Don't tell my boss, but I just spent the last two days working on a video that shows how easy it is to move away from convex. Lock in is something that has always concerned me and I think you guys too, judging by this comment on Theo's latest video. It's a pretty hard lock in. You either self-host the entire thing or you switch to the modular pieces. As you said, these functions are transactions and it matches queries. you cannot easily replicate this behavior and that's the lock in the behaviors and the mindset. So that sent me down the route of finding out how hard actually would it be to migrate away from convex. Now as this author mentioned convex is open- source and as such comes with the ability to self-host the entire backend including the dashboard yourself. There's full docs on it over at GitHub and I think this certainly would be the quickest and easiest way of going about migrating away from the lockin of convex cloud. But I think that would probably be defeating the purpose for many people. I presume that if you're afraid of lockin like the author mentioned then you are probably looking to move to a different database and set of technologies altogether. So with that in mind, once you've dropped me a like and subscribe, let's get into and find out what it would be involved with replacing our convex code with something else. All right, so we have this very simple react convex app here. Um, it might be familiar to you if you have ever started a convex project with V template using npm create before. You can click on this button which add numbers to the array here. It's pretty simple. So let's have a look at the code for this. So we have this very simple schema here with just one table numbers and with just one field value. And let's have a look at our convex functions here. So as you're probably no doubt aware, convex has three kinds of functions. Queries, mutations, and actions. Queries and mutations can directly access the database and are transactional. Actions are not. So I think the first step in thinking about how to move away from convex would be how we would migrate these functions. The way that I think I'm going to do it for this is I'm going to convert these into Tanstack start server functions. And if you aren't familiar with Tanstack start, it's this really cool new framework for building React applications that are server side rendered optionally. Um, very much like Nex.js or something like that. I could have probably done this whole thing with Nex.js, but I just got done making a video about Tanstax start, so I'm more familiar with it at this point. But anyway, so let's just stub out our tanstack start functions now. So here we can see it looks pretty similar to our convex functions from before. We have our list numbers query here at the top that validates our input with zod instead of convex's own validator library. And for now I've just mocked out the numbers to this array at the top here. And we will look at how to do the database uh in a minute. And we can see that our add number mutation is another task start server function with a zod validator writing into our mock database numbers array. And finally our my action server function is able to call into our queries and mutations directly uh and get the results as with our convex action from before. Right. So thus far the migration is looking pretty simple. We just swap out our convex functions to these um tens start server functions. But how does it look like on the client side? So before we would run our query like this and this is how we would do our mutations and this is how we actually call mutation. And it's all pretty simple and pretty clear if you ask me if you're familiar with convex. But now to call our tanstack start server functions we need to swap out our query with something that looks like this. So here we're using React query with a query key and a query function to call our list numbers server function with a count of 10. Then to do mutation we would uh swap it this out for this. And then to use the mutation we would just call it like this. So far so good. Not too many extra lines needed. Looks quite a lot like our Convex code. So that's nice. We aren't quite done yet though. You see, one of the biggest selling points of convex is that everything is reactive. That means that our use of use query uh here before um is effectively a live query. So when we added a number down here from before, it was going to be automatically updated and react is going to rerender this component for us. Unfortunately, tanstack start um/react query doesn't have this ability. So instead, we need to add a few more lines to our mutation to manually invalidate our local query, causing it to rerun to get our numbers once again. Okay, so now with that done, everything should work as before. So when I click on our button here, adding our numbers to our list, cool, it updates. Unfortunately though, if I just stop the Tanstack start server and start it again and refresh the page, then we'll see that our lovely set of numbers has been reset. Ah, that's because we aren't actually saving our numbers to a database. We're just it's just an inmemory uh array of numbers right now. Right. So, thus far, I think we're doing pretty well with our deloinifying. Is that a word? I don't know. It should be a word if it's not. We've migrated our server functions to a nice open- source non-locked version in the form of tanstack start. And so this is kind of what I want to do for the same for for the database. I don't want to be locked into another cloud database. So that means Firebase and Superbase are kind of out of the picture. And instead what I'll do, I'll just go for a regular old Postgress database