
Databases are Spreadsheets

This is my mental model of databases, which I learned during an internship interview and has stuck with me through 5+ years of working professionally on data loading platforms.
- Databases are just big spreadsheets
- An index is just a view of the spreadsheet sorted by one or more columns
- Binary search1 over a sorted list is faster than a linear scan (for large lists)
Imagine storing movies in a spreadsheet. It might look something like this:
 A picture of a spreadsheet of movies sorted by ID.
A picture of a spreadsheet of movies sorted by ID.
We want to store this with some order, so this spreadsheet is sorted by the first column -- a unique _id field.2 This means we can quickly find a document from this table given its ID because we can binary search.
Let’s say we want to build a way for users to see all the movies for a given director like this (here, sorted by release date):
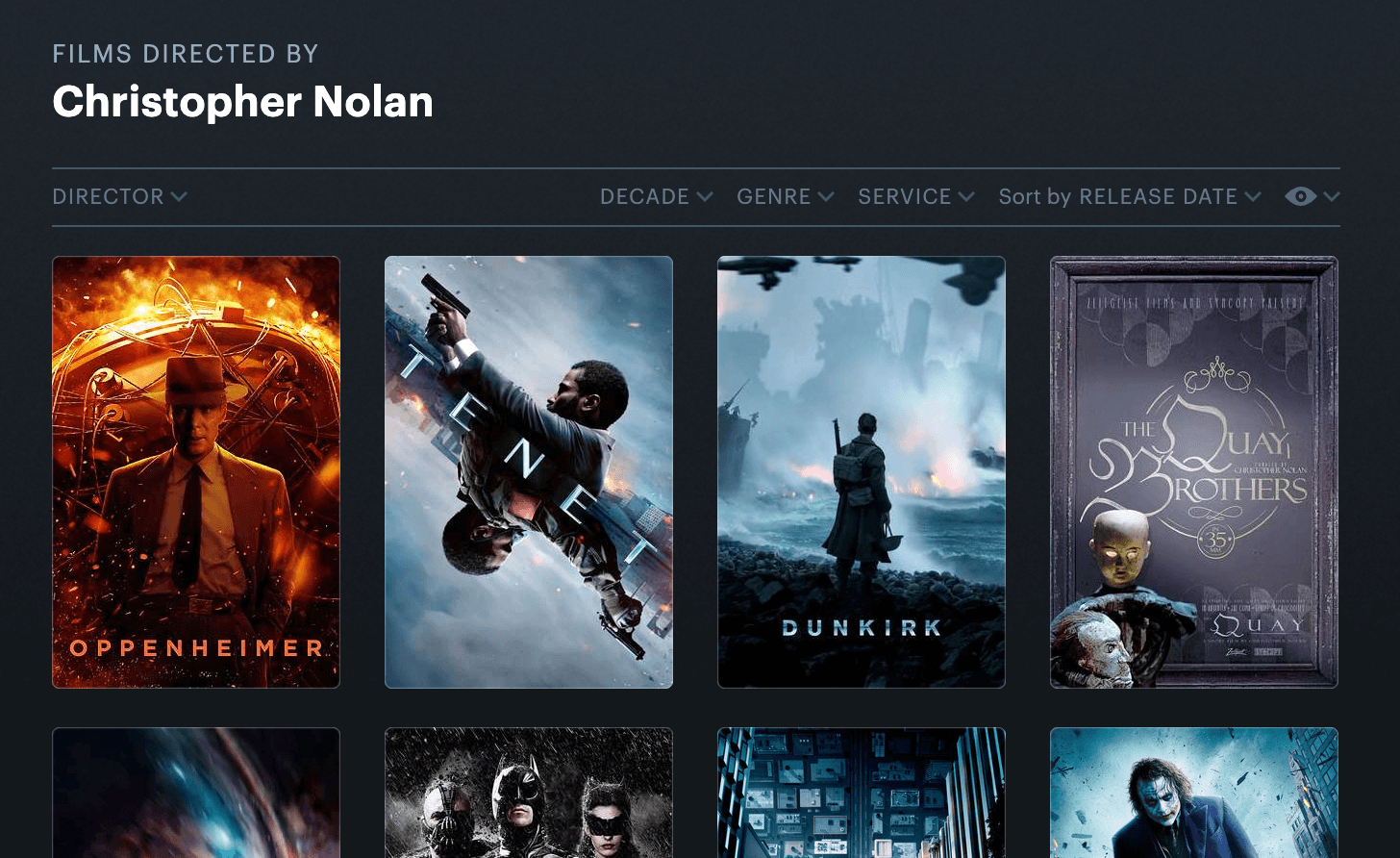 A picture of the Letterboxd UI
A picture of the Letterboxd UI
We might want a view that sorts by the director, and then the year:
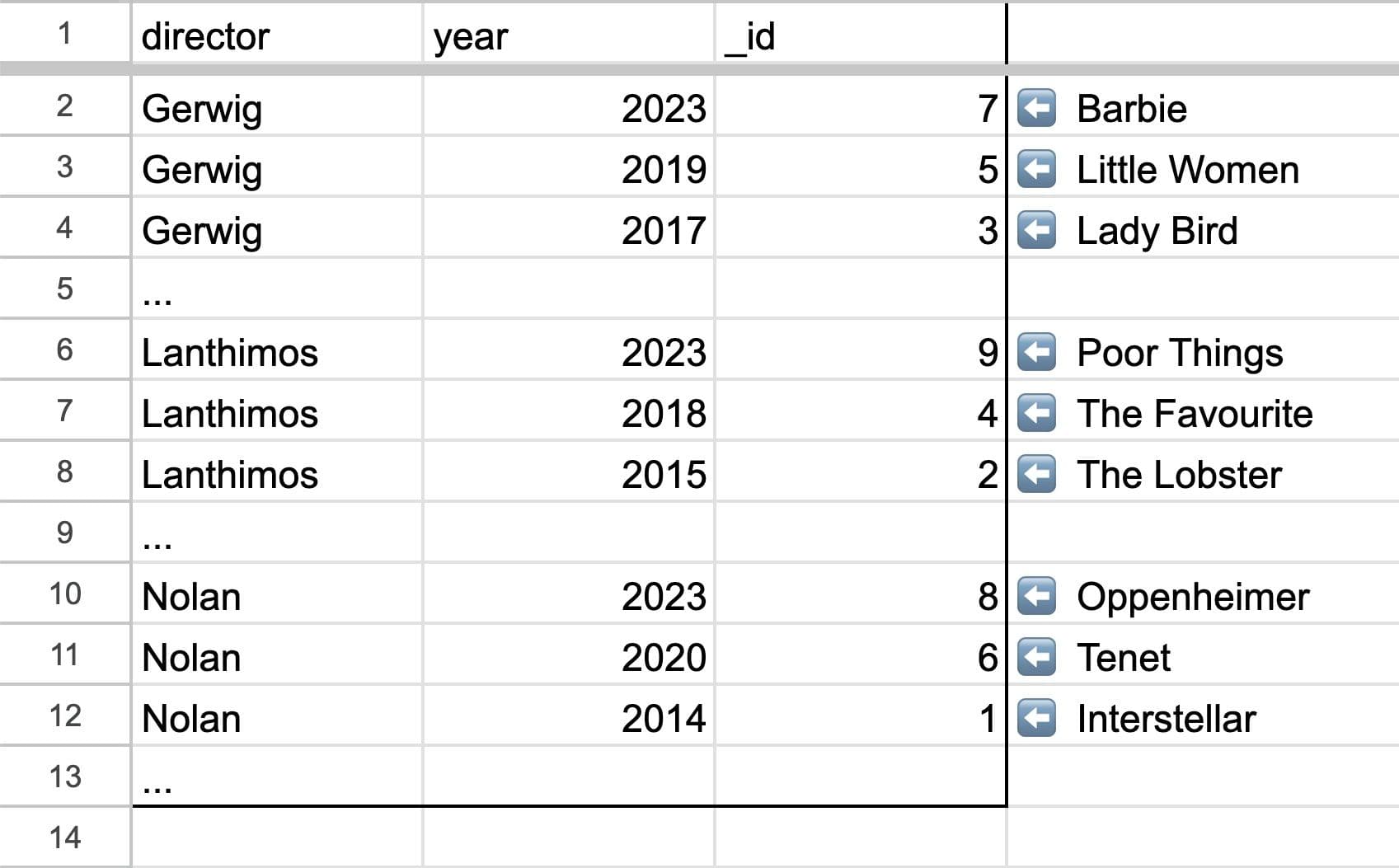 A spreadsheet tab sorted by director, and then year
A spreadsheet tab sorted by director, and then year
 Spreadsheet tabs with Movies.ByDirectorAndYear selected
Spreadsheet tabs with Movies.ByDirectorAndYear selected
This is an index! We could define it with convex like so:
1Movies: defineTable(...).index("ByDirectorAndYear", ["director", "year"])
2This is like another tab in our spreadsheet, and we use the _id to reference the document in the first tab to avoid needing to include the full document in each tab of the spreadsheet (the movie names are shown to the side for convenience).
We can use it to make the following query:
Goal: Get all movies directed by Nolan.
