
Tutorial: How I added GitHub and npm stat counters to TanStack.com
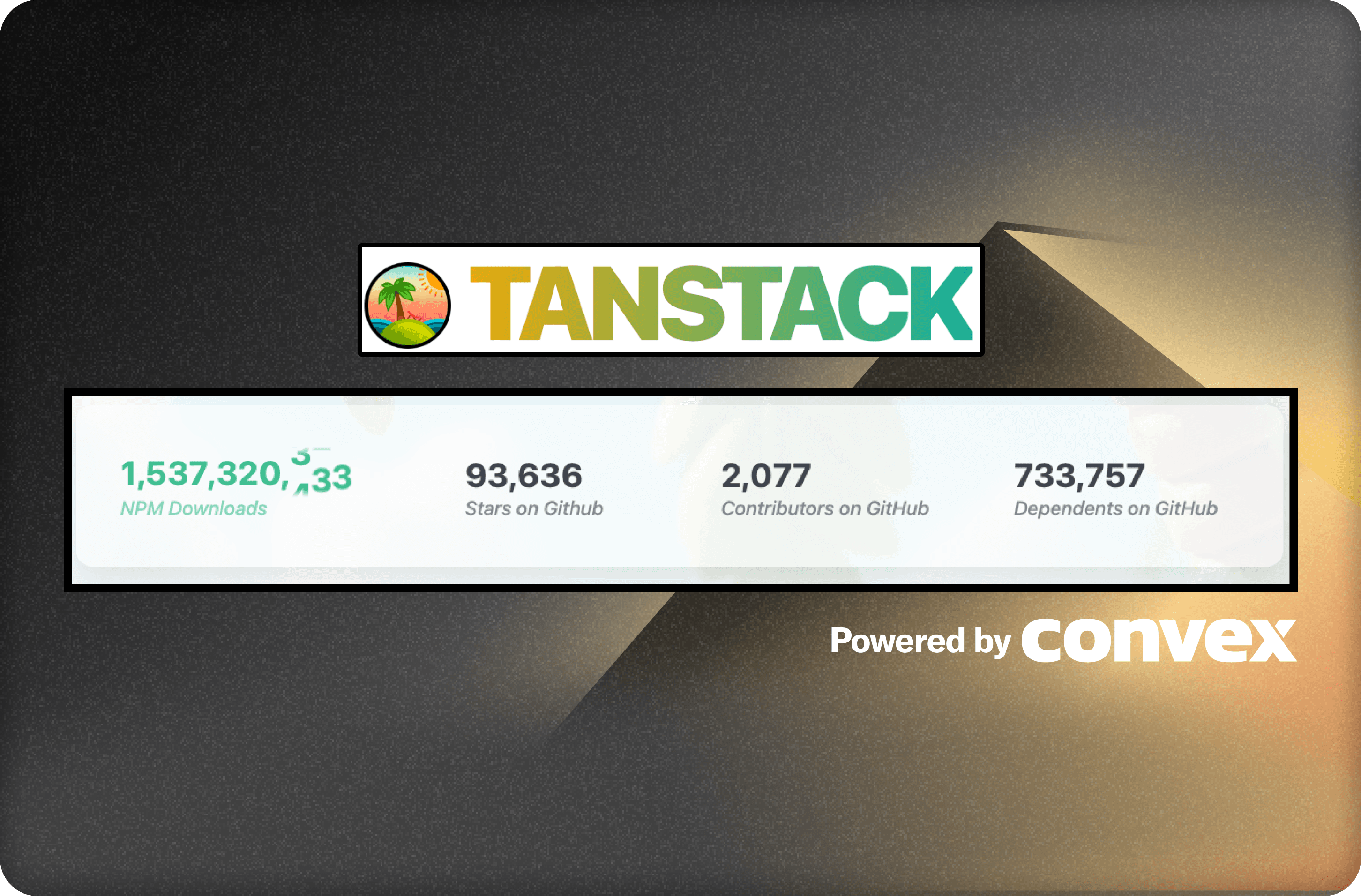
 Tutorial: How I added GitHub and npm stat counters to TanStack.com is a guest Stack Post from Convex Champion, Shawn Erquhart.
Tutorial: How I added GitHub and npm stat counters to TanStack.com is a guest Stack Post from Convex Champion, Shawn Erquhart.
In my scholarly research for this tutorial, I made a startling discovery: almost no one is putting GitHub star counts on their open source docs sites anymore. Maybe because folks don’t feel like setting up crons and webhooks to get the data. Or perhaps because it’s no longer 2005.
At any rate, this is your moment to be a trendsetter. The point of the arrow. The tip of the spear. Time to bring those counters back, people! And because Convex makes backend so ridiculously simple, it’s easier than ever.
Why tho
Okay, truth is, Tanner Linsley - probably longing for simpler times - decided putting a bunch of open source stats on Tanstack.com was the thing to do. Not just for one repo or package, but for all TanStack projects. How else will the world know that TanStack packages have been downloaded from npm over 1.5 billion times?? So he compiled the data manually and added it to the docs site.
Turns out, putting all that data together took some work. And it was immediately out of date. Clearly an opportunity to overengineer automate!
Skip to the good stuff
If you're mostly interested in getting this set up on your own site, the functionality has all been provided in a Convex Component! You can check it out on the GitHub.
If, instead, you're here to learn more than you ever wanted to know about using Convex to wrangle data that clearly does not want to be wrangled, using apis, scraping, and cron jobs, read on!
Getting started
What we'll build
This is the actual code and process I went through turning a static component on TanStack.com showing open source statistics into a set of living, breathing counters synced with Convex.
Specifically, we will build a backend service that:
- fetches and scrapes open source data for a given GitHub user/org or npm org
- stores the data in the Convex database
- serves the data through reactive queries
We'll end with a client component that fetches and displays the data
Contents
- Setup
- 01 - GitHub stars: getting simple data from an API
- 02 - GitHub stars: storing data in the database
- 03 - GitHub stars: using schemas and indexes
- 04 - GitHub contributors & dependents: scraping with Convex
- 05 - GitHub: breaking up resource intensive functions
- 06 - npm download counts
- 07 - Frontend: using Convex data in a web app
- 08 - Keep it fresh
- Quick recap
- 09 - Bonus round: npm downloads go brrrr
Setup
This tutorial has a repository counterpart for following along in your own editor, plus runnable code for each step. Run these commands to get set up:
-
Clone the repo
1git clone https://github.com/erquhart/convex-oss-stats-tutorial 2 -
Install dependencies
1npm install 2 -
Set up your Convex project
1npx convex dev --configure new 2
You'll write your Convex code in the /convex directory, and the /steps directory contains the end state of each tutorial step for comparison or skipping ahead. The steps are also runnable.
Commands
The repo provides a few commands via npm scripts:
1npm run dev
2Runs your own Convex code from the /convex directory
1npm run step-02
2Runs a specific step, eg., step-01, step-02, etc, without impacting your working directory in /convex
1npm run diff-02
2Runs a git diff that shows the difference between the given step and the step before it, eg., diff-02, diff-03, etc
1npm run clear-db
2Clears out your database. This is helpful sometimes if you switch back and forth between steps and the data becomes invalid, or if you just want a clean slate.
