
Agents Need Durable Workflows and Strong Guarantees

Imagine this: Your project is taking off. Users are pouring in and running into every edge case. You start digging into some issues and you realize that your database data doesn’t make sense. How did that user get into that state? Where did all these half-finished workflows come from, and what happened to those users? Why didn’t that function that was supposed to update their profile run? Or did it?
Sound familiar?
Apps are increasingly using long-lived workflows, such as agentic systems, that make many requests to unreliable third-party APIs. For these apps, it’s especially important to anticipate failure modes and use solid abstractions with strong guarantees.
In this article we’ll explore improving correctness and lowering your stress levels through:
- State machines powered by durable functions.
- Invariants enforced in transactions.
- Retrying with idempotency.
If these terms are unfamiliar, have no fear! I'll explain them below, and show an example of using a durable workflow.
If you're curious about Agentic frameworks, check out the one I just built.
Example: customer service agent
Before we dive into the theory, lets ground it with an example. Let’s you have automated product support where, when a user sends in a support message, you kick off this workflow:
1async function supportWorkflow(ctx, { user, message }) {
2 // 1: Fetch the customer history from the database
3 const userHistory = await ctx.runQuery(customerHistory, { user });
4 const summary = await summarizeHistoryWithAI({ message, userHistory });
5
6 // 2: Create a CX (Customer Experience) ticket with the summary for the user.
7 const ticketId = await ctx.runMutation(createTicket, { summary, user, message });
8
9 // 3. Fetch related context from a vector + transactional database
10 const context = await fetchSupportContext(ctx, { summary, message, user });
11 await ctx.runMutation(updateTicket, { ticketId, status: "in-progress", context });
12
13 // 4. Generate a proposed resolution via an LLM call with multiple tools
14 const resolution = await getAIResolution({ context, userHistory, summary });
15 await ctx.runMutation(updateTicket, { ticketId, status: "resolution", resolution });
16
17 // 5. Respond to the user
18 await sendUserReply({ user, message, resolution });
19}
20This is a simple linear flow, but it’s still riddled with potential issues.
How failure manifests:
Let’s think about what happens when failure occurs at various stages. Think of failure here as somewhere like a network failure or the server restarting, where you can’t reliably wrap your code in a try{}except{} to handle failures.
- If it fails during step 1, then the CX ticket is never created and the user never receives a reply. The ticketing system has no record of this. Hopefully the HTTP response encourages them to retry. Or will your client automatically do it? If so, how does it know what’s idempotent and what isn’t? What if the client has lost connection?
- For step 2, if there’s a database conflict or the database connection drops, what are you doing to handle and resolve it? Do you have retries that can lead to overload and cascading failure? Does your ORM even expose the ability to catch database conflicts beyond simple constraints?1
- If it fails in step 3, the ticket will be created but never updated to either success or failure. Do you have a daily cron that scans for such tickets?
- Failure here similarly leaves the ticket in limbo - at what point does the system treat an “in-progress” task as dead? What if it’s just taking a long time? Can you query the health of the function itself? (Spoiler: some platforms support this!)
- This might be the most frustrating for the user. While failure in 2-4 could get detected by the system eventually, here the CX system thinks it’s done, but the user is forever waiting for a reply.
 Your user, waiting for a message that will never come.
Your user, waiting for a message that will never come.
Your user, waiting for a message that will never come.
And here’s the real achilles heel of modern serverless applications:
If you depend on a single longstanding network request to do meaningful work and only then return results to a user, the client can’t confidently proceed when anything goes wrong.
If you wait to reply to the user until you get an answer and the user’s connection blips or they refresh their browser, how do they (or you) continue where you left off? Do you first have them send a request to get the ticket ID, then poll the status? Do you implement a WebSocket protocol?
In this article I will give some practical advice for reasoning about correctness, reliability, and clean abstractions that can guarantee exactly-once completion of workflows and allow you to rigorously reason about failure, which no one wants to think about but everyone has to deal with eventually.