Code: db.query(”Movies”).withIndex(”ByDirectorAndYear”, q => q.eq("director", "Nolan"))
Picture:
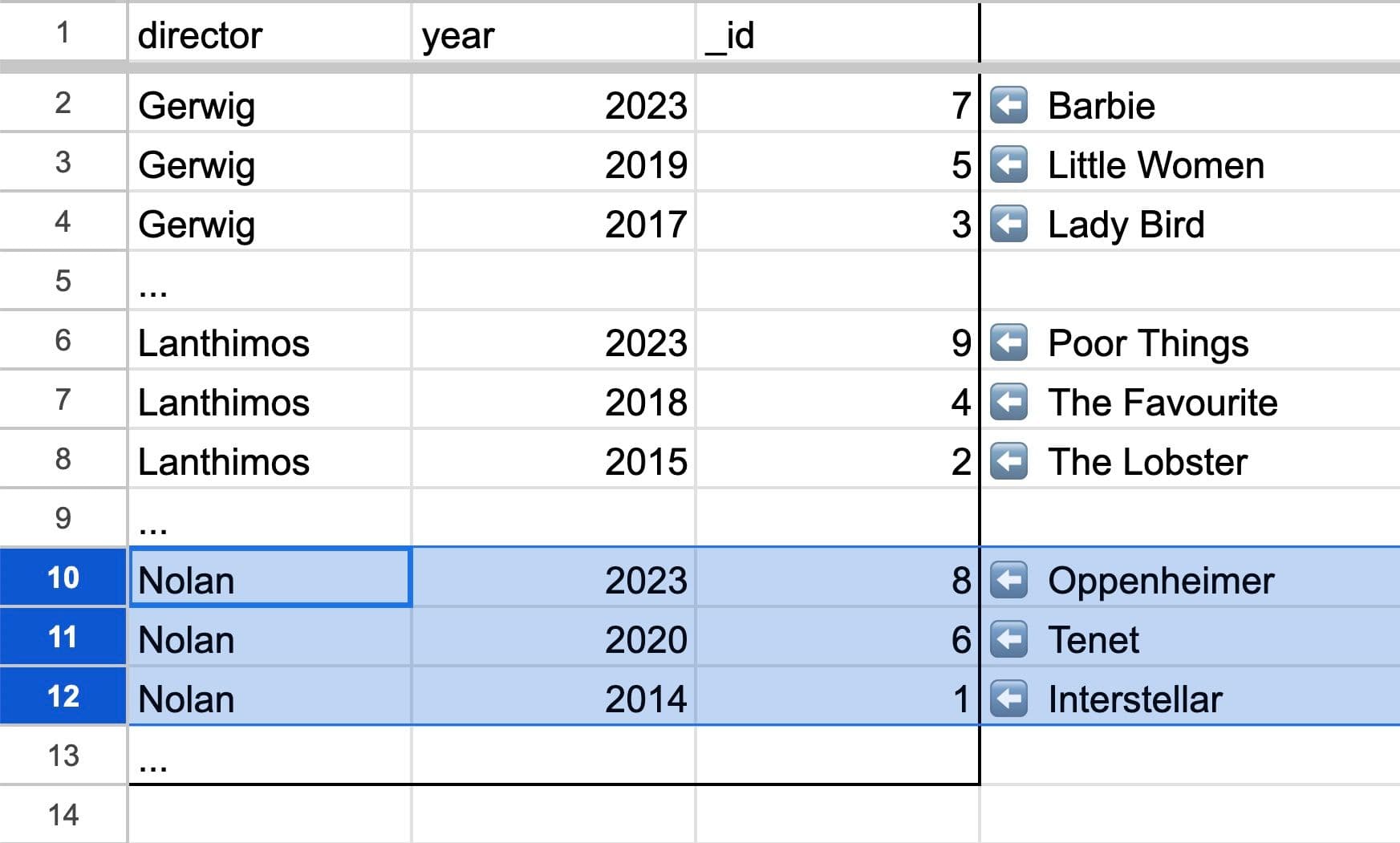 Selecting the block of Nolan movies from the ByDirectorAndYear tab
Selecting the block of Nolan movies from the ByDirectorAndYear tab
We use the Movies.ByDirectorAndYear tab to binary search for the first entry with “Nolan”, and keep grabbing rows until we reach a new director. Once we have all these IDs, we can grab the full documents from the first table Movies.ById, binary searching for each ID. This means we can efficiently grab any contiguous chunk from our spreadsheet.
One thing we can observe right away is that when a new movie gets added or updated in the first tab, we also need to add an entry to each tab in our spreadsheet. This means each index has a bit of write overhead and also requires some additional storage.
But the Movies.ByDirectorAndYear tab is useful for making fast queries that take advantage of the sorted order in that tab, so if we're making a lot of queries that use this ordering, the write overhead + additional storage for maintaining this extra tab is worth it.
We can use this mental model to go through a few more queries and make some observations:
We must go through columns in index order
Goal: Get all movies from 2023.
