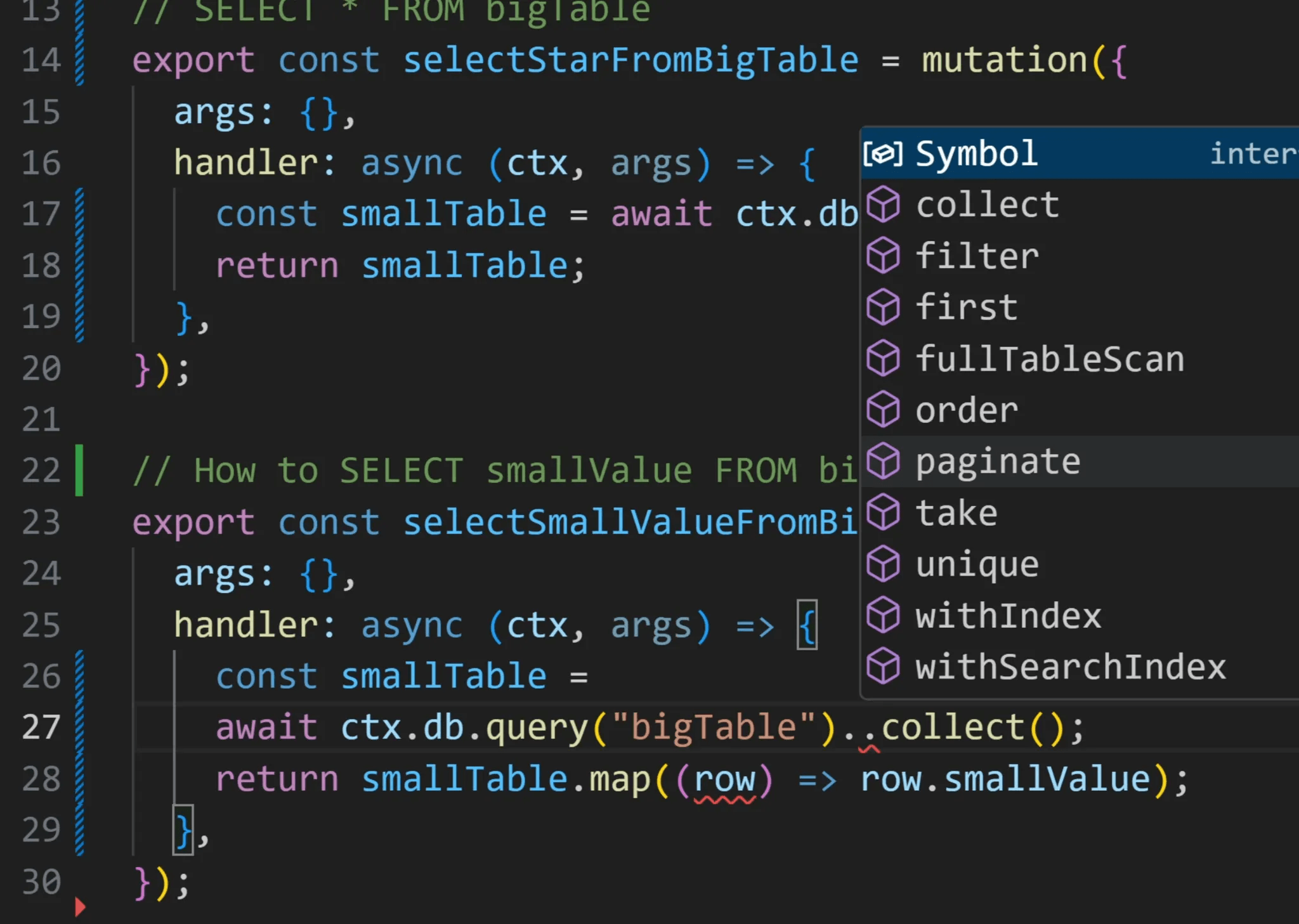
Well if we interrogate our query in the IDE we can see that there is no select function.