The problems you don’t want to think about
At a higher level than the example, here are a number of runtime common in systems with long-running requests, especially when they’re running in the context of an HTTP request:
- Client disconnects leading to “losing” the result.
- Server restarts or transient failures leaving the flow either in limbo or failing it completely.
- Inconsistent data states when multiple agents are independently working, succeeding and failing.
- Holding open transactions while making API calls, locking the database and grinding everything to a halt unexpectedly.[^2]
- Compounding unreliability: even if you’re using a service that has a 99% API success rate, if you make 10 calls, e.g. in a loop with LLM calling tools, you effectively have a 90% success rate.
- Exhausting shared resources: if you have a fan-out pattern, such as web crawlers, what’s preventing you from swamping your available compute or memory, thereby starving out more urgent requests?
- 🎵 And many more 🎵
Let’s take a look now at all of the resources we can bring to bear to make this all easier. If you’re not interested in learning and want to jump to a solution, click here.
Your correctness quiver, explained
Here are some words people like to throw around to sound smart, and also happen to be great ideas when you’re aiming for correctness and predictability. They’ll build on each other, so they’re worth understanding in order. I’ll use examples from Convex to illustrate the properties, but these concepts are evergreen and universal.
If you’re already an expert, 👏.
Transactions
Transactions help avoid race conditions when reading and writing to the database. They allow you to group up reads and writes into one atomic unit, that either all succeed or all fail. The simplest operation is inserting multiple documents in a single SQL statement. Putting many operations (statements) one after another requires an explicit range to be defined. In Postgres, this is with BEGIN and COMMIT statements (or ROLLBACK). In Convex, every Mutation is a single transaction (with sub-transactions via ctx.runMutation). Read more about
Transactions are a core feature of databases (though not all have them, and most default to surprisingly weak guarantees, including Postgres 😱). They are a powerful abstraction, but require proximity to the database, since holding open transactions can slow down other competing transactions. Platforms like Supabase do not support transactions from the client. Convex only supports the highest level (seriallizable) via MVCC with OCC which you can learn more about here if you’re curious.
Did you know that transactions can encompass not only data, but function invocation? What if I told you that you could transactionally execute a function if (and only if!) the rest of your data commits without conflicts. In our example, you could ensure that only ever one LLM response is sent to the user by only scheduling the response message to be sent if the status wasn’t already sent. I’ll admit I once sent twenty thousand people duplicate emails when I restarted a batch job that I thought had failed. Needless to say, I did not check and update the job status in a transaction.
For the Workflow, Workpool, and Action Retrier components, you can use them to kick off asynchronous work from within a transaction, and trust that if your transaction rolls back it will never execute, and if it commits it always will execute.
Idempotency
If you can call a function multiple times and get the same result (where result includes the database state and other side-effects), it’s considered idempotent. For example, having a function that adds a message to a chat is not idempotent. However, if you have a message ID and repeatedly call a function to set the message body if it hasn’t been set, it is idempotent. Unsurprisingly, Stripe’s API has idempotency keys you generate client-side, so you can submit the same request multiple times without dual-charging a customer.
In Convex, you get idempotency for free with mutations in these situations:
- When you call a mutation from the WebSocket-powered client, it first records the mutation arguments and a unique ID client-side, then makes the request, retrying on failure. If the server has already processed that ID, it returns the same result as the original. Mutations are transactional, so if it fails mid-way, the transaction will roll back, making it safe to retry. The client will retry for days until it runs the function to completion.
- When you use the scheduler with a mutation, it will indefinitely retry the mutation on database conflicts until it succeeds or throws an exception from your code. It will continue retrying across server restarts or suspension, giving you an exactly-once guarantee.
Note: If you call a mutation directly from an action (via ctx.runMutation) or over HTTP client, it will retry database conflicts, but not automatically retry otherwise. We’ll talk more about the implications of this later.