Code: ❌ db.query(”Movies”).withIndex(”ByDirectorAndYear”, q => q.eq("year", 2023))
Picture:
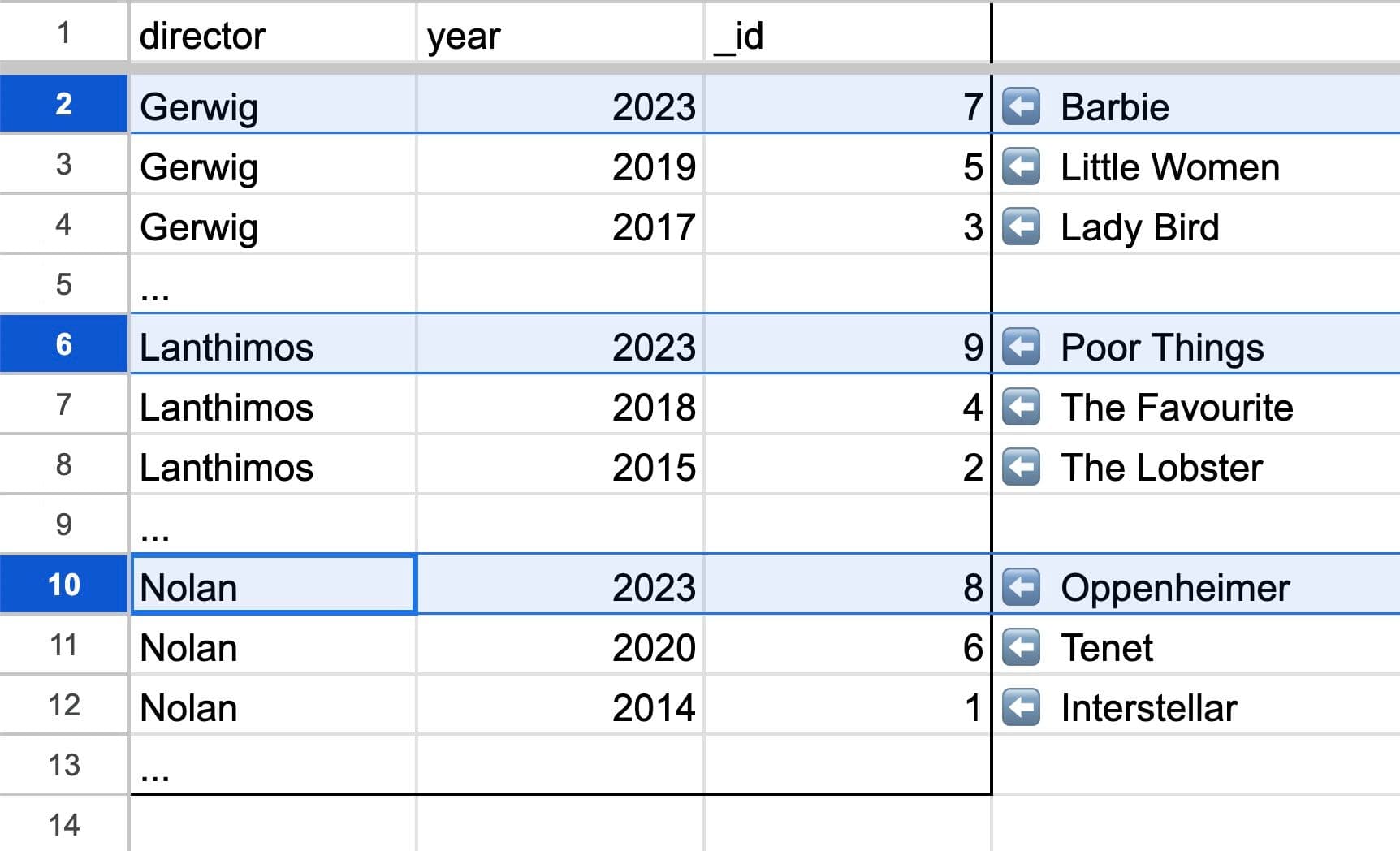 Demonstrating that movies made in 2023 are not contiguous in the ByDirectorAndYear index
Demonstrating that movies made in 2023 are not contiguous in the ByDirectorAndYear index
This query does not select a contiguous chunk from the spreadsheet — to find all the movies from 2023, we’d have to look at every single row and can’t use the sorted columns in this tab to our advantage.
Inequalities
Now let’s consider a new index ByYearAndDirector (which would be a better choice for the example above).
Goal: Get all movies created in 2018 or later.
Code: ✅ db.query(”Movies”).withIndex(”ByYearAndDirector”, q => q.gte("year", 2018))