How to use this tutorial
You can start from scratch following along and writing code in the /convex directory, or you can copy the code from any of the steps in the /steps directory to skip ahead.
For each section, you can run npm run step-<num> to run the step’s code provided by the tutorial, or npm run diff-<num> to see the changes that should be made for a given step, which may be helpful for skimming or comparing to your own code in the root directory.
01 - GitHub stars: getting simple data from an API
Hint: Before you start, always make sure you’re connected to your Convex development server during local development by running npm run dev. This ensures your changes in the /convex directory are always deployed. You should also watch this terminal for errors that might block deployment.
API credentials
We’ll start with the GitHub API. First you’ll need to generate a personal access token - you can use one of their new “fine-grained” tokens with default settings, you’ll only need it to access public repositories. You can create one here: https://github.com/settings/personal-access-tokens/new
Once you have it, from your project root, you can set it to an environment variable on your Convex dev deployment:
1npx convex env set GITHUB_ACCESS_TOKEN <token>
2Fetching data
We want to gather the number of stars for each repository that a user (or org) owns. GitHub's REST api provides an endpoint for listing repositories, and includes number of stars under the stargazers_count property: https://docs.github.com/en/rest/repos/repos?apiVersion=2022-11-28#list-repositories-for-a-user
Since we're writing our backend in TypeScript, we can use GitHub's OctoKit library rather than just fetching raw, untyped data. We'll use Octokit's REST endpoint methods, in particular octokit.rest.repos.listForOrg, which calls the endpoint linked above.
A Convex function can be a query, mutation, or action (we'll get into each). Queries and mutations are for interacting with the database, but they can't make api calls - for that, you need an action. We'll start with an action that gets all the repo data for a user, adds up the star count, and logs the total to the console.
1// convex/stats.ts
2import { Octokit } from "octokit";
3import { internalAction } from "@/_generated/server";
4
5export const updateGithubOwnerStats = internalAction(async (ctx, args) => {
6 const octokit = new Octokit({ auth: process.env.GITHUB_ACCESS_TOKEN });
7 const { data: repos } = await octokit.rest.repos.listForUser({
8 username: args.owner,
9 });
10 let ownerStarCount = 0;
11 for (const repo of repos) {
12 ownerStarCount += repo.stargazers_count ?? 0;
13 }
14 console.log(`${args.owner} has ${ownerStarCount} stars`);
15});
16That's all it takes to get data from an external api with Convex. We're using internalAction instead of action because we don't want this function to be publicly accessible. It can only be called by other functions, or directly through the Convex dashboard or via CLI. But before we run the function, let's check out that red, squiggly line.
Argument validation
You'll notice we have a type error - Octokit's listForUser method is complaining about args.owner being type unknown instead of string. The args object is an object of arguments that is passed to our Convex function, and we've written this function to expect an owner property. How do we make the arguments type safe so listForUser() knows we’re passing it a string? Argument validation!
Let's update our function to validate arguments.
1export const updateGithubOwnerStats = internalAction({
2 args: { owner: v.string() },
3 handler: async (ctx, args) => {
4 // ...
5 }
6})
7Instead of passing a function to internalAction(), we passed an object with args and handler properties. The handler is the same function we already defined with no changes, and the args property explicitly declares how the arguments object must be shaped. Not only does this add type safety to args in the handler function, but the action will throw if called with arguments that don't pass validation. We now have type safety enforced at runtime 💪.
Running a function from the dashboard
Let's call our action! The dashboard is full of useful functionality for developing an app on Convex. If you run npx convex dashboard in your project root, your browser will open to the correct project. From there, you can navigate to the Functions tab and call our updateGithubOwnerStats action.
Note: when you run the function, be sure to provide an "owner" value, like "tanstack".
Running a function from the CLI
You can also run this in the CLI to see the logs print out in the terminal running the dev server:
1npx convex run stats:updateGithubOwnerStats '{ "owner": "tanstack" }'
2As of this writing, the TanStack GitHub org has 17 repositories, so this function works fine. If they had more than 30, the function would not have counted all of the repos. We can tell octokit to return up to 100 repos in one call, but we'll need to use pagination if we want to handle more than 100. Since we don't want this to break if the TanStack org ever hits this milestone, let's add pagination now.
1// ...
2export const updateGithubOwnerStats = internalAction({
3 args: { owner: v.string() },
4 handler: async (ctx, args) => {
5
6 // Add this iterator
7 const iterator = octokit.paginate.iterator(octokit.rest.repos.listForUser, {
8 username: args.owner,
9 per_page: 100,
10 });
11
12 let ownerStarCount = 0;
13
14 // Add an extra level of looping for the pages from the iterator
15 for await (const { data: repos } of iterator) {
16 for (const repo of repos) {
17 ownerStarCount += repo.stargazers_count ?? 0;
18 }
19 }
20// ...
21Our function is now more future proof. Next we'll do something more useful than logging stuff to the console.
02 - GitHub stars: storing data in the database
We want to plan our data storage based on real use cases. For the TanStack project we want to take in a GitHub user/org and produce a total number of stars. We know that we'll also be storing npm data, so let's keep the total star count in a githubOwners table for storing GitHub owner data specifically.
As I mentioned earlier, Convex actions don't interact with the database directly, but they can call queries or mutations and wait for a result. Let's create a mutation that writes our GitHub owner data to the database.
1// convex/stats.ts
2export const updateGithubOwner = internalMutation({
3 args: {
4 name: v.string(),
5 starCount: v.number(),
6 },
7 handler: async (ctx, args) => {
8 await ctx.db.insert("githubOwners", args)
9 },
10});
11This mutation accepts an object with name and starCount properties. It will throw if either of those arguments are missing or are of the wrong type. The ctx.db.insert() function creates a new record in the githubOwners table using the arguments as values.
Notice, we never did anything to explicitly define a table. There's no schema. Convex will create the named table if it doesn't exist and insert the records with no extra steps required. Obviously we want more safety than this in production, but it's handy to be able to quickly get started without pinning down a schema.
Now we'll update our action to call the mutation with the GitHub owner name and total star count.
1// convex/stats.ts
2export const updateGithubOwnerStats = internalAction({
3 args: { owner: v.string() },
4 handler: async (ctx, args) => {
5
6 // ...previous code to get owner star count
7
8 await ctx.runMutation(internal.stats.updateGithubOwner, {
9 owner: args.owner,
10 starCount: ownerStarCount,
11 });
12 },
13});
14Your project dashboard should now look something like this:

Creating unique fields with upserts
Running our action creates the data we expect, but what happens if we run it again? This function will need to run regularly to keep data fresh, and as it stands, we'll get a new "tanstack" record every time it runs. The name field should be unique - how do we do that in Convex?