Retries
Retries are increasingly important in agentic systems due to the high number of API requests being made and the unreliability of LLM hosting providers today. The paper The Tail At Scale is a great read, and while focusing on latency, illustrates the issue well:
…consider a system where each server typically responds in 10ms but with a 99th-percentile latency of one second. If a user request is handled on just one such server, one user request in 100 will be slow (one second)… If a user request must collect responses from 100 such servers in parallel, then 63% of user requests will take more than one second 2
Retries allow you to smooth out transient failures in other systems, and are an important tool for increasing reliability, so long as you can ensure it is safe to do so, such as when:
- The operation is idempotent, either inherently or by introducing something like an idempotency key.
- The operation doesn’t have side-effects, such as calling a GET method or LLM endpoint.3
We’ve built a couple components on Convex to handle retries, using the transactional and idempotent properties listed above: Action Retrier and more recently Workpool, which both implement retries with backoff and jitter, using the scheduler for backoff (instead of sleeping / spinning) to avoid wasting time in your serverless function. They will survive server restarts, and provide exactly-once execution of an onComplete handler, which enable implementing durable functions, which we’ll discuss next.
Durable functions
A function is durable if it can survive hardware failures and keep executing from where it left of. Functions with the property seem magical, and like to show off by doing things like “sleeping” for a year mid-function, trusting that the second half of the function will run a year later. Temporal is one notable example, and the Convex Workflow component is another. However, time travel can be hard to reason about4, so let’s talk about higher level properties of durable functions we can achieve with less-magical concepts.
The important properties to me are:
- You can execute a number of steps (”function”) dynamically, using code for flexibility. The “function” should allow for dynamically making decisions about what to run next.
- Each step behaves idempotently, as if each step function was evaluated in sequence once through.
- The “function” is guaranteed to make progress and eventually terminate. By this I mean that a transient machine failure or exception won’t leave the status suspended “in limbo”. It will always eventually result in success or failure, without being prodded along by a user.
One nice property of the Workpool introduced above is that it has an onComplete handler, which is guaranteed to execute exactly once, giving you idempotency and guaranteed progress at the same time. So when you enqueue work, you can rely on the onComplete handler to give you an opportunity to decide what to do next, whether that’s handling the failure, transactionally recording the result in the database, or deciding what to enqueue into the workpool next.
A common strategy for implementing a durable function, given transactions, and idempotency, is to “journal” the result of each step, which is the next gadget in our utility belt.
Journaling
Journaling can be understood as recording the inputs and outputs of each step, allowing pausing, resuming, and replaying steps. It works by treating the overall “function” as deterministic- if the first step S took as parameters A and returned B, then every time we “resume” the function, we expect the parameters to step S to be A, and the result to be B again, so we skip running it and return the cached B. With this you can start imagining how the “time traveling” durable functions work: they mock out all function calls, record their parameters and responses, and skip calls that have already been called. When they get to a “sleep” step, they save the state and schedule themselves to be re-executed in the future, trusting that the code logic will land in exactly the same place, now with the “sleep” command marked as completed and thereby able to proceed to the next step.
Now that we understand journaling, we can think about the power of durable state machines.
State machines
State machines are often thought of visually as a graph where the nodes are the “states” and the edges are the “transitions” from one state to another.