running locally for now. But don't worry though, I'm not going to call the database with raw SQL. I'm not some sort of savage. I'm going to pull in drizzle OM for a convex like API to access my local Postgress database. So we can set up a drizzle schema like this. Note we had to define underscore id and created at ourself. Um with convex we get those automatically with every table. Um and then we also have our array of numbers here. We have to manually manage our migrations with postgress drizzle. So after a quick npx drizzle kit push, we can then go ahead and update our server functions like so. So now our list numbers query is going to select from our numbers table order by created at descending before just returning those numbers. And our add number mutation is going to insert the value into the database. And note just here that the conversion to string I think this is something to do with Postgress numeric versus JavaScript number precision or something like that. Anyway, let's take this for a spin now. So as before we can add a random number and again it invalidates our local state and calls our list numbers query again and it works. So, um, and if we now turn off our task start dev server and start it again and refresh the page, our numbers are still there. Very nice. All right. So, so far this is all pretty good. We've converted our convex functions to tanex start server functions and our convex database over to drizzle OM running on Postgress with not too much effort in my opinion. But the issue here is that this code is starting to look a lot less like our original code and thus would probably mean there's going to be a lot more work involved with migrating our existing convex code over to this new form. Let's see if we can tidy things up and improve this a little bit. So me and my buddy Claw just knocked out this little wrapper for Drizzle OM so that our server functions can now look something like this. So check this out. We can now query our database in our list numbers query here. And it looks very very similar to the convex one. And the same goes for our add number mutation here. It looks just like our comics one from before. This is nice. But I reckon we can go one step further. Let's have a look. Oo, look at this. Now we have something that looks almost exactly like our convex functions from before. We have our query, our mutation, our action. Each has an args and a handler. The args are nicely typed and we're able to access the database from the context and get nicely typed results. Our action even has the ability to run queries and mutations and get the typed results back. Very, very nice. So, in theory now, you should just be able to copy and paste some convex code into this new framework, change a couple of imports, and it should just work. Uh, kind of. You may have noticed that these convex functions aren't actually exported. You have to scroll down a little bit to see the actual exports. It turns out that Tanstack starts bundler expects create server function to be the top level assigned to a const and exported. So unfortunately that means we have to do a little bit of boiler plate rather than having nice wrappers that I wanted. But oh well, it's pretty close anyway. Oh, and by the way, I will leave this mini framework translation code. or whatever you want to call it down below in the description if you want to check it out. Right. So now we have an API that looks very similar to convex from before. But there is one subtle difference that we need to address. If you've watched my what is convex video, then you will know that convex queries and mutations run in transactions. To show you what I mean, let's check out this convex mutation here. Here we take a value and assert it into our database. But then later in the mutation, we do something here that may or may not throw an error. If it doesn't throw, then we insert another number. And if we just show this in action in the dashboard, if I select the function and run it with a number other than 69, then we'll see that both numbers are added to our table above here. But if I enter 69 as my number, then no numbers are actually added and we get an error. So this is showing that this first insert line gets dropped. That's because convex mutations are a transaction. So everything within the handler must succeed for it to be accepted for all database rights to be accepted. And this is very much intentional on Comics's part. It's to prevent very common mistakes in application development which can lead to corrupted state. Trust me, as your application grows, this is a very easy mistake to make. Now, if we head back into Tanstack Startland and we create a function that looks the same and then we try this out by creating a little temporary button on the front end, we'll see that when I click this add random number button here, we get both our number and the 1 2 3 from before. But if I click the add 69 button, then we only get the 69. So effectively our data has entered this corrupted and unexpected state which would be a nightmare to try and debug um in an application at scale. So we need to handle this somehow. Fortunately though, Drizzle does have a way to manage transactions. So I'm going to wrap our query and mutations in our little mini library here in transactions. So now when we try it again, I can add a random number to the list as before. But now when I try the add 69 button, bam, nothing. The transaction has failed and therefore roll back the initial uh addition of the number. Awesome. Now there are some subtleties around transactions serial ability. That's probably going to be a bit out of scope for this video. Just be aware that drizzle uh Postgress transactions might not be exactly