Like many concepts in Convex, it's less about learning Convex conventions and more about thinking through how to accomplish your goal in code. There's no "unique" setting. So we want to update our mutation to enforce uniqueness logically. It should:
- Check for an existing record with a given name
- If that record exists, get it and update it
- If the record doesn't exist, insert a new one
In other words, we need an “upsert”.
Let's update our mutation to provide guaranteed uniqueness for the name field in our githubOwners table.
1// convex/stats.ts
2export const updateGithubOwner = internalMutation({
3 // ...args
4 handler: async (ctx, args) => {
5 const existingOwner = await ctx.db
6 .query("githubOwners")
7 .filter((q) => q.eq(q.field("name"), args.name))
8 .unique();
9
10 if (!existingOwner) {
11 await ctx.db.insert("githubOwners", args)
12 return;
13 }
14
15 await ctx.db.patch("githubOwners", existingOwner._id, args)
16 },
17});
18To check for an existing record for a given owner name, we're using .filter() to
retrieve only records that match the name arg, and we're using .unique() because there should never be more than one result for this query, so we want to throw an error if there are multiple. Note that .unique() does not maintain uniqueness at all, it's just a tool for asserting uniqueness in our queries.
We then insert a record as before if no match is found, or we use ctx.db.patch() to update the star count on the existing record.
Note: If you already had multiple "tanstack" records from running the function multiple times, this function will now error due to .unique() encountering multiple records in the query. You can hit the dashboard and manually delete the extras, or run npm run clear locally to clear out the database.
We now have an idempotent upsert that can create or update the total star count for a GitHub org in our database! But we're also pulling useful data from the API that we aren't capturing - the star count of individual repos in the org. Let's add that in next.
Remember: You can run the tutorial code from this step separately from your own code by running npm run step-02, or view the diff to see changes that this step introduces for comparison to your own code by running npm run diff-02.
03 - GitHub stars: storing even more data in the database
Composite unique constraints
We want the option to get the star counts of the individual repos for a user/org, and not just the total. We're already getting the data for this, let's store it in a githubRepos table.
1// convex/stats.ts
2import { asyncMap } from "convex-helpers";
3// ...
4
5export const updateGithubRepos = internalMutation({
6 args: {
7 repos: v.array(
8 v.object({
9 owner: v.string(),
10 name: v.string(),
11 starCount: v.number(),
12 })
13 ),
14 },
15 handler: async (ctx, args) => {
16 await asyncMap(args.repos, async (repo) => {
17 const existingRepo = await ctx.db
18 .query("githubRepos")
19 .filter((q) =>
20 q.and(
21 q.eq(q.field("owner"), repo.owner),
22 q.eq(q.field("name"), repo.name)
23 )
24 )
25 .unique();
26 if (existingRepo?.starCount === repo.starCount) {
27 return;
28 }
29 if (existingRepo) {
30 await ctx.db.patch("githubRepos", existingRepo._id, repo)
31 return;
32 }
33 await ctx.db.insert("githubRepos", repo);
34 });
35 },
36});
37The updateGithubRepos mutation is similar to the updateGithubOwner mutation, but introduces a few new tricks:
- it receives a list of objects (notice
v.array()in the args) instead of a single object - it uses
asyncMapfrom the convex-helpers library to loop over the list of repos in parallel - it uses
q.and()in the filter to combine two equality checks
Because the filter in our repo upsert is checking equality in two fields, we'll have uniqueness on the combination of owner and name. Two repos may have the same name, or the same owner, but two repos will not have the same owner/name combination (as long as this upsert is the only function used to update the table).
Now we need to call it from `updateGithubOwnerStats``:, which is effectively our entry point:
1// convex/stats.ts
2
3export const updateGithubOwnerStats = internalAction({
4 args: { owner: v.string() },
5 handler: async (ctx, args) => {
6
7 // ...
8
9 for await (const { data: repos } of iterator) {
10 // ...
11 await ctx.runMutation(internal.stats.updateGithubRepos, {
12 repos: repos.map((repo) => ({
13 owner: repo.owner.login,
14 name: repo.name,
15 starCount: repo.stargazers_count ?? 0,
16 })),
17 });
18 }
19 // ...
20 },
21});
22Apart from the looping, there's not much new here. But we now have star counts for individual repos in the org 🙌
Using a schema and indexes to hyper optimize queries
As I mentioned earlier, the TanStack org has 17 repositories as of this writing. A pretty light load. This feels like a good time to put just a little stress on the system. Nothing extreme, but we want to make sure it works at realistic volume. Convex's GitHub org has a little over a hundred, at least enough to need more than one page from GitHub's list repos api.
Let's see how it handles our action with both TanStack and Convex GitHub data in the database.
Try it out:
1npx convex run stats:updateGithubOwnerStats '{ "owner": "tanstack" }' &&
2npx convex run stats:updateGithubOwnerStats '{ "owner": "get-convex" }'
3Lo and behold, no error, but we do have a warning 👀
1[CONVEX M(stats:updateGithubRepos)] [WARN] Many documents read in a single function execution (actual: 13700, limit: 16384). Consider using smaller limits in your queries, paginating your queries, or using indexed queries with a selective index range expressions.
2What's happening here?
Queries and mutations have a 16,384 document limit - they cannot read more than this number of documents in a single call. Now, we have a githubOwners table with 2 records and a githubRepos table with a little over 100 records, how did we even come close to this limit?
Take a closer look at this ctx.db.query() call that we just introduced:
1 await asyncMap(args.repos, async (repo) => {
2 const existingRepo = await ctx.db
3 .query("githubRepos")
4 .filter((q) =>
5 q.and(
6 q.eq(q.field("owner"), repo.owner),
7 q.eq(q.field("name"), repo.name)
8 )
9 )
10 .unique();
11We should note two things that are happening here:
args.repois an array with up to 100 objects (a single page from GitHub's api)ctx.db.query()calls that end with.collect()or.unique()will read every document in the table, filter only limits the result set after everything is read
So the warning is reflecting that we have a total of 137 records in the repos table, and the updateGithubRepos mutation is reading all of them once for each of 100 repos in the array. 137 * 100 = 13,700.
We can limit the number of documents read in our query by using an index. You can think of an index as a way to create synced, pre-filtered copies of a table. A query can then use these smaller copies so there are less documents to read. We'll walk through creating an index for this use case to understand indexes a bit more.
So far we've been working without a schema, so we can put pretty much anything in the database and it's allowed. A schema defines what tables exist, what fields those tables have, and what kinds of values are acceptable for those fields.
Creating a schema
Let's create convex/schema.ts and make a schema reflecting the tables and fields we have so far.
1// convex/schema.ts
2import { defineSchema, defineTable } from "convex/server";
3import { v } from "convex/values";
4
5export default defineSchema({
6 githubOwners: defineTable({
7 name: v.string(),
8 starCount: v.number(),
9 })
10 githubRepos: defineTable({
11 owner: v.string(),
12 name: v.string(),
13 starCount: v.number(),
14 })
15});
16If you noticed, our schema uses the same validator functions as our Convex function arguments! This schema defines our two tables and the types of the fields in a pretty self explanatory way.