But what we can do is just map over the results and just grab the one value we want here and return it like so:
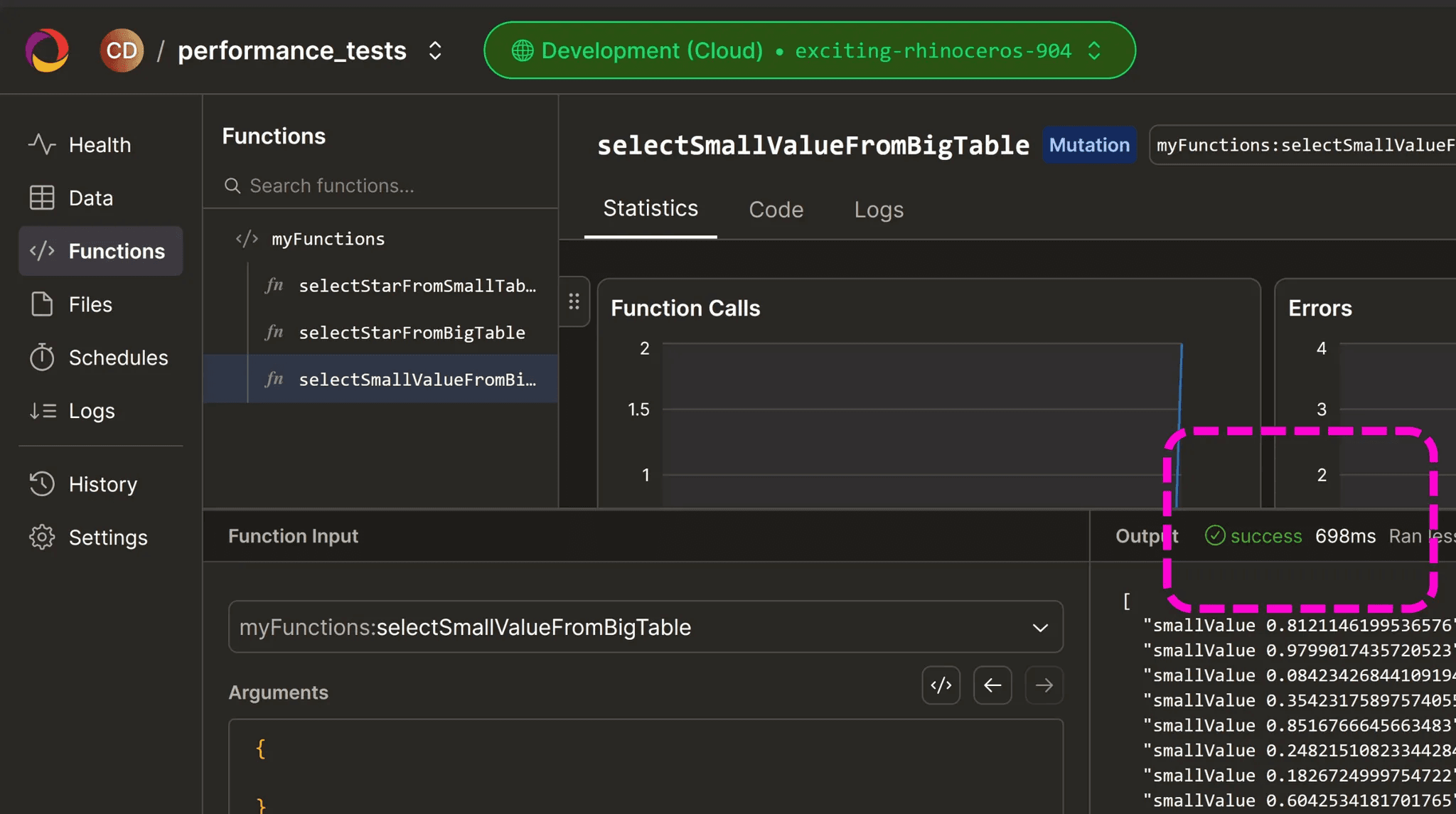
If we now run that in the dashboard this is what we get:
Okay well that certainly seems faster! 698 milliseconds compared to the 2-3 seconds before.