the same as convex. And to be honest, this is one of the reasons why you might want to use Convex in the first place is because they've already spent a lot of time thinking about all these subtle issues. So you don't have to. All right. So at this point, I think I've covered what would be the core of what Convex is, but I hope you can see at this point that it would just be a matter of plugging in the remaining API holes with other alternatives. For example, maybe the file storage API that Convex provides could be replaced with S3. Maybe the full text and vector search could be replaced with Postgress extensions or maybe another service like Alolia. If you want real-time updates rather than having to do that local cache invalidation, then maybe look at Pusher. Pageionation you should be able to handle in Drizzle um using cursorbased pageionation. Orth probably can be handled yourself or with a library like better or passport.js or maybe a third party service like clerk or or zero. Scheduling could be done with a library like PG Boss or um maybe via Reddus via queuing library like Bullmq or maybe a more fullfeatured queuing library like Rabbit MQ. But anyway, you get the picture. At this point, it's just a matter of going through the remaining uh ComX APIs that you're using and swapping them out for third party options. I think probably the only one remaining feature of Convex that would be difficult to replicate is convex components. They are really pretty powerful and pretty unique feature with no obvious parallels to me that you'll be able to easily swap them out with. So I think probably it's your best bet is to replace the comics components with maybe some sort of micros service architecture or just simply replace the usage of those components with something else um you wrote yourself. Oh, and just finally before we jump into conclusion, if you are worried about your data being locked into convex cloud database, then you need not worry as there are plenty of ways to back up or stream out your data from the database. Just take a look at the dashboard or some of the docs for examples of how to do this. So, I think it's about time to come to a conclusion with all this. I hope I've demonstrated that the API level lockin isn't as bad as it might seem. the code modifications required to move away from convex could be manageable with the right approach. However, I would personally say that you would be taking on a lot more complexity by managing your own infrastructure and implementing your own solutions for features that convex would just normally handle for you. So, while it is possible to rewrite all of this yourself, I would say that if you're worried about lock in, then maybe you're worried about cloud lockin. Maybe then your best bet is just to migrate to Convex self-hosted uh and just manage that yourself. I think Jamie, the CEO of Convex, put this well when asked about this. Yeah, I mean in some respects it's fair that is true is that when you work with convex because convex is different because we have tried to innovate make something new you are working in a way that is unlike previous ways and um I think that one of the points that Theo made in the video which I haven't heard made quite this way before but I agree with is that like almost any tool that gives you leverage that lets you work faster you are getting kind of locked in to whatever particular advantage that tool is offering you right and So, I think one of the ways Theo um phrased it is if you tried to take another tool set and make it do everything Convex does to be able to move as quickly, you would end up writing a bunch of code yourself. And so, um you know, you what what you are kind of locked into is you've accepted a trade-off on like someone else having written that code for you. So, one other point I just want to mention here is that the inverse of all of this is also true. If you find yourself writing a whole bunch of code to create real-time updates, type safe RPC calls, queuing, scheduling, and all that, then maybe you kind of want to consider ditching all that complexity and migrating to Convex instead. And on a personal note, this is exactly why I fell in love with Convex a couple of years ago. I was struggling to implement these features myself in a very hacky way. And then I discovered Convex and I realized that they had done everything I was trying to do but just a thousand times better. Anyways, I hope you enjoyed this video and if you did, please do leave me a like and subscribe. And if you have any questions, please do leave them down below. I read every single one. Until next time, thanks for watching. Cheerio.
(Psst) Don't tell my boss this, but I just spent the past 2 days working on this just so I can show how easy it is to move AWAY from Convex.
Lock-in is something that has always concerned me, and I think you guys too, judging by this comment from Theo's latest video on Convex.
So that sent me down the path of finding out: how hard would it actually be to migrate away from Convex?
Self Hosting
Now as @xWe2s mentioned, Convex is open-source and as such comes with the ability to self-host the entire backend including the dashboard. There's full documentation on it over on GitHub.
I think this would certainly be the quickest and easiest way of going about migrating away from the lock-in of the Convex Cloud.
Buuuut I think that would be defeating the purpose for many people. I would presume if you were afraid of the lock-in like the author mentioned, then you would be looking to move to a different database and set of technologies altogether.
So with that in mind, let's go on a journey to see how hard would it REALLY be to move from Convex to something else?