Now let's add the index we need to fix our warning.
Using indexes
Our index is a one-liner:
1// convex/schema.ts
2
3// ...
4
5export default defineSchema({
6 // ...
7 githubRepos: defineTable({
8 owner: v.string(),
9 name: v.string(),
10 starCount: v.number(),
11 }).index('owner_name', ['owner', 'name'])
12});
13We've given our index the name "owner_name", but there's nothing special about it, you can name them whatever you want. Naming an index after the fields it uses is just a convention, and it's helpful because it's self-documenting. The definition of the index is an array of one or more field names.
Earlier I mentioned indexes being like a synced, pre-filtered collection of copies of a table. With this index, Convex will (effectively) create a copy of the githubRepos table for every unique owner/name combination in the database. But we're using our upsert approach to ensure that there's only one record for each owner/name combination, so what does that mean?
Among those synced, pre-filtered table copies will be one for each owner/name combination, and will have exactly one record. So our query that was reading 137 records to get 1 specific record will now be reading exactly 1 record. This makes the query incredibly fast, cheap, and ensures we'll never come close to the limit we were warned about.
Let's replace our filter with the index:
1// convex/stats.ts
2
3// ...
4
5export const updateGithubRepos = internalMutation({
6 // ...
7 handler: async (ctx, args) => {
8 await asyncMap(args.repos, async (repo) => {
9 const existingRepo = await ctx.db
10 .query("githubRepos")
11 .withIndex("owner_name", (q) =>
12 q.eq("owner", repo.owner).eq("name", repo.name)
13 )
14 .unique();
15 // ...
16 })
17// ...
18In withIndex() we're using the index we just created by name. Notice that we're referencing the fields in the same order they appear in the schema. This is required. You don't have to reference every field in an index when you use it, but you do have to reference them in order starting with the first field. In this case we're using q.eq() to limit our query to documents whose owner
field is equal to args.owner, and whose name field is equal to repo.name.
Using the index this way ensures we get the performance described earlier - because we're constraining records to have a unique owner/name combination, this query will only have to read one record. We've just reduced 13,700 reads to 137 reads! 🔥
It's fine to just filter your way through when you're early developing an app, but you'll want indexes everywhere they can be used in production. Let's go ahead and add an index for our other query while we're here.
1// convex/schema.ts
2
3// ...
4
5export default defineSchema({
6 // ...
7 githubOwners: defineTable({
8 name: v.string(),
9 starCount: v.number(),
10 }).index("name", ["name"]),
11});
121// convex/stats.ts
2
3// ...
4
5export const updateGithubOwner = internalMutation({
6 // ...args
7 handler: async (ctx, args) => {
8 const existingOwner = await ctx.db
9 .query("githubOwners")
10 .withIndex("name", (q) => q.eq("name", args.name))
11 .unique();
12 // ...
13})
14Type safe queries with schemas
Bonus: now that we've added a schema, our ctx.db.query() results are no longer type any - they're fully typed! And when we introduce a frontend, those types will carry through to the client, too.
04 - GitHub contributors & dependents: scraping with Convex
We're interested in two more pieces of data from GitHub - the number of contributors per repo/owner, and the number of dependents per repo/owner. There is technically a way to get number of contributors through GitHub's api, but it involves paging through an array of large user objects for every single contributor. So for a single repo with 500 contributors, we would have to call this endpoint 5 times pulling 100 contributors each time, fetching a large amount of data just to count the number of items in the array.
If someone has a better way please let me know.
Dependents count, on the other hand - repositories that depend on a given repository's package(s) - are only publicly available on the website, so we'll have to scrape it. And since the number of contributors is right there on the same site, we'll keep it simple and scrape 'em both.
Scraping data from a website
I'm going to avoid turning this into a primer on scraping, as there's plenty of info on the web covering that. Here's a function that does what we need without trying to be too sophisticated:
- Accepts an owner name and repo name
- Fetches the associated GitHub repo page from github.com
- Uses cheerio to parse the site html
- Uses a css selector to locate the elements with the counts we're looking for
- Retries up to 3 times if expected data isn't found
- Returns an object with
contributorCountanddependentCount
1// convex/stats.ts
2import * as cheerio from "cheerio";
3
4const repoPageRetries = 3;
5
6const getGithubRepoPageData = async (owner: string, name: string) => {
7 let retries = repoPageRetries;
8 let contributorCount: number | undefined;
9 let dependentCount: number | undefined;
10 while (retries > 0) {
11 const html = await fetch(`https://github.com/${owner}/${name}`).then(
12 (res) => res.text()
13 );
14 const $ = cheerio.load(html);
15 const parseNumber = (str = "") => Number(str.replace(/,/g, ""));
16 const selectData = (hrefSubstring: string) => {
17 const result = $(`a[href$="${hrefSubstring}"] > span.Counter`)
18 .filter((_, el) => {
19 const title = $(el).attr("title");
20 return !!parseNumber(title);
21 })
22 .attr("title");
23 return result ? parseNumber(result) : undefined;
24 };
25 contributorCount = selectData("graphs/contributors") ?? 0;
26 dependentCount = selectData("network/dependents") ?? 0;
27 if (contributorCount === undefined || dependentCount === undefined) {
28 retries--;
29 continue;
30 }
31 break;
32 }
33 return {
34 contributorCount,
35 dependentCount,
36 };
37};
38
39// ...
40We can call this for each repo we get from the GitHub api to get an object with contributorCount and dependentCount properties, perfect.
Dealing with flaky data
One issue, though: scraping is inherently flaky. Websites aren't api's and what you can get in the html doesn't carry the same guarantees that an api would. In this case, we're seeing that the numbers we want sometimes just aren't in the dom, even when we use retries to make multiple attempts.
Our current approach works like this:
- scrape websites for a GitHub user's repos
- some of them are missing data
- add up the totals for contributors and dependents
- store that total on the owner
If we run this same function for the same owner multiple times, we'll often get different results, and then the total on the owner will compound those differences. We need a way to keep good data and get rid of the bad. There's no perfect solution here, but we can at least optimize for consistency. Let's change our approach in a couple of ways:
- For each repo, compare the contributor and dependent counts from the scraper to the number we already have in the database
- If the number we already have is above zero, and the new number is zero, keep the number we have
- Instead of summing up the scraped numbers each time to get totals for the GitHub user/org, we should sum up the numbers from the database after conditionally updating the data for each repo from our scraping results
With this approach, missing data will eventually fill in the more we run the function, and should stay relatively close to the correct numbers if we run it regularly.
First let’s update the repos mutation to keep the existing value if the new value is zero:
1// convex/stats.ts
2export const updateGithubRepos = internalMutation({
3 // ...