Picture:
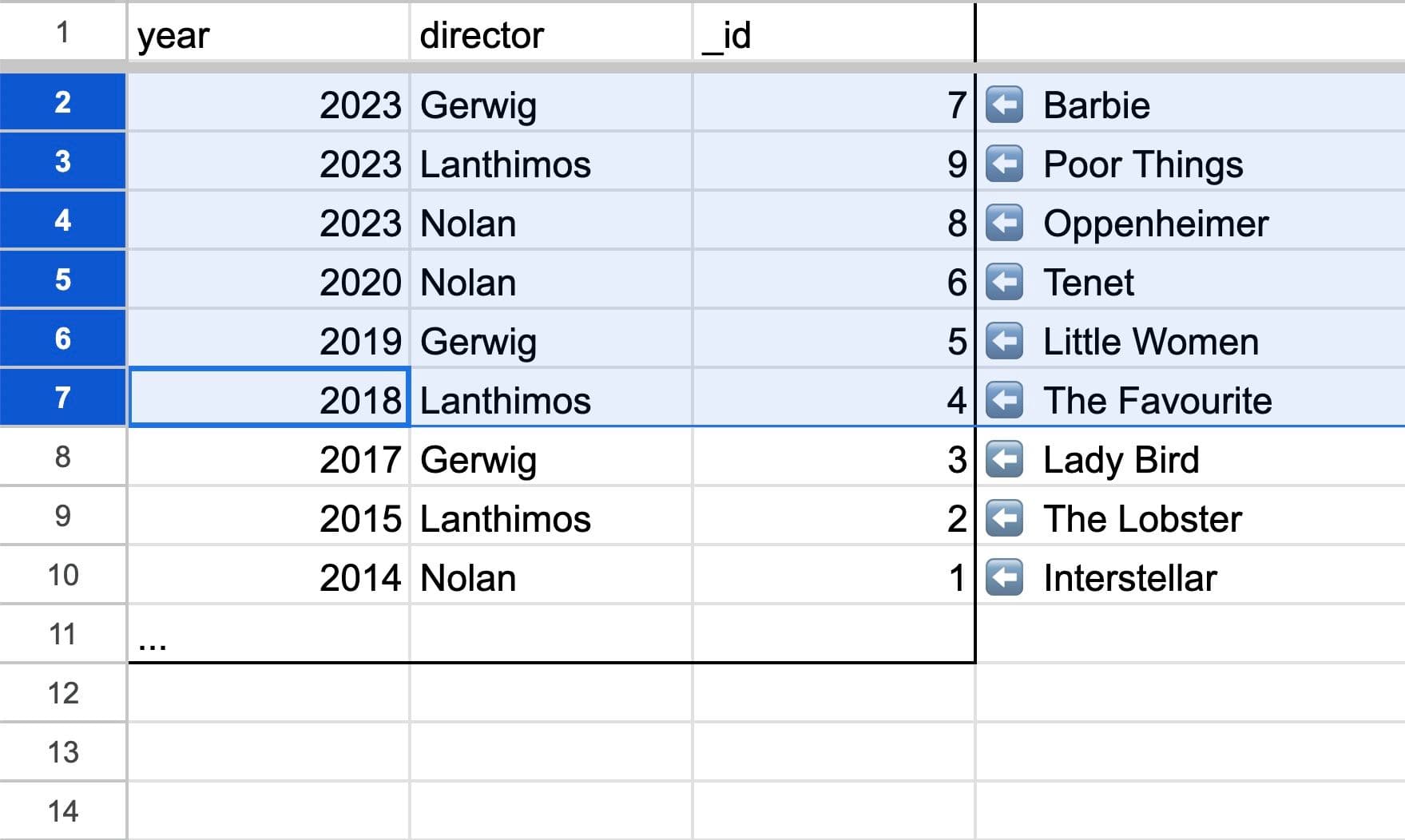 Movies sorted by year and then by director
Movies sorted by year and then by director
 Spreadsheet tabs showing ByYearAndDirector selected
Spreadsheet tabs showing ByYearAndDirector selected
Even though this isn’t an “equals”, we can still binary search and select a contiguous block with “greater than” or “less than”.
…But we can only use “greater than” at the end.
Goal: Get all movies created in in 2000 or later with directed by Nolan.
Code: ❌ db.query(”Movies”).withIndex(”ByYearAndDirector”, q => q.gte("year", 2000).eq("director", "Nolan")
Picture:
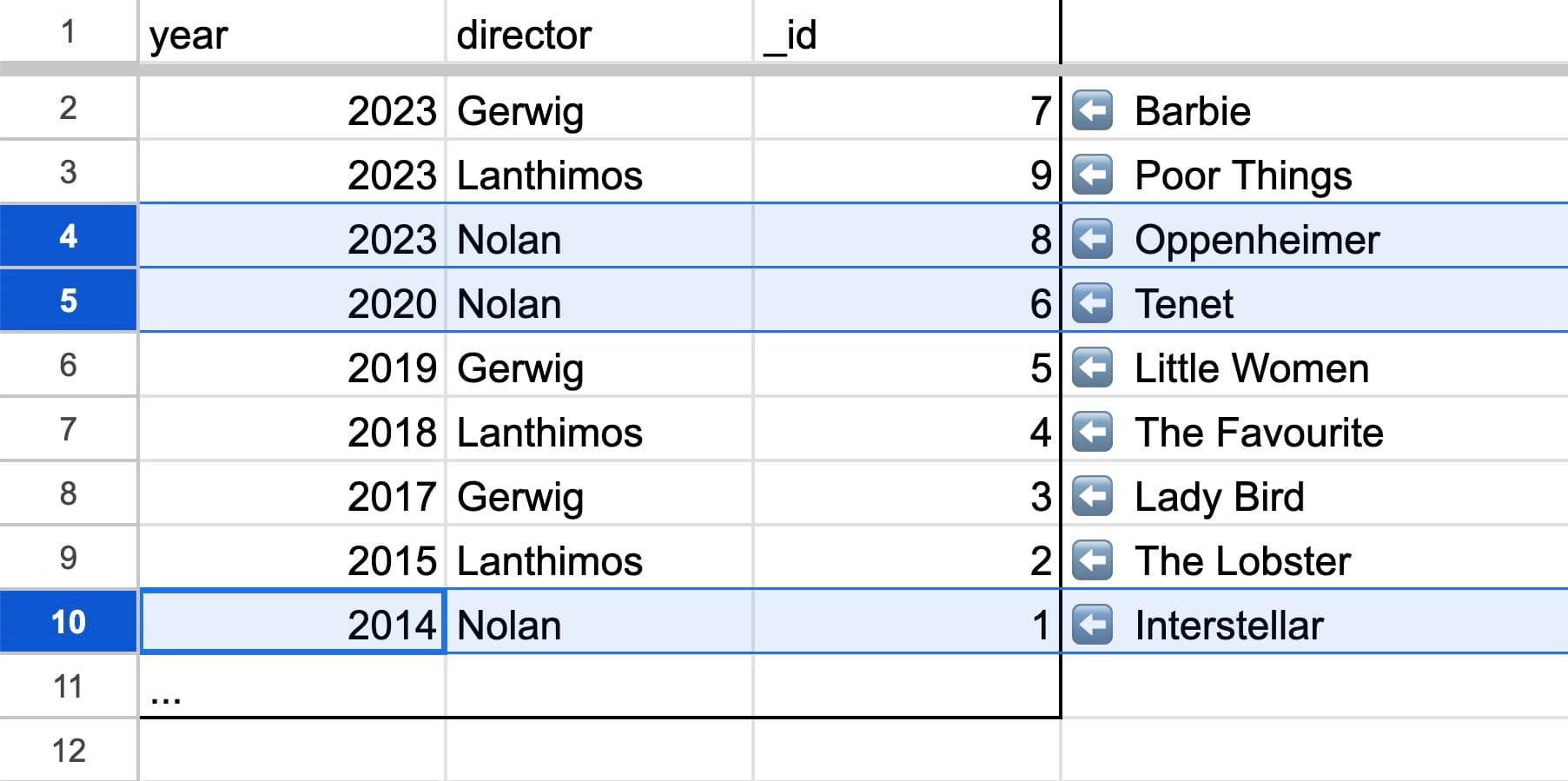 Demonstrating a query with an inequality filter followed by an equality field