Functions
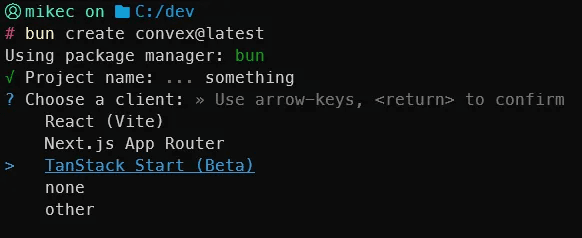
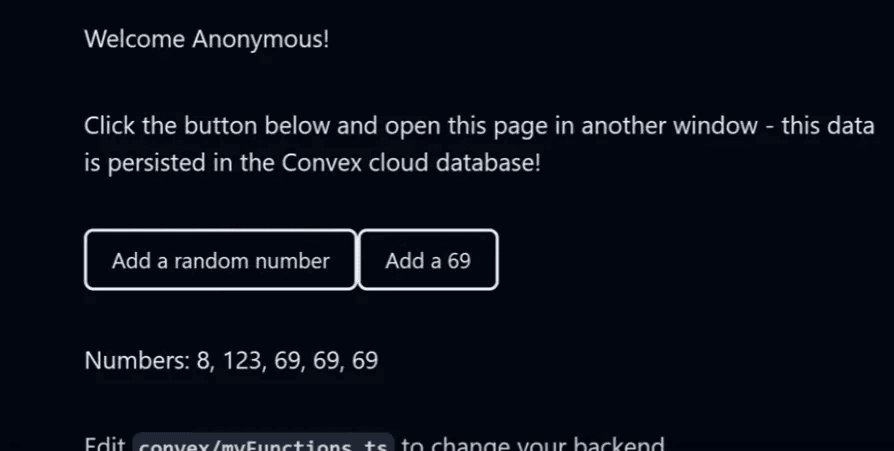
Alright, so as a starting point I'm going to npm create convex@latest and go with the Tanstack Start template.
If you aren't familiar with this template, it's very simple really. You can click a button that adds numbers to the array that show on screen. It's a great way to showcase a simple schema, query and mutation.
So let's take a look at the Convex code for this
1import{ defineSchema, defineTable }from'convex/server'2import{ v }from'convex/values'34exportdefaultdefineSchema({5 numbers:defineTable({6 value: v.number(),7}),8})9
So first we have a very simple schema with just one table numbers with just one field value.
Now let's look at the Convex functions:
1import{ v }from'convex/values'2import{ query, mutation, action }from'./_generated/server'3import{ api }from'./_generated/api'45exportconst listNumbers =query({6 args:{7 count: v.number(),8},910handler:async(ctx, args)=>{11const numbers =await ctx.db.query('numbers').order('desc').take(args.count)12return numbers.reverse().map((number)=>number.value)13},14})1516exportconst addNumber =mutation({17 args:{18 value: v.number(),19},20handler:async(ctx, args)=>{21const id =await ctx.db.insert('numbers',{ value: args.value})22console.log('Added new document with id:', id)23},24})2526exportconst myAction =action({27 args:{28 first: v.number(),29},30handler:async(ctx, args)=>{31const data =await ctx.runQuery(api.myFunctions.listNumbers,{32 count:10,33})34console.log(data)35await ctx.runMutation(api.myFunctions.addNumber,{36 value: args.first,37})38},39})40
Now as you're probably aware, Convex has 3 kinds of functions: Queries, Mutations and Actions. Queries and Mutations can directly access the database and are transactional, and Actions are not.
So I think the first step would be thinking about how we could move these away to something else. The way I think I'm going to tackle this is to convert these into Tanstack Start server functions.
If you aren't familiar with Tanstack Start, it's a really cool new framework for building React-powered Server Side Rendered applications very much like NextJS. I probably could have done this part of the migration with NextJS, but I just got done making a video on Tanstack Start so I am more familiar with it at this point.
Anyway, let's stub out our functions using Tanstack Start:
So here we can see that it looks pretty similar to our Convex functions. We have our listNumbers query here at the top that validates our input with zod instead of convex's own validator library.