4 handler: async (ctx, args) => {
5 await asyncMap(args.repos, async (repo) => {
6 const existingRepo = await ctx.db
7 .query("githubRepos")
8 .withIndex("owner_name", (q) =>
9 q.eq("owner", repo.owner).eq("name", repo.name)
10 )
11 .unique();
12 if (
13 existingRepo?.starCount === repo.starCount &&
14 existingRepo?.contributorCount === repo.contributorCount &&
15 existingRepo?.dependentCount === repo.dependentCount
16 ) {
17 // noop if no changes
18 return;
19 }
20 if (existingRepo) {
21 await ctx.db.patch("githubRepos", existingRepo._id, {
22 starCount: repo.starCount || existingRepo.starCount,
23 contributorCount:
24 repo.contributorCount || existingRepo.contributorCount,
25 dependentCount: repo.dependentCount || existingRepo.dependentCount,
26 });
27 return
28 }
29 await ctx.db.insert("githubRepos", repo);
30 });
31 },
32});
33Then we’ll rework updateGithubOwner to get totals for a given owner by summing up it’s own repo stats from the database:
1// convex/stats.ts
2export const updateGithubOwner = internalMutation({
3 args: { name: v.string() },
4 handler: async (ctx, args) => {
5 // Retrieve the owner or insert a new one if it doesn't exist,
6 // get the id to use with patch later
7 const ownerId =
8 (
9 await ctx.db
10 .query("githubOwners")
11 .withIndex("name", (q) => q.eq("name", args.name))
12 .unique()
13 )?._id ??
14 (await ctx.db.insert("githubOwners", {
15 name: args.name,
16 starCount: 0,
17 contributorCount: 0,
18 dependentCount: 0,
19 }));
20
21 const repos = await ctx.db
22 .query("githubRepos")
23 .withIndex("owner", (q) => q.eq("owner", args.name))
24 .collect();
25
26 const { starCount, contributorCount, dependentCount } = repos.reduce(
27 (acc, repo) => ({
28 starCount: acc.starCount + repo.starCount,
29 contributorCount: acc.contributorCount + repo.contributorCount,
30 dependentCount: acc.dependentCount + repo.dependentCount,
31 }),
32 { starCount: 0, contributorCount: 0, dependentCount: 0 }
33 );
34
35 await ctx.db.patch("githubOwners", ownerId, {
36 starCount,
37 contributorCount,
38 dependentCount,
39 });
40 },
41});
42Our updateGithubOwner mutation now only accepts an owner name. It fetches all of the owner’s repos from the database, totals up their stats, and writes the totals to the owner record.
Let’s update our entry point now that we no longer need it to total up repo stats.
1// convex/stats.ts
2export const updateGithubOwnerStats = internalAction({
3 args: { owner: v.string() },
4 handler: async (ctx, args) => {
5 const octokit = new Octokit({ auth: process.env.GITHUB_ACCESS_TOKEN });
6 const iterator = octokit.paginate.iterator(octokit.rest.repos.listForUser, {
7 username: args.owner,
8 per_page: 100,
9 });
10
11 for await (const { data: repos } of iterator) {
12 const repoLimit = pLimit(10);
13 const reposWithPageData = await asyncMap(repos, async (repo) => {
14 return repoLimit(async () => {
15 const pageData = await getGithubRepoPageData(args.owner, repo.name);
16 return {
17 owner: args.owner,
18 name: repo.name,
19 starCount: repo.stargazers_count ?? 0,
20 contributorCount: pageData.contributorCount,
21 dependentCount: pageData.dependentCount,
22 };
23 });
24 });
25
26 await ctx.runMutation(internal.stats.updateGithubRepos, {
27 repos: reposWithPageData,
28 });
29 }
30 await ctx.runMutation(internal.stats.updateGithubOwner, {
31 name: args.owner,
32 });
33 },
34});
35This change simplified our entry point quite a bit as it’s no longer tracking totals as we page through data, and the resulting data in our tables will be much more consistent.
One more thing we should look at here before moving on is the workload for updateGithubOwner. It uses ctx.db.query().collect() to pull in all documents for a given owner from the githubRepos table. This works for orgs with a few hundred repos or less, but will break if someone tries running it against the Microsoft org with it’s 6,000+ repos.
We also want to limit how many pages we’re scraping in a single action run, just to stay within function memory limits.
In the next section we’ll make all of this durable enough to work with any org.
05 - GitHub: breaking up resource intensive functions
We have a function to pull and store all of the GitHub data we want, and it works really well! But we have two areas of concern for users and orgs with many repositories.
- Our entry point,
updateGithubOwnerStats, scrapes an unbounded number of pages from the GitHub website, which could max out memory. - Our
updateGithubOwnermutation queries and inserts/patches an unbounded number of records from thegithubRepostable, a number that could go into the thousands.
We can’t reduce the amount of work we’re doing, it’s all necessary, but we can break it up into multiple function calls so we avoid hitting memory limits. To enable this, Convex allows functions to schedule functions (including themselves!) ✨
Splitting heavy functions with scheduling
Our entry point can be broken up pretty simply:
- Instead of paging through repos from the GitHub api, each call to our entry point will retrieve a single page based on a new
pagearg - After fetching the data and updating the
githubRepostable, if there is more data, our entry point will schedule itself to run again immediately, and then exit - Once we’ve fetched all pages, we can run
updateGithubOwnerto update our totals
Let’s update our entry point with this strategy. First, let’s zoom in on the data fetching part.
Side quest: fetching one page at a time
I thought this would be the part that would require almost no change, but it turns out that Octokit does not support fetching single pages from the REST api. The paginate function does accept a page arg, but it will start from that page and fetch all pages after 🤷♂️.
Then I thought “hey, we’re pulling way more data than we need anyway, let’s use graphql!”. Their graphql api accepts a cursor, so we can get just one page, and since we can have it return exactly the data we need, data over the wire will be a very small fraction of we’re getting from the rest api. It’ll probably be even faster, right?
Nope. Don’t get me started on graphql, but it takes 3 times as much code 3 times as long to get an amount of data 1% the size of what we’re fetching from the rest api. To be fair, this is probably because rest is highly cacheable and graphql is not. So! Looks like we’re dropping Octokit and using good ol’ fetch(). Here’s that part:
1export const updateGithubOwnerStats = internalAction({
2 args: {
3 owner: v.string(),
4 page: v.optional(v.number()),
5 },
6 handler: async (ctx, args) => {
7 const page = args.page ?? 1;
8 const response = await fetch(
9 `https://api.github.com/users/${args.owner}/repos?per_page=100&page=${page}`,
10 {
11 headers: {
12 Authorization: `Bearer ${process.env.GITHUB_ACCESS_TOKEN}`,
13 },
14 }
15 );
16 const repos: { name: string; stargazers_count: number }[] =
17 await response.json();
18 // ...
19We’re now accepting an optional page arg with a page number to use in our GitHub api fetch, which gets us a single page of repos. Now to process the data:
1 // ...