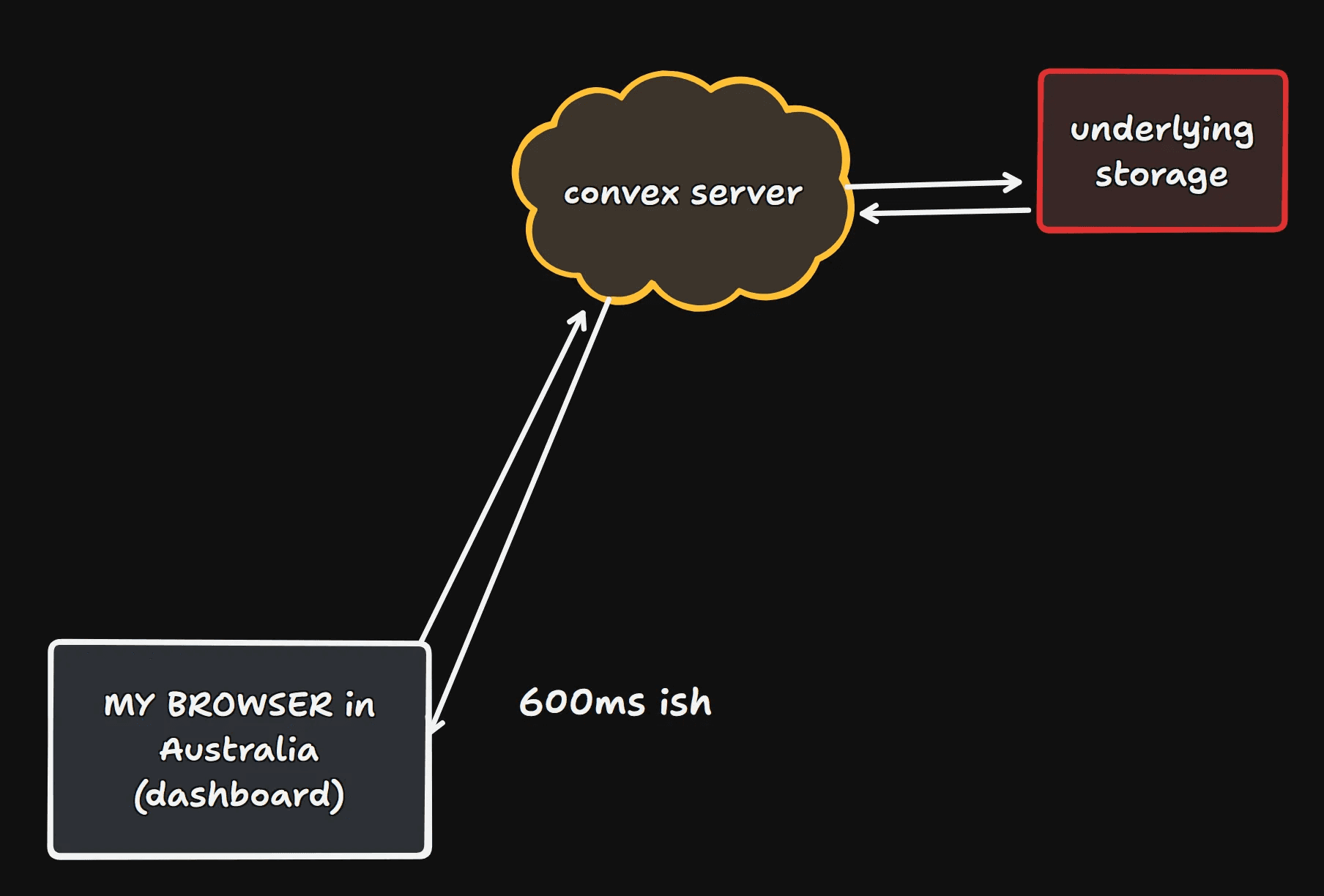
But looks can be deceiving as there is a lot of things going on here when we press this button, lets take a look at a diagram:
When I press the button, my browser that is running the Convex dashboard is going to make a request to the convex backend.
Convex is going to spin up a little v8 isolate, which is then going to make our query.
This is going to go out to the underlying storage / database and return the result back to the convex server, which is then going to eventually return it back to the user.
So now the Convex dashboard is going to record that whole time as 698ms which makes sense as this is usually what we want, the time the user of your app is likely going to experience.
But for our purposes what we are really interested in is how long it takes to go from the underlying storage to the convex server.