Demonstrating a query with an inequality filter followed by an equality field
We can’t do “not equals” in a single efficient query — we need to do two binary searches.
Goal: Get all movies not made in 2018.
Code:
❌ db.query(”Movies”).withIndex(”ByYearAndDirector”, q => q.neq("year", 2018))
✅ db.query(”Movies”).withIndex(”ByYearAndDirector”, q => q.gt("year", 2018)) and db.query(”Movies”).withIndex(”ByYearAndDirector”, q => q.lt("year", 2018))
Picture:
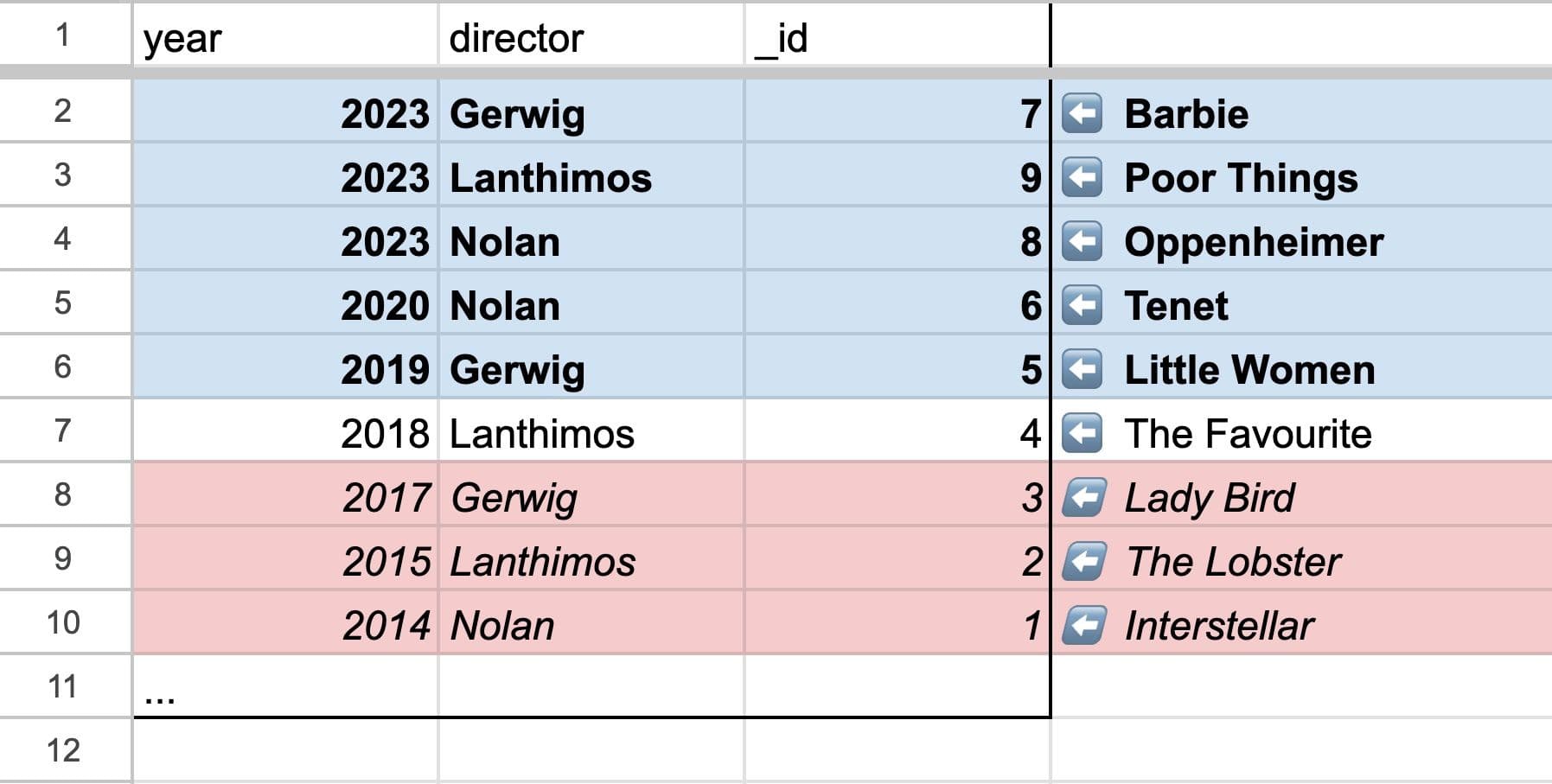 Demonstrating a "not equals" query is actually two separate queries
Demonstrating a "not equals" query is actually two separate queries
No efficient “in” / “or”
Goal: Get movies directed by Nolan or Gerwig.