2 if (repos.length === 0) {
3 await ctx.runMutation(internal.stats.updateGithubOwner, {
4 name: args.owner,
5 });
6 return;
7 }
8
9 const repoLimit = pLimit(10);
10 const reposWithPageData = await asyncMap(repos, async (repo) => {
11 return repoLimit(async () => {
12 const pageData = await getGithubRepoPageData(args.owner, repo.name);
13 return {
14 owner: args.owner,
15 name: repo.name,
16 starCount: repo.stargazers_count ?? 0,
17 contributorCount: pageData.contributorCount,
18 dependentCount: pageData.dependentCount,
19 };
20 });
21 });
22
23 await ctx.runMutation(internal.stats.updateGithubRepos, {
24 repos: reposWithPageData,
25 });
26 //...
27
28We have an early exit after we fetch the page of repos - if it’s empty, we run our updateGithubOwner mutation and exit. If not, we do the same processing we did before, scraping additional data for each repo and collecting it all into a new array, and then calling our updateGithubRepos mutation to store the result.
Lastly, let’s do the scheduling part:
1 // ...
2 await ctx.scheduler.runAfter(0, internal.stats.updateGithubOwnerStats, {
3 owner: args.owner,
4 page: page + 1,
5 });
6 });
7 // ...
8At the end of the action, we use ctx.scheduler.runAfter() to schedule our entry point to run again after 0 milliseconds with an updated page arg. Here’s the whole thing:
1export const updateGithubOwnerStats = internalAction({
2 args: {
3 owner: v.string(),
4 page: v.optional(v.number()),
5 },
6 handler: async (ctx, args) => {
7 const page = args.page ?? 1;
8 const response = await fetch(
9 `https://api.github.com/users/${args.owner}/repos?per_page=100&page=${page}`,
10 {
11 headers: {
12 Authorization: `Bearer ${process.env.GITHUB_ACCESS_TOKEN}`,
13 },
14 }
15 );
16 const repos: { name: string; stargazers_count: number }[] =
17 await response.json();
18
19 if (repos.length === 0) {
20 await ctx.runMutation(internal.stats.updateGithubOwner, {
21 name: args.owner,
22 });
23 return;
24 }
25
26 const repoLimit = pLimit(10);
27 const reposWithPageData = await asyncMap(repos, async (repo) => {
28 return repoLimit(async () => {
29 const pageData = await getGithubRepoPageData(args.owner, repo.name);
30 return {
31 owner: args.owner,
32 name: repo.name,
33 starCount: repo.stargazers_count ?? 0,
34 contributorCount: pageData.contributorCount,
35 dependentCount: pageData.dependentCount,
36 };
37 });
38 });
39
40 await ctx.runMutation(internal.stats.updateGithubRepos, {
41 repos: reposWithPageData,
42 });
43
44 await ctx.scheduler.runAfter(0, internal.stats.updateGithubOwnerStats, {
45 owner: args.owner,
46 page: page + 1,
47 });
48 },
49});
50Because we’ve solved this at the entry point level, the problem of unbounded mutation size mentioned earlier is also solved. We now have a recursive entry point that can safely page through an unbounded number of repositories. I tested this out on Microsoft’s 6,000+ repos and, while it took ~16 minutes, it did work! Fun fact: they have 3M stars and 75k contributors. Crazy.
That’s it for GitHub data! Next we’ll move onto our final data point: npm downloads.
06 - npm downloads
npm downloads is a special stat compared to the others. It’s generally going to be the largest number associated with an open source project, one that is literally going up constantly for even a moderately known project. This is the one going brrrr on Tanstack.com. Let’s get into the data!
Getting the data
We want to get the total number of npm downloads per package, and in total, for a given npm org. (Note, users are not supported for npm, as there is no concept of ownership in npm apart from orgs). While not nearly as robust and well documented as GitHub’s api’s, npm does maintain one for public use, and it includes endpoints for download counts: https://github.com/npm/registry/blob/main/docs/download-counts.md
The data situation here is complicated. The good news is, we have an api! The less good news is:
- There’s no endpoint that provides a list of packages for a given npm org
- The download counts api used to provide an all time endpoint, but as you can see in the raw code of the api doc, that endpoint has been disabled
- The remaining download count endpoints are limited to 18 months of data per request and don’t go further back than 2015.
- Download data is only updated every 24 hours, no data is available in between, and the realtime dream is dead :sad-cowboy: (the sad cowboy emoji should really be standard at this point, what are we even doing)
We don’t have an ideal dataset, but we do have what we need to put together pretty solid numbers. The only thing actually missing is the list of packages for an org. The website does have this list, but it’s paginated if large, so we’d be scraping and paging, and pulling a lot more scraped data than the very minimal digits we’re getting for GitHub data.
A bit of digging in the console found that the list powering this page is served as raw data to the frontend! After playing with the headers a bit I was able to request the data direct from their server. Hopefully that will remain the case! 😅
So our strategy for getting this data should look something like:
- Pull the list of packages for the org from npm’s server
- Fetch the daily download counts for each package from the api, making multiple calls when needed to account for the 18 month range limit per call
- Store per package and total download numbers in the database
The fetching here will take more code than was required for GitHub, so we’ll break things down a bit more. Let’s start with a function for pulling the list of packages for an owner.
1// convex/stats.ts
2// ...
3const fetchNpmPackageListForOrg = async (org: string, page: number) => {
4 const response = await fetch(
5 `https://www.npmjs.com/org/${org}?page=${page}`,
6 {
7 // The headers are based on experimenting with the ones used
8 // by [npmjs.org](http://npmjs.org) to determine which are required to get a json
9 // data response - without the headers the site html is
10 // returned instead.
11 headers: {
12 "cache-control": "no-cache",
13 "x-spiferack": "1",
14 },
15 }
16 );
17 // Partial type for the bits we're interested in
18 const data: {
19 scope: { type: "org" | "user" };
20 packages?: {
21 objects: { name: string; created: { ts: number } }[];
22 urls: { next: string };
23 };
24 message?: string;
25 } = await response.json();
26 if (!data.packages && data.message === "NotFoundError: Scope not found") {
27 throw new Error(`npm org ${org} not found`);
28 }
29 if (data.scope.type === "user") {
30 throw new Error(`${org} is a user, not an org`);
31 }
32 if (!data.packages) {
33 throw new Error(`no packages for ${org}, page ${page}`);
34 }
35 return {
36 packages: data.packages.objects.map((pkg) => ({
37 name: pkg.name,
38 created: pkg.created.ts,
39 })),
40 // packages.urls.next contains a query string to use in the next
41 // request, or else it's undefined. We're incrementing the page
42 // number through args so we just use this to determine whether
43 // there are more pages.
44 hasMore: !!data.packages.urls.next,
45 };
46};
47// ...
48As far as I can tell, this endpoint doesn’t accept page size configuration and always sends back pages of 25. This works fine for our purposes.
Next let’s write a function that fetches all of the download count data for a single package and totals them up. The package list includes a created timestamp so we know how far back to go, and the downloads api returns an array of { day: string, downloads: number} objects, plus an end field representing the late end of the range received. Once end is on or after the current day we can stop fetching and return the total download count.