Is this actually faster because of our mapping in the query?
1exportconst selectSmallValueFromBigTable =mutation({2args:{},3handler:async(ctx, args)=>{4const bigTable =await ctx.db.query("bigTable").collect();5return bigTable.map((row)=> row.smallValue);// Is this making things faster?6},7});8
Is convex doing something funky under the covers that optimizes this query because it knows we wont need the bigValue?
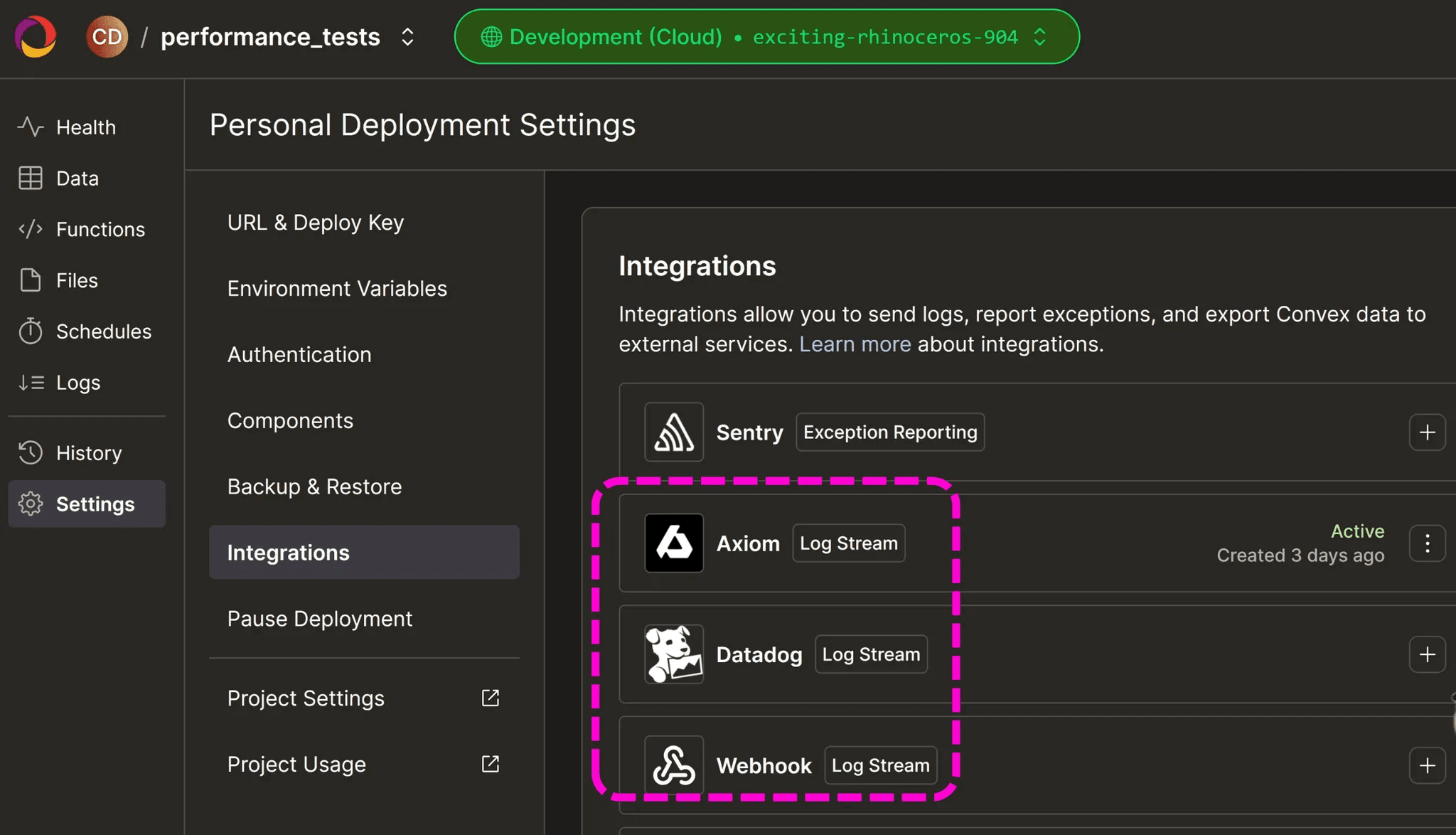
Well unfortunately the Convex dashboard doesn't expose this information to us, but all is not lost as we can go into this integrations tab an enable one of these Log Stream providers to get more detailed info about each call.