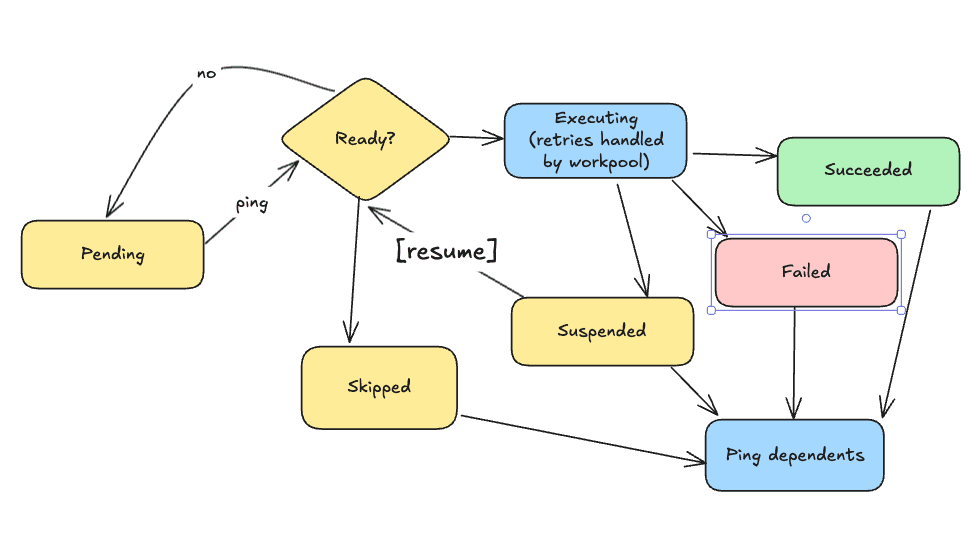 State machine for function status
State machine for function status
People love these diagrams when they’re simple, but often struggle to capture the complexity of real-world systems, often when you try to take into account failure modes. I’d argue that this isn’t a shortcoming of state machine thinking, but rather a symptom of the complexity inherent in systems that have to account for the complexity of recovering from failure at any given point.
The best engineers I’ve worked with will ruthlessly simplify the state machine of their architecture whenever possible. Instead of providing as many features as you can plausibly fit in a service, they hone in on the absolute simplest solution that will meet the requirements, then add optimizations only if necessary. When each piece of the puzzle has a small number of well-defined states, it’s easier to combine them to build higher level abstractions versus packing all the complexity into a big messy layer.
The key characteristics are:
- As small as you can get away with, but no smaller.
- Well defined: avoid cases where you’re in none of the states or some combination of them.
The second point is especially hard when you lack transactions (how do you prevent a transition spuriously happening twice?) and guaranteed execution (what if the function dies before it makes the transition?).
I decided to make a concerted effort on state machine modeling recently, in order to build my Workpool component where correctness is critical. Here’s the state machine for a job in the pile of work to complete. After a lot of iteration, I landed with the “Before” state. But it still seemed messy.
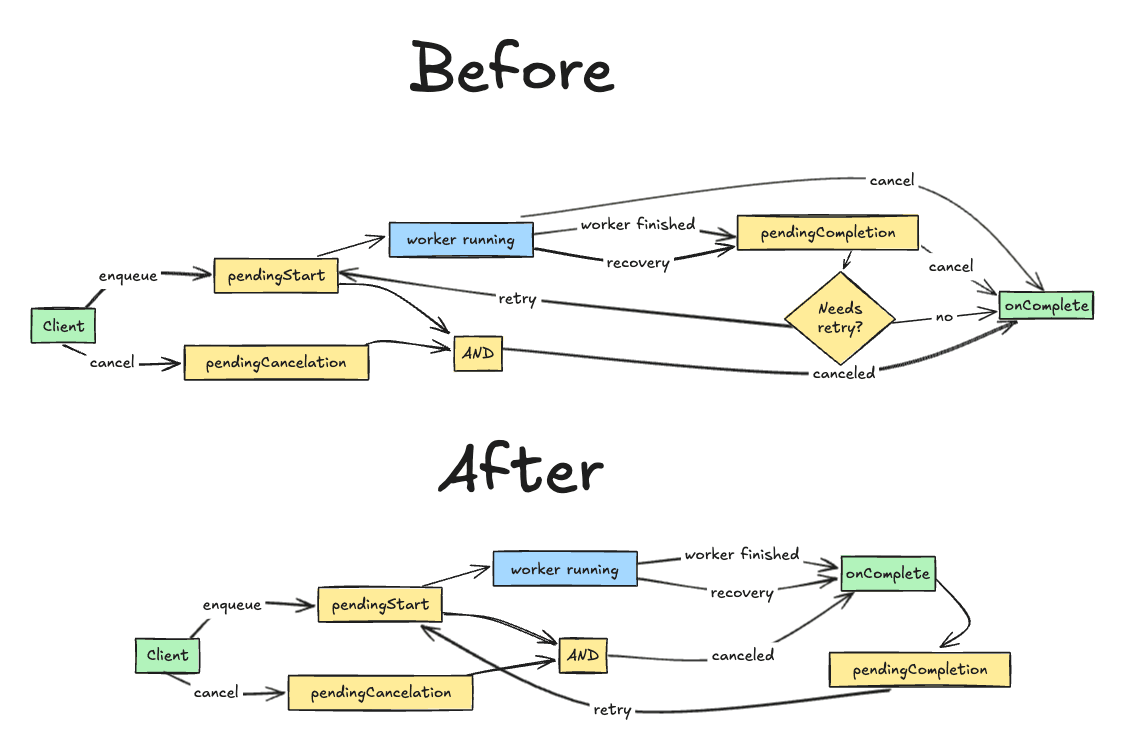
What this exercise made clear was:
- Handling cancellation from all over the place was adding complexity. And cancellation is rare!
- By only allowing cancellation before starting a job, I could simplify the flow. And if I evaluated job retries as part of that, a canceled job would execute at most once after cancellation was requested, which provided guarantees to the user about how fast they could cancel everything in the case of overload, self-inflicted or otherwise.
- Bonus: Because I put the diagram in the README, AI was able to use it to write tests for each state and transition, and caught a real bug! Without it, the generated tests would likely have assumed the bug was expected behavior
By getting precise about state machines, you can build systems whose behavior you can confidently reason about and which can guarantee invariants, which is up next.
Invariants