1// convex/stats.ts
2// ...
3const fetchNpmPackageDownloadCount = async (name: string, created: number) => {
4 // The dates accepted in the endpoint url and returned in the data
5 // are date-only ISO's, eg., `2024-01-01`, so we use that format
6 // for all dates in this function
7 const currentDateIso = new Date().toISOString().substring(0, 10);
8 let nextDate = new Date(created);
9 let totalDownloadCount = 0;
10 let hasMore = true;
11 while (hasMore) {
12 const from = nextDate.toISOString().substring(0, 10);
13 nextDate.setDate(nextDate.getDate() + 17 * 30);
14 if (nextDate.toISOString().substring(0, 10) > currentDateIso) {
15 nextDate = new Date();
16 }
17 const to = nextDate.toISOString().substring(0, 10);
18 const response = await fetch(
19 `https://api.npmjs.org/downloads/range/${from}:${to}/${name}`
20 );
21 const pageData: {
22 end: string;
23 downloads: { day: string; downloads: number }[];
24 } = await response.json();
25 const downloadCount = pageData.downloads.reduce(
26 (acc: number, cur: { downloads: number }) => acc + cur.downloads,
27 0
28 );
29 totalDownloadCount += downloadCount;
30 nextDate.setDate(nextDate.getDate() + 1);
31 hasMore = pageData.end < currentDateIso;
32 }
33 return totalDownloadCount;
34};
35// ...
36The last change we need before adding a new entry point action for npm stats is an update to the schema with npm table definitions.
1// convex/schema.ts
2// ...
3export default defineSchema({
4 // ...
5 npmPackages: defineTable({
6 org: v.string(),
7 name: v.string(),
8 downloadCount: v.number(),
9 })
10 .index("org", ["org"])
11 .index("name", ["name"]),
12});
13
14Now we can create an npm entry point action similar to our GitHub entry point to orchestrate things and handle recursive scheduling.
1// convex/stats.ts
2// ...
3export const updateNpmOrgStats = internalAction({
4 args: {
5 org: v.string(),
6 page: v.optional(v.number()),
7 },
8 handler: async (ctx, args) => {
9 const page = args.page ?? 0;
10 const { packages, hasMore } = await fetchNpmPackageListForOrg(
11 args.org,
12 page
13 );
14 const packagesWithDownloadCount = await asyncMap(packages, async (pkg) => {
15 const totalDownloadCount = await fetchNpmPackageDownloadCount(
16 pkg.name,
17 pkg.created
18 );
19 return {
20 name: pkg.name,
21 downloadCount: totalDownloadCount,
22 };
23 });
24
25 await ctx.runMutation(internal.stats.updateNpmPackages, {
26 org: args.org,
27 packages: packagesWithDownloadCount,
28 });
29
30 if (hasMore) {
31 await ctx.scheduler.runAfter(0, internal.stats.updateNpmOrgStats, {
32 org: args.org,
33 page: page + 1,
34 });
35 }
36 },
37});
38
39We can now call updateNpmOrgStats from the dashboard or cli, just like we’ve been calling our GitHub entry point, and get a list of packages with total download counts in the npmPackages table!
Totaling npm org downloads
The last piece of the npm data puzzle is storing total download counts for an org. This part is really straightforward and matches our GitHub approach.
Let’s do one more schema update to add our npmOrgs table.
1// convex/schema.ts
2// ...
3export default defineSchema({
4 // ...
5 npmOrgs: defineTable({
6 name: v.string(),
7 downloadCount: v.number(),
8 })
9 .index("name", ["name"]),
10});
11We’ll need a mutation for fetching and totaling packages for an owner:
1// convex/stats.ts
2// ...
3export const updateNpmOrg = internalMutation({
4 args: { name: v.string() },
5 handler: async (ctx, args) => {
6 const orgId =
7 (
8 await ctx.db
9 .query("npmOrgs")
10 .withIndex("name", (q) => q.eq("name", args.name))
11 .unique()
12 )?._id ??
13 (await ctx.db.insert("npmOrgs", {
14 name: args.name,
15 downloadCount: 0,
16 }));
17 const packages = await ctx.db
18 .query("npmPackages")
19 .withIndex("org", (q) => q.eq("org", args.name))
20 .collect();
21 const downloadCount = packages.reduce(
22 (acc, pkg) => acc + pkg.downloadCount,
23 0
24 );
25 await ctx.db.patch("npmOrgs", orgId, { downloadCount });
26 },
27});
28// ...
29Finally, we’ll run it conditionally in our npm entry point action when there are no more packages to page through.
1// convex/stats.ts
2// ...
3export const updateNpmOrgStats = internalAction({
4 // ...
5 handler: async (ctx, args) => {
6 // ...
7 if (hasMore) {
8 await ctx.scheduler.runAfter(0, internal.stats.updateNpmOrgStats, {
9 org: args.org,
10 page: page + 1,
11 });
12 // Be sure to add this early return!
13 return;
14 }
15
16 await ctx.runMutation(internal.stats.updateNpmOrg, {
17 name: args.org,
18 });
19 },
20})
21Alright! We now have all the data we need, let’s do something with it.
07 - Frontend: using Convex data in React
We’ve done everything to gather up our GitHub and npm data, let’s look at how to use it in a web app.
We need to do two things:
- Create a query function in our
convex/stats.tsfile that gets data from the database and returns it - Use Convex’s
useQuery()hook on the frontend to call the query
Writing reactive queries for client use
The query isn’t introducing anything new - it’s just like our mutations above, able to use ctx.db to access the database, except it’s only for reading data. For our immediate use case, the query needs to pull owner stats for a single github org and a single npm org. We’ll write the query to exactly serve our product requirements.
1// convex/stats.ts
2// ...
3export const getStats = query({
4 args: { githubOwner: v.string(), npmOrg: v.string() },
5 handler: async (ctx, args) => {
6 const [githubOwner, npmOrg] = await Promise.all([
7 ctx.db
8 .query("githubOwners")
9 .withIndex("name", (q) => q.eq("name", args.githubOwner))
10 .unique(),
11 ctx.db
12 .query("npmOrgs")
13 .withIndex("name", (q) => q.eq("name", args.npmOrg))
14 .unique(),
15 ]);
16 return {
17 downloadCount: npmOrg?.downloadCount,
18 starCount: githubOwner?.starCount,
19 contributorCount: githubOwner?.contributorCount,
20 dependentCount: githubOwner?.dependentCount,
21 };
22 },
23});
24// ...
25We’re running two ctx.db.query() calls in parallel to make this even faster, and the simplicity of the query means it will almost always result in a cached response for the client.