If you aren’t familiar with Axiom its an incredible log streaming and analysis service that I adore and have used extensively in the past for my game BattleTabs.
Once I have Axiom hooked up to our Convex backend I can try our selectStartFromSmallTable function again and hop back to Axiom and checkout the log line.
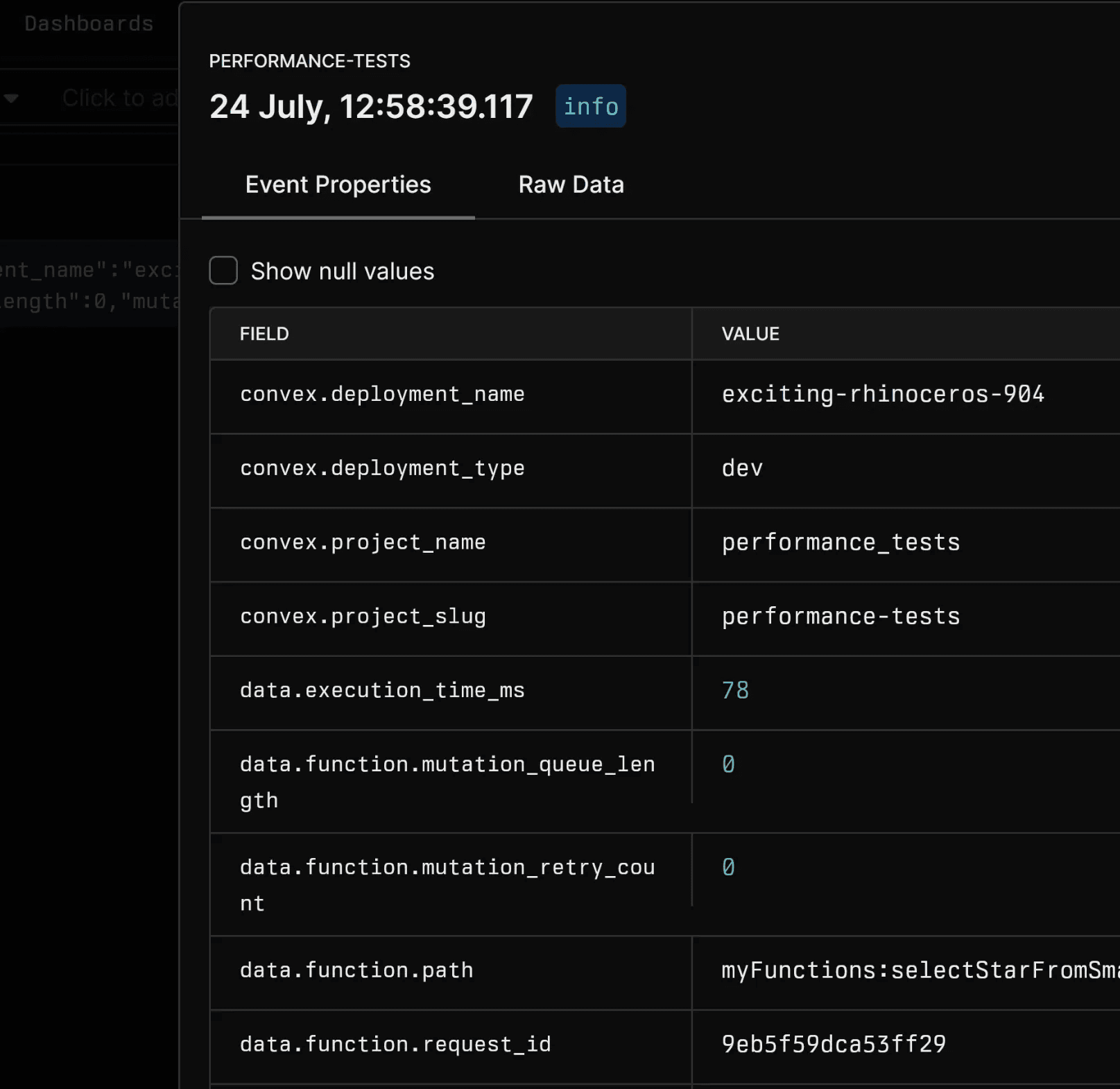
Right so we have a lot more info in here now. We can see our deployment name, our function we called and a bunch of other stuff.