For now I have just mocked out the numbers to this array at the top, we will look at the database part in a minute. We can see however that our Mutation addNumber again is a TanstackStart server function with a Zod validator writing into our mock "database" numbers array.
And finally our myAction server function is able to call into our query and mutation directly and await the results as with our Convex action from before.
Right so thus far the migration is looking pretty simple. How does it look on the client side?
So far so good, this looks quite a lot like our Convex code.
We aren't quite done yet though. You see one of the biggest selling points of Convex is that everything is "reactive" that means that our call to useQuery here is a "live query".
So when we add a number down here that query is going to be automatically updated for us.
1addNumber({value:Math.floor(Math.random()*10)})2
Unfortunately Tanstack Start / React Query doesn't have this so instead we need to add a few more lines to our mutation to manually "invalidate" our local query causing it to re-run to get our numbers once again.
1const queryClient =useQueryClient()2const addNumberMutation =useMutation({3mutationFn:(value:number)=>addNumber({ data:{ value }}),4onSuccess:()=>{5 queryClient.invalidateQueries({ queryKey:['listNumbers']})6},7})8
Now when we try it out everything should work as before.
Unfortunately though if I stop my Tanstack Start dev process and start it again we lose our lovely set of numbers. Whoops!
That's because we aren't actually saving our numbers to the database so let's take a look at that part now.
Database
Right so I think so far we are doing pretty well with "de-lock-in-ify-ing" (if that's not a word it should be). We have migrated our server functions to a nice open-source non locked-in version in the form of Tanstack Start.
For the database I want to do the same. I don't want to be locked into another cloud database, so that means Firebase and Supabase are out so I think I'll just go with a regular old Postgres Database running locally.
Don't worry though, I'm not going to call the database with raw SQL like some kind of savage.
I'm going to pull in DrizzleORM for a Convex-like API to access my local Postgres database.
Now our listNumbers is going to select from our numbersTable order by createdAt descending before returning just the numbers.
Our addNumber mutation is going to insert the value into the database. Note the conversion to string. I think this is something to do with Postgres numeric vs JavaScript number precision issues.
After taking this for a quick spin we can see that as before we can add a random number and again it invalidates our local state and calls our listNumbers query again.
And this time if we restart our dev server.
Then refresh the page.
Our numbers are still there, nice!
Cleanup
Now this is good and all, we have converted our Convex Functions over to Tanstack Start Server Functions and our Convex Database over to DrizzleORM Postgres with not a lot of effort.
Buuuut this code is starting to look less and less like Convex and is starting to look like more and more work if we had a lot of Convex code in our repo this migration might take a while.
Let's see if we can improve this. Me and my buddy Claude just knocked out a little wrapper for Drizzle so that our server functions can now look like this:
1import{ createServerFn }from'@tanstack/react-start'2import{ z }from'zod'3import{ createDrizzleConvexContext }from'~/lib/drizzleConvex'45const ctx =createDrizzleConvexContext(process.env.DATABASE_URL!)67exportconst listNumbers =createServerFn()8.validator((input:{ count:number})=>9 z.object({ count: z.number()}).parse(input),10)11.handler(async({ data, context })=>{12// Now using the Convex-like API!13const numbers =await ctx.db.query('numbers').order('desc').take(data.count)14return numbers.reverse().map((number)=>number.value)15})1617exportconst addNumber =createServerFn()18.validator((input:{ value:number})=>19 z.object({ value: z.number()}).parse(input),20)21.handler(async({ data })=>{22// This now handles the string conversion automatically23const id =await ctx.db.insert('numbers',{ value: data.value})24console.log('Added new document with id:', id)25})2627exportconst myAction =createServerFn()28.validator((input:{ first:number})=>29 z.object({ first: z.number()}).parse(input),30)31.handler(async({ data })=>{32const numbers =awaitlistNumbers({ data:{ count:10}})33console.log(numbers)34awaitaddNumber({ data:{ value: data.first}})35})3637
So now our database query listNumbers query looks just like our Convex one! The same goes for our addNumber mutation, looks just the same as our Convex one.