Code:
❌ db.query(”Movies”).withIndex(”ByDirectorAndYear”, q => q.in("director", ["Nolan", "Gerwig"]))
✅ db.query(”Movies”).withIndex(”ByDirectorAndYear”, q => q.eq("director", "Nolan")) and db.query(”Movies”).withIndex(”ByDirectorAndYear”, q => q.eq("director", "Gerwig"))
Picture:
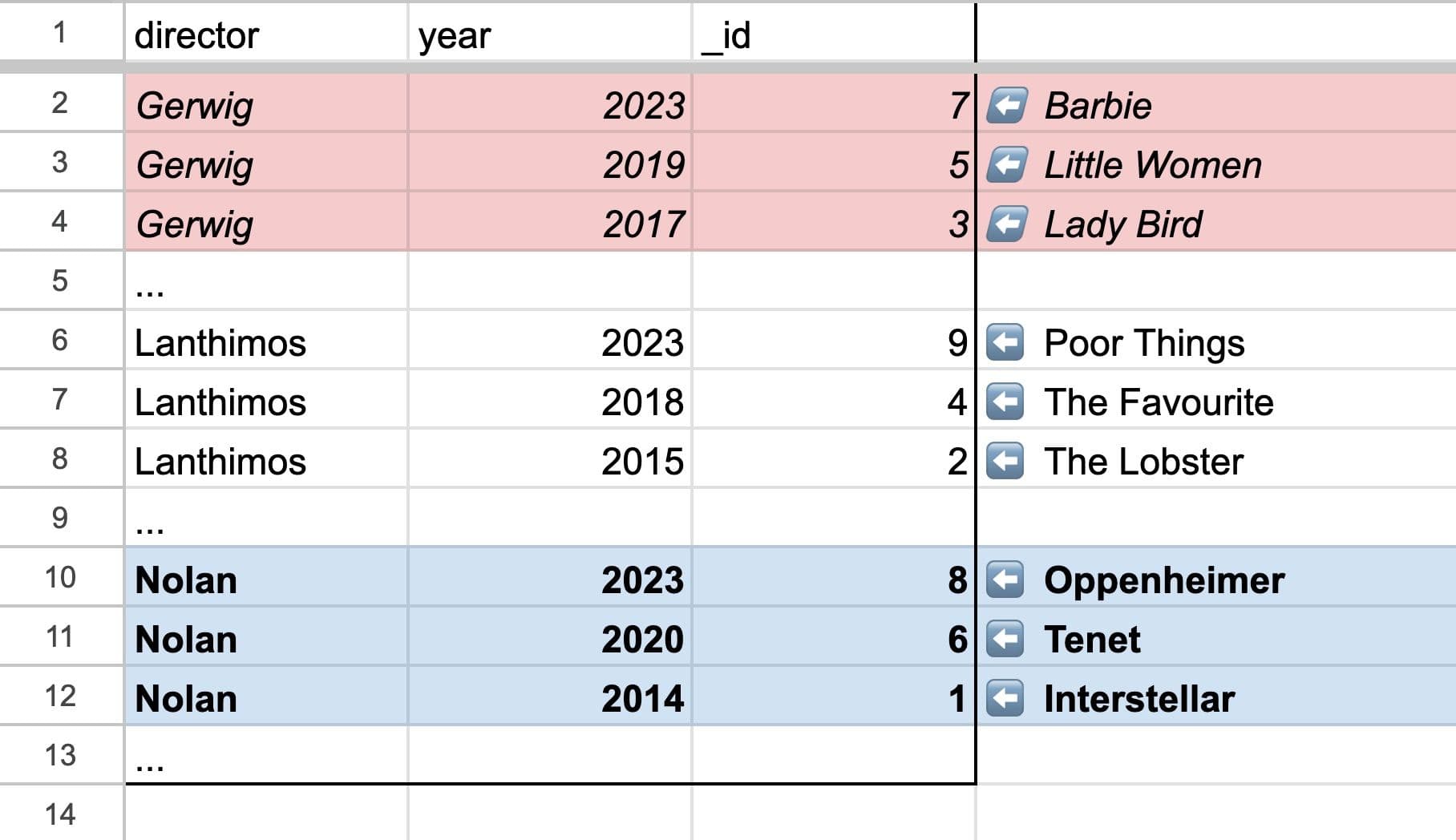 Demonstrating an "in" query is really N separate queries
Demonstrating an "in" query is really N separate queries
This is really a separate query for each element in the “in” / “or” expression and cannot be done in a single efficient query.