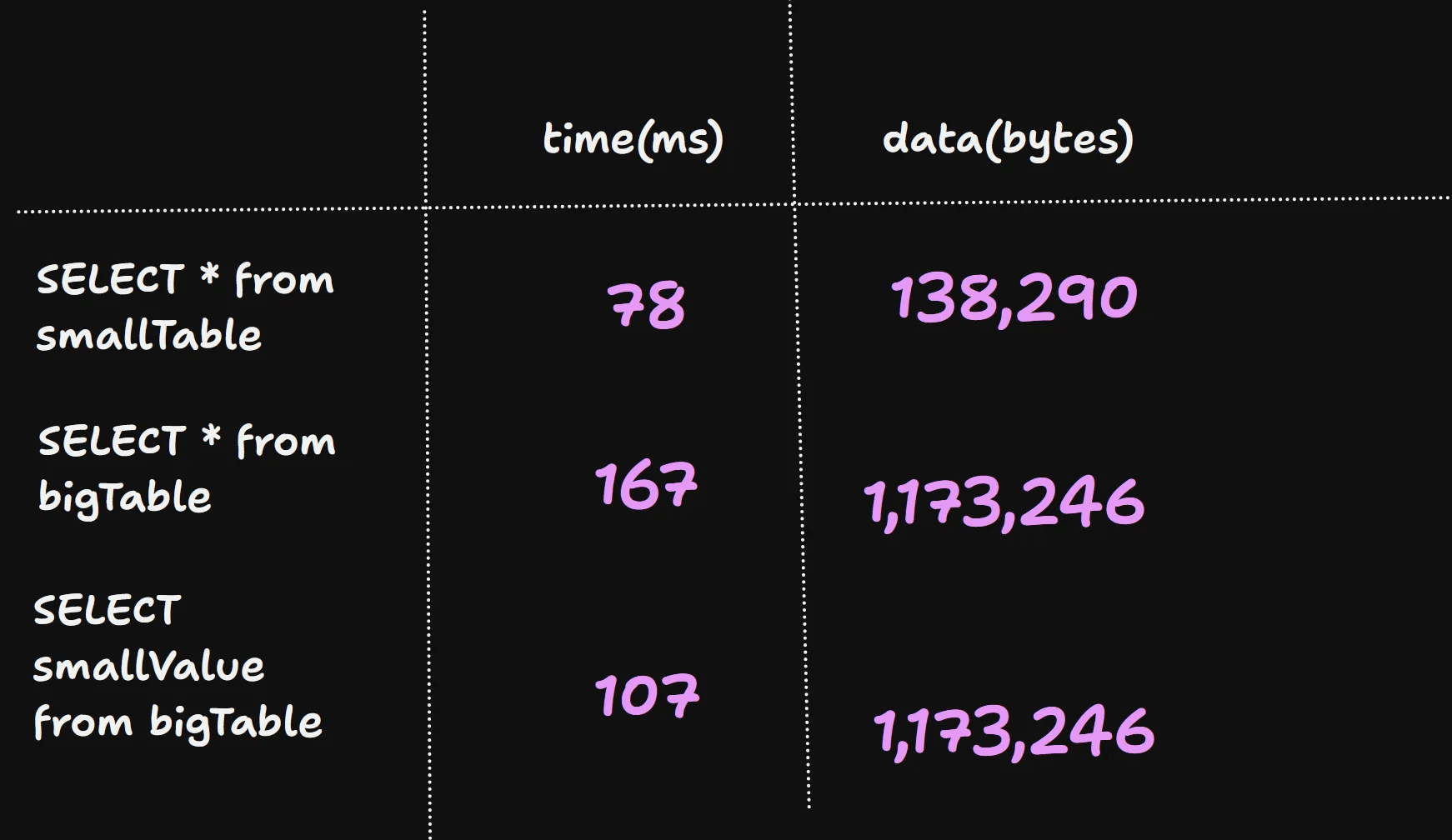
What we are interested in right now is this data.execution_time_ms and data.usage.database_read_bytes. Im just going to grab both of those and pop them into this table and do that for the other functions:
So interestingly we can see that when we “select” just the smallValue from the bigTable and return that it is indeed faster. The question is, how much of that is time spent serializing the data when we return from the function tho?