I think we can go one step further though by converting those server functions to something a bit more familiar:
1import{ createServerFn }from'@tanstack/react-start'2import{ v, query, mutation, action }from'~/lib/tanstackStartConvex'34const listNumbersQuery =query({5 args:{6 count: v.number(),7},8handler:async(ctx, args)=>{9const numbers =await ctx.db.query('numbers').order('desc').take(args.count)10return numbers.reverse().map((number)=>Number(number.value))11},12})1314const addNumbersMutation =mutation({15 args:{16 value: v.number(),17},18handler:async(ctx, args)=>{19const id =await ctx.db.insert('numbers',{ value: args.value})20console.log('Added new document with id:', id)21return id
22},23})2425const myActionAction =action({26 args:{27 first: v.number(),28},29handler:async(ctx, args)=>{30const numbers =await ctx.runQuery(listNumbersQuery,{ count:10})31console.log('Numbers:', numbers)3233const newId =await ctx.runMutation(addNumbersMutation,{34 value: args.first,35})36console.log('Added number with ID:', newId)3738returnnull39},40})41
Now we have something that looks almost exactly like our Convex functions from before. We have our query, mutation and action. Each takes an args and a handler.
The args are nicely typed and we are able to access the db on the context and get nicely typed results. Our action even has the ability to run queries and mutations and get typed results back.
So in theory now you should be able to literally just copy / paste some Convex function, change a couple of exports and you should be good to go…
… kinda ...
You may have noticed that these fake Convex functions aren't actually exported.
It turns out that Tanstack Start's bundler expects createServerFn to be at the top level assigned to a const and exported so unfortunately that means we have to do this little bit of boilerplate rather than having nice wrappers.
Oh well it's pretty close and not that much extra boiler.
Right, so now we have an API that looks very similar to Convex's, but there is one other subtle difference that we haven't addressed, and that's Transactions.
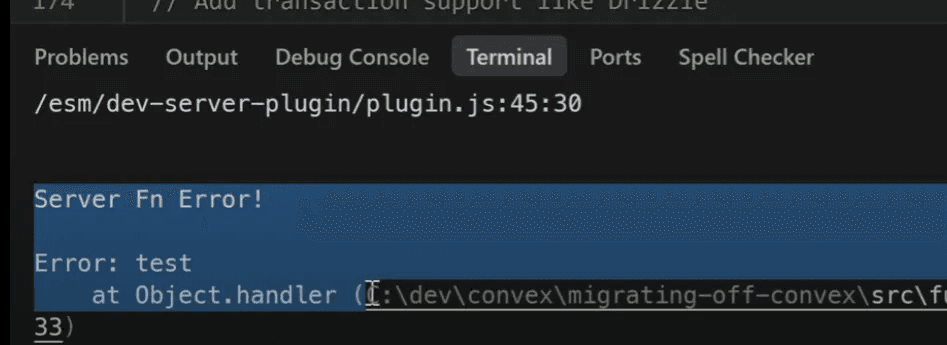
If you have watched my "What is Convex" video, then you will know that Convex's Queries and Mutations run in Transactions, that means everything must succeed for any database writes to be accepted.
This is to prevent a very common mistake in app development which leads to corrupted state. Trust me, this is a very easy mistake to make as your project grows.
Now if we head back to our Tanstack server functions and create a little demo to try this out:
So now when we try it again and I try to add 69, bam. Nothing, as expected. The transaction has rolled back and we get an error in our terminal from the server function.
Awesome, no more unexpected state!
Now there are some subtleties here around transactions and serializability, but that's probably going to be a bit out of scope for this video. Just be aware that Drizzle Postgres transactions may not work precisely like the Convex ones.
The Rest
Alright, so at this point I think I have covered what you might think of as the "core" of what Convex is, but I hope you can see at this point it would just be a matter of plugging in those API holes with other alternatives.
For example, the file storage API could be replaced with S3.
The full text and vector search could be replaced with Postgres extensions or with another service like Algolia.
If you want Realtime updates, then maybe have a look at Pusher for that.
Pagination can be handled by Drizzle cursor-based pagination.
Auth could be handled either yourself with a library like better-auth or passport.js, or with a third party like Clerk or Auth0.
Scheduling could be done with a library like PGBoss or via a Redis-based queuing library like BullMQ or a more full-featured queuing system like RabbitMQ.