Convex’s query syntax
Convex's syntax aims to make it clear what's efficient vs. what's not. Things in withIndex will be more efficient binary searches, things in filter or in plain JavaScript are not.
Going through the examples above:
- We prevent
.withIndex("ByDirectorAndYear", q => q.eq("year", 2023))(skipping fields) - We prevent
.withIndex("ByYearAndDirector"), q => q.gte("year", 0).eq("director", "Gerwig")(non-final inequalities) - There's no
or,in,neqforwithIndex
In comparison, it’s easy to write all of these as a SQL query without realizing they’re slow. Just because it is possible to write a query in SQL doesn't mean it'll be fast -- SQL's query planner will just try its best to choose from the indexes you have and do a linear scan of the table if there's no better option.
Something like SELECT * from Movies WHERE title = "Barbie" LIMIT 1 might look innocent enough, but if there's no index on title, the query planner will iterate over the entire table. Even knowing all the indexes on a table, it’s often hard to tell whether a SQL query is efficient or not by looking at it since it's difficult to predict exactly what the query planner will choose to do.
Why should I choose my indexes?
Now we have a mental model of how indexes and databases work, but you might be asking why it’s valuable to think about this or why you should be the one deciding exactly which indexes you want.
If we keep applying the “databases are spreadsheets” mental model to different queries and indexes, we’ll find that some indexes aren’t actually that useful ...and it's usually specific to the product you're designing.
As an example, most directors only have a few movies (<20). Once we've narrowed down to the movies for a single director, binary searching within those ~20 for movies in a certain year or with a certain rating isn’t much more efficient than scanning all of them. Instead of a ByDirectorAndYear index, we might just want ByDirector, and do any sorting and filtering we want without an index (in JavaScript):
1const nolanMovies = await db.query("Movies")
2 .withIndex("ByDirector", q => q.eq("director", "Nolan"))
3 .collect();
4// sort by release date
5nolanMovies.sort((a, b) => a.year - b.year))
6If we wanted to allow a bunch of different sorts and filters for a single director’s movies, we probably can just do all the sorting and filtering in JavaScript and don’t need an index. (e.g. “Get movies directed by Nolan sorted by title”, “Get movies directed by Nolan available on Hulu”).
On the other hand, we might want a ByGenreAndYear or a ByGenreAndRating index, since there are many movies in a genre, so it’s useful to be able to efficiently narrow down the results further (e.g. “Get the top 50 rated horror movies”, “Get comedy movies released in the last 5 years”). We might even design our product to have fewer sorts and filters for the genre pages than for the director pages to avoid needing a bunch of indexes.
As another example, an index like ByTitle also might not be that useful. Your users probably won’t want a list of all movies ever listed alphabetically and probably won’t look up a movie with the exact title. Instead you might want a full text search index3 on the title (so users can type “the dark kni” to find a movie), or you might want an index like ByTitleSlug where each movie has a unique slug (e.g. little-women, little-women-2019) that can be used in URLs.
Summary
To repeat the mental model:
- Databases are just big spreadsheets
- An index is just a view of the spreadsheet sorted by one or more columns
- Binary search over a sorted list is faster than a linear scan (for large lists)
Database indexes can be thought of as separate spreadsheet tabs that we keep in a specific sorted order, and keep up to date on every addition or update to the original data. Indexes are useful for making queries fast as long as we can select a contiguous chunk from the spreadsheet tab, using binary search instead of scanning the entire spreadsheet.
Hopefully thinking of databases as spreadsheets is helpful for thinking about when and how to define an index based on the data you’re storing and the product you’re building. Convex is designed to make performance of queries clear by only supporting the operations that can be done efficiently in our query syntax.
Footnotes
-
This is actually a B-Tree look up in a real database since they're designed to work efficiently with hard drives, but the mental model of binary search is pretty similar (O(log n) search on a sorted list). ↩
-
This is called the "primary key" in databases. ↩
-
How search indexes work probably merits an entirely separate post, but they're similar to the "spreadsheet tab" mental model in the sense that they require extra storage + write overhead, and that the parts of the query in
withSearchIndexwill be efficient compared tofilteror plain JavaScript. ↩
Convex is the reactive backend platform that keeps up with you and your agents. Database, functions, workflow, sync, search, file storage, and more. All TypeScript, zero glue.