Congratulations for making it to the last arrow in our quiver 🏹. There isn’t much to this one. The takeaway, similar to above, is about providing guarantees that simplify reasoning about the system as a whole.
In the previous example of the state machine, I was able to delineate whose responsibility it was to progress the state at each phase.
- The client would only ever append to the
pendingStarttable, and the main loop was the sole consumer. - Workers were the only ones to append to the
pendingCompletiontable, and the main loop had full ownership of the internal state of what was considered “running.” - There is a single document field that’s transactionally updated only when calling the
onCompletehandler in the same transaction, to ensure it’s called exactly once.
By structuring my tables around simplifying invariants (guarantees), I didn’t have to worry about race conditions or edge cases around state updates. And knowing what invariants Convex provides let me not worry about cases like scheduled jobs getting lost, or enqueued when the rest of the data didn’t persist.
Ok that was a lot, so how does that all come together?
Durable workflows are the missing abstraction
Now that we have the ingredients, let’s see how they fit together in what I claim is the missing abstraction in most asynchronous or agentic apps.
While using all the above techniques will get you there, there’s an abstraction that makes a lot of the complexity fall away, leaving you to define and implement your workflows, rather than rolling your own state machine engine like I accidentally did.
Think of durable workflow as a durable function optimized for managing multi-step operations. For example:
- Connect a chain of LLM calls, with a number of tools they can use to decide what should happen next, with checkpoints between each step to allow for granular retries.
- Do a number of tasks when a user joins, from sending them an email, fetching their profile data from their auth provider, giving them access to team resources, scheduling out the emails they should get in the coming week, etc.
- Pausing workflows at steps where human input is needed, and continue on asynchronously when input is submitted.
Consider this interface, where your code can create, start, and send input to workflows, subscribe to the state(s), and get a callback when it’s done. The steps run your code, which can configure retries when they’re idempotent, leveraging journaling if need be, and generally can do what they want. When they finish (and they’re guaranteed to finish - successful or not), the durable state machine decides what to do next.