You get the picture though, at this point it's just a matter of going around plugging the holes and swapping out Convex features for third parties.
I think the only one that might be difficult to replicate is Convex Components. They really are a pretty unique feature with no obvious parallel to swap it out with.
Probably your best bet to replace Convex Components might be some sort of microservice architecture or to simply replace those parts of your app with something you roll yourself.
Data Lock-in
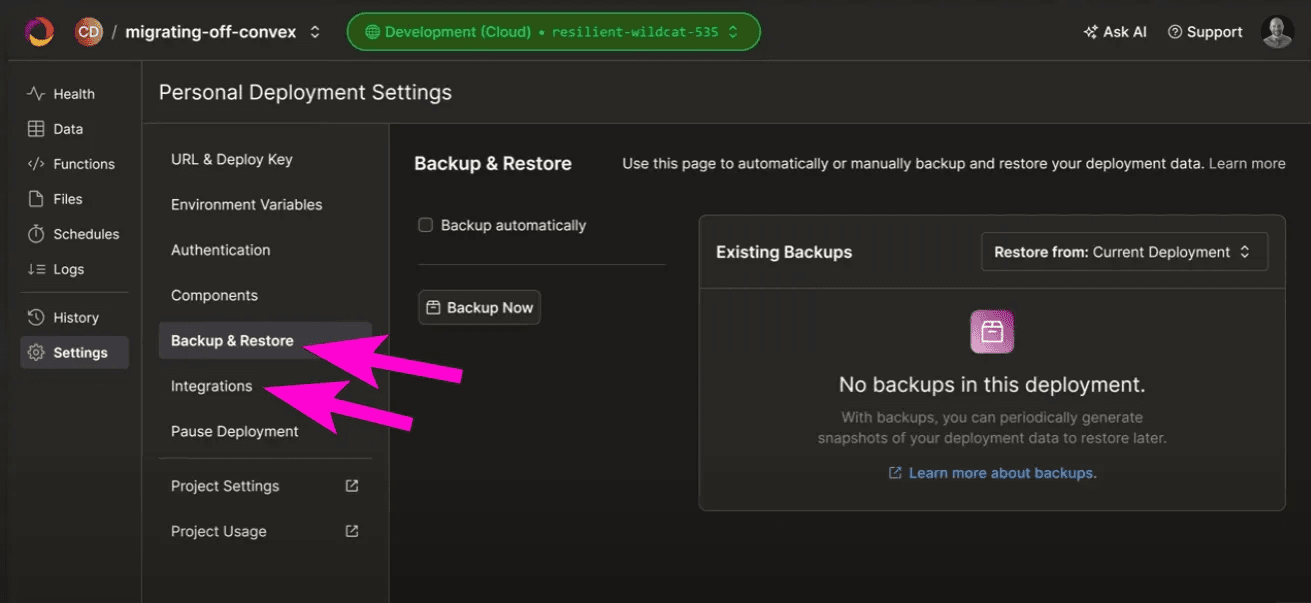
Oh and just finally before we jump into the conclusion, if you are worried about your data being locked into the Convex cloud database, then you need not worry as there are plenty of ways to backup or export your data at any time.
Conclusion
So I think then it's about time to come to a conclusion with all this.
I hope I've demonstrated that API-level lock-in isn't as bad as it might seem. The code modifications required to move away from Convex could be manageable with the right approach.
However, you'd be trading simplicity for complexity by taking on additional infrastructure management and implementing your own solutions for features Convex handles seamlessly for you.
So while it IS possible to write all this yourself, I would still say that if you are worried about lock-in on Convex cloud, your best bet is to migrate to Convex self-hosted.
So one other last point I want to mention here is that the inverse is also true.
If you find yourself writing a bunch of code to create realtime updates, typesafe RPC calls, queueing and scheduling all yourself, consider ditching that complexity and migrating TO Convex instead.
On a personal note, this is exactly why I fell in love with Convex a couple of years ago. I was struggling to implement these features properly in my own projects when I discovered a better way.
Until next time, thanks for reading,
Cheerio!
All gas, no breakages
Convex is the reactive backend platform that keeps up with you and your agents. Database, functions, workflow, sync, search, file storage, and more. All TypeScript, zero glue.