Unfortunately this is impossible to tell from this data but what we can say tho is that the number of data that is read from the underling database is the same in both scenarios.
So if the data read is the same in both scenarios then we know that convex must NOT be intelligently selecting only the data required.
So that then validates what SourceCodeDeleted is saying:
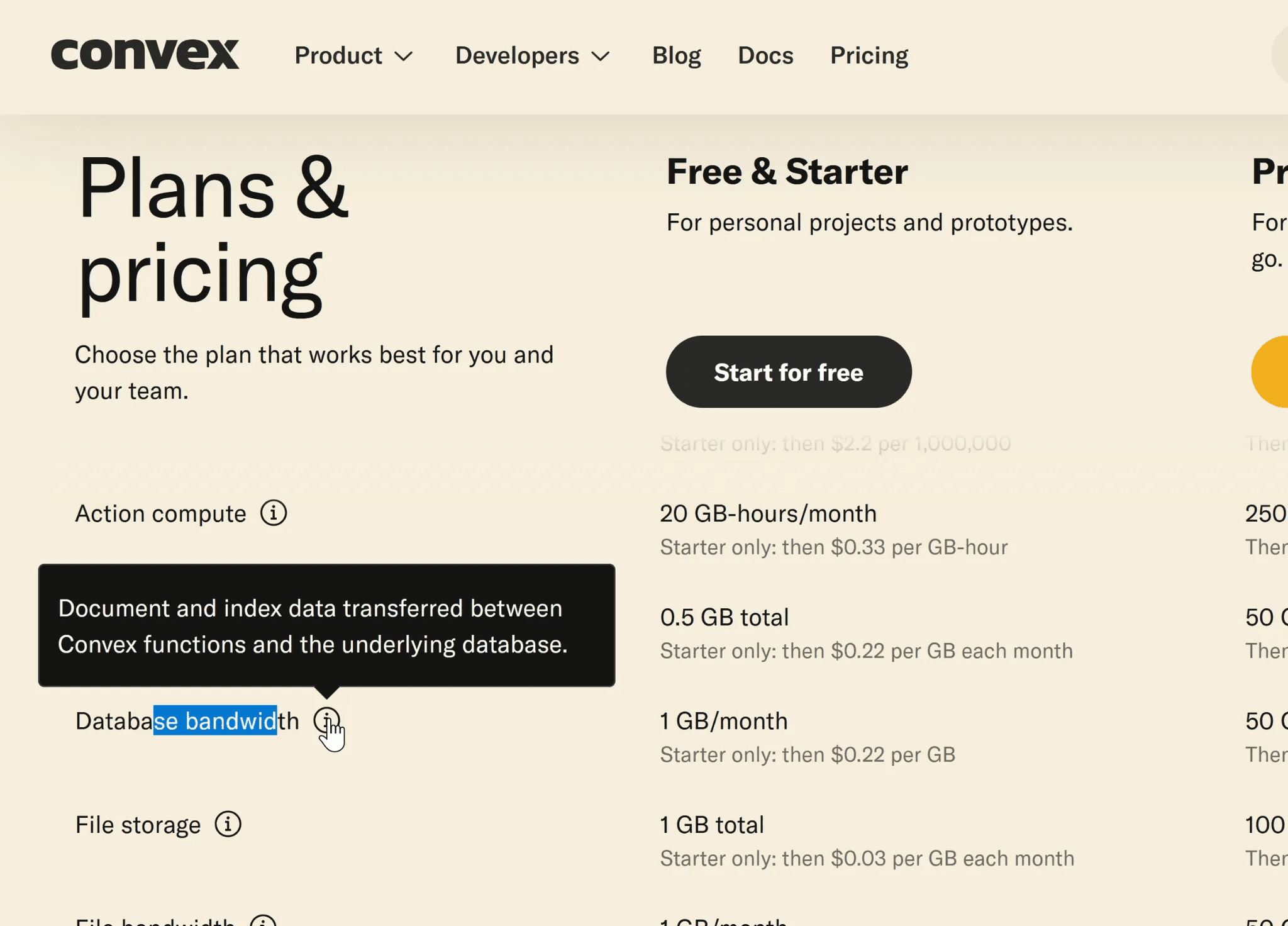
And convex does indeed price its database bandwidth based on this.