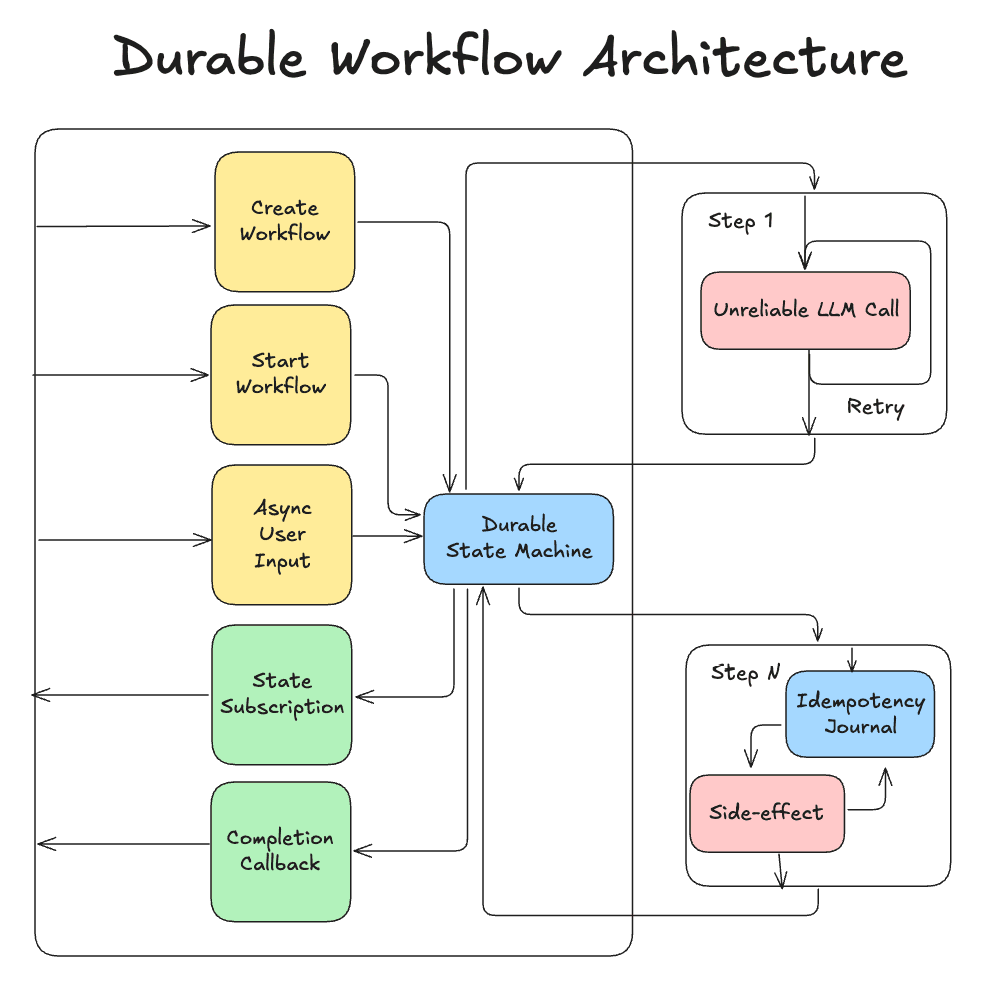
If the server restarts, it will recover and restart anything that failed and can be retried, picking up where it left off.
The user can have a subscription on the workflow step, as well as any data written by the steps. Their UI will update live as the state machine marches along in the background.
Sounds pretty nice, eh? Let’s see what it means for our original example
Revisiting our example
This code looks almost identical to the one at the start, so what’s the big deal? How is it any different?
As you can guess, this is a durable function. If it has a transient server failure or database conflict, the transaction will roll back and it will be retried automatically. The whole thing can be run as many times as you like and it will run each step to completion once once. The first time it’s run, it’ll start executing runQuery on s.customerHistory and exit early. When the query completes, the workflow will re-execute, but short-circuit on the query and pass the result back without running anything, and then start the next action. By ensuring some determinism, we can walk through the code graph one iteration at a time, and always be able to pick up where we left off.
1const s = internal.supportSteps; // Learn more about dispatching Convex functions in the docs: https://docs.convex.dev
2
3export const supportWorkflow = workflow.define({
4 args: { user: User, message: Message },
5 handler: async (ctx, { user, message }) => {
6 // 1: Fetch the customer history from the database
7 const userHistory = await step.runQuery(s.customerHistory, { user });
8 const summary = await step.runAction(s.summarizeHistoryWithAI, { message, userHistory });
9
10 // 2: Create a CX (Customer Experience) ticket with the summary for the user.
11 const ticketId = await step.runMutation(s.createTicket, { summary, user, message });
12
13 // 3. Fetch related context from a vector + transactional database
14 const context = await step.runAction(s.fetchSupportContext, { summary, message, user });
15 await step.runMutation(s.updateTicket, { ticketId, status: "in-progress", context });
16
17 // 4. Generate a proposed resolution via an LLM call with multiple tools
18 let resolution;
19 for (let i = 0; i < 5; i++) {
20 resolution = await step.runAction(s.getAIResolution, { context, userHistory, summary });
21 // Keep trying until we get a good resolution, up to 5 times
22 if (.5 < await step.runAction(s.gradeResolution, { context, resolution })) {
23 break;
24 }
25 }
26 await step.runMutation(s.updateTicket, { ticketId, status: "resolution", resolution });
27
28 // 5. Respond to the user
29 await step.runAction(s.sendUserReply, { user, message, resolution });
30 }
31});
32How does this compare to the original example?
- If it fails during either call to step 1, it is retried. If it fails overall, the workflow is guaranteed to call the
onCompletehandler (provided when starting the workflow) with the failure state. It’s safe to retry generating LLM responses. - For step 2, if there’s a database conflict, the mutation will automatically retry until it does. Since mutations are prevented from having side-effects, this is safe to do. When this returns successfully, it has been successfully written and only one ticketId has been created. If the mutation throws an exception, it’ll bubble up to the
onCompletehandler. - If it fails in step 3, it’ll retry. Here it’s important that you keep passing in the same ticketId, so each retry can idempotently update the status.
- Similar to above, each action will be retried, and if they fail, it’ll call
onComplete. TheonCompletehandler has the opportunity to decide how to handle the “in-progress” ticket. - You might want to disable retries on this one unless you pass in an idempotency ID to prevent sending multiple emails. If the
onCompletehandler sees that the ticket is closed but the user hasn’t been notified, it can write this to a log and notify a support agent to follow up.
Summary
We just looked at how incorporating these ideas can help you build with more confidence, using powerful abstractions with strong guarantees. In particular:
- State machines powered by durable functions.
- Invariants enforced in transactions.
- Retrying with idempotency.
I hope this was helpful! I just brought the Workflow component out of beta, now powered by the Workpool component for retries and parallelism management, and have ideas for DSL-style declarative alternatives. Contribute in the GitHub issue with ideas and feedback. And as always, let me know what you think in Discord, on 🦋 or on 𝕏.
[2^]: But you can rely on these failures happening in the middle of the night or whenever else is least convenient.
Footnotes
-
It may surprise you (it surprised me!) that while most databases “have transactions,” reading and writing safely is a nuanced opt-in capability that prominent ORMs don’t even provide APIs to express. ↩
-
The latter can be less certain if the API is automatically capturing requests for its “memory” for future requests, similar to using ChatGPT. ↩
-
My personal opinion is that functions that simulate time travel are magical and require a lot of nuanced thinking once you’re out of the “happy path” - such as what happens when the code changes while the function is “sleeping.” It comes with some rules akin to React’s Rules of Hooks that require you to reason backwards from how it’s implemented to avoid common pitfalls. The safest path is to make new workflows rather than modify existing ones. As an alternative, I’m excited by this definition proposal. ↩
Convex is the reactive backend platform that keeps up with you and your agents. Database, functions, workflow, sync, search, file storage, and more. All TypeScript, zero glue.