So then back to the question question then.
Why doesn't Convex provide a SELECT?
I don't think the issue is one of not wanting to and more of a limitation around that Convex is both a relational AND a document database.
Other row-based databases like Postgres benefit from some specific optimizations because they have fixed columns.
So in Postgres if a field value gets too large (over 2kb) then it actually replaces the value in the row with a pointer to a special place called “The Oversized Attribute Storage Technique” or TOAST table.
So that means that when you want to read a number of rows that includes the bigValue it has to do a lookup into this other area first to grab the entire row. So the optimization that it performs with SELECT “smallValue” is to allow it to skip this expensive lookup and retrieval. This is something Convex doesn't do because its actually storing documents to its underlying storage and not columns.
Oh and things start to get super messy when we start talking about indices on both databases so lets not go into that right now.
The key things to know here is that although it might be possible for Convex to do some sort of TOAST like process internally like Postgres, it doesn't want to for another more philosophical reason that finally brings us to our second question.
Why doesn't Convex support COUNT?
If we return to SourceCodeDeleted’s comment and take a look at the next thing they said
They are quite right, Convex queries do not have a count() function
So the only way to count our rows from a query is as the author suggests, to return back all the rows you want then count them. So again, why cant Convex support COUNT? Postgres, MongoFB and Firebase have count primitives.
So here we get down to it.
What does the lack of SELECT and the lack of COUNT have in common?
Both operations sound cheap but usually require reading a lot of data.
COUNT has to touch (or at least index-scan) every matching row. In Convex’s world that means lots of documents read, which blows the cache on every write and costs you in bandwidth.
SELECT would only be cheap if Convex could skip reading the big fields in storage. But Convex stores whole JSON docs, not column chunks so it still has to read the full blob, then throw away what you didn’t ask for.
So Convex’s philosophy is: “no pretend-cheap primitives”. Instead, you model what you really need and you get consistent performance and pricing as you expect.
So could Convex add these?
Sure probably, but the ‘easy’ API would mask real costs, thrash the cache and create unpredictable performance. Convex prefers explicit modeling over magic that SQL and its underlying query planner present.
Solutions
Okay so finally then what are the solutions to these two issues?
So firstly for the “select" issue what I would probably do is split my data up such that I have my bigValues stored in another table then I would only pull in that data when I need to.
So really if you think about it, this is exactly what Postgres is doing for us with its TOAST. This would dramatically reduce the amount of data that we have to read each query and thus reduce our overall database costs.
As for COUNT well as with SELECT Convex kind of leaves that up to you but what I would probably do is either manually keep a count somewhere in my database so when I change something in a mutation I increment or decrement a count.
Like here for example we have a mutation for “liking” a post:
We record the like as a row in the database but at the same time we also record the number of likes this post has as a count on the post. That way when we read posts we don't have to query the likes table to find out how many likes a given post has.
For more complex scenarios you can checkout the Convex Aggregate Component that that is designed for this exact purpose. Its got not only counts but sums, maxes and bounds based rankings perfect for things like leaderboards.
Oh and one last thing, I learnt this from a colleague (but don't tell anyone) there is actually a cheeky global count for tables in Convex, that's how the Convex dashboard is able to show this number.
Its not documented and not officially visible through the types but its there. Buuuut I wouldn't use it in production if I were you, unless you wanted your app to break at one point without warning!
Conclusion
Alright well that's about it for me for today. If you have any questions or comments then please do come find me on Discord im always open to discuss some more!
Until next time thanks for reading!
Cheerio!
All gas, no breakages
Convex is the reactive backend platform that keeps up with you and your agents. Database, functions, workflow, sync, search, file storage, and more. All TypeScript, zero glue.