Displaying synced data in React with Convex
Let’s look at how to pull this data into our React app:
1// src/App.tsx
2import { useQuery } from "convex/react";
3import { api } from "../convex/_generated/api";
4import { PropsWithChildren } from "react";
5
6const App = () => {
7 const stats = useQuery(api.stats.getStats, {
8 githubOwner: "tanstack",
9 npmOrg: "tanstack",
10 });
11 return (
12 <div>
13 <div>downloads: {stats?.downloadCount}</div>
14 <div>stars: {stats?.starCount}</div>
15 <div>contributors: {stats?.contributorCount}</div>
16 <div>dependents: {stats?.dependentCount}</div>
17 </div>
18 );
19};
20Run it 🔥
You can now run this locally at http://localhost:5173 and you should see a little pile of numbers at the top right of your screen. Data!
Obviously this leaves out boilerplate stuff like your React entry point, but otherwise, this really is all you need to put Convex data in your app. When data changes in your database, it changes in all affected clients. Sync ✨
This looks pretty dry though, let’s make it decent.
1import { useQuery } from "convex/react";
2import { api } from "../convex/_generated/api";
3import { PropsWithChildren } from "react";
4
5const App = () => {
6 const stats = useQuery(api.stats.getStats, {
7 githubOwner: "tanstack",
8 npmOrg: "tanstack",
9 });
10 return (
11 <Card>
12 <Stat label="Downloads" value={stats?.downloadCount} />
13 <Stat label="Stars" value={stats?.starCount} />
14 <Stat label="Contributors" value={stats?.contributorCount} />
15 <Stat label="Dependents" value={stats?.dependentCount} />
16 </Card>
17 );
18};
19
20const Card = ({ children }: PropsWithChildren) => (
21 <div
22 style={{
23 width: "100vw",
24 height: "100vh",
25 display: "flex",
26 justifyContent: "center",
27 alignItems: "center",
28 background: "linear-gradient(to right, #f8f9fa, #e9ecef)",
29 }}
30 >
31 <div
32 style={{
33 display: "flex",
34 flexDirection: "row",
35 gap: "40px",
36 padding: "40px",
37 background: "white",
38 borderRadius: "12px",
39 boxShadow: "0 4px 6px rgba(0, 0, 0, 0.1)",
40 }}
41 >
42 {children}
43 </div>
44 </div>
45);
46
47const Stat = ({ label, value }: { label: string; value?: number }) => (
48 <div style={{ padding: "20px" }}>
49 <div
50 style={{
51 fontSize: "18px",
52 fontFamily: "sans-serif",
53 color: "#6c757d",
54 marginBottom: "8px",
55 }}
56 >
57 {label}
58 </div>
59 <div
60 style={{
61 fontSize: "36px",
62 fontWeight: "bold",
63 color: "#212529",
64 fontFamily: "sans-serif",
65 }}
66 >
67 {value?.toLocaleString()}
68 </div>
69 </div>
70);
71
72export default App;
73
74I’m not ashamed of inline css folks 💪
At this point you should see a nice little card with your data, and if you’re using the TanStack npm and GitHub orgs like we are in the example code here, you should see something like this:
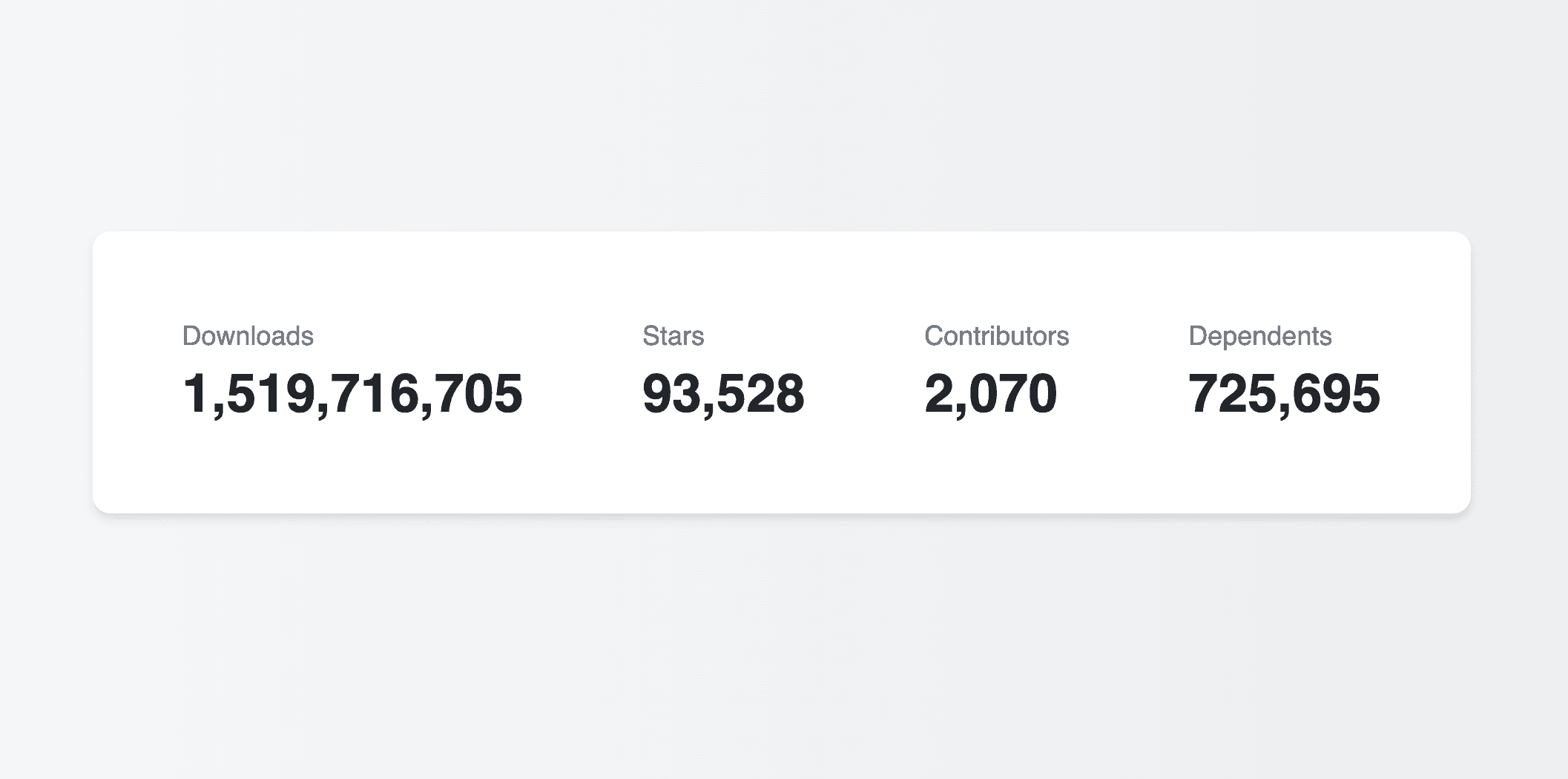
We’ve got sync! But the numbers will never change, so we’re not getting a lot of value from the whole reactive data thing. Let’s change that.
08 - Keep it fresh: crons and receiving webhooks with Convex
We already know the data we’re tracking isn’t exactly available live. There’s a way to make it happen with GitHub stars, but npm downloads only update every 24 hours and, dependent and contributor data is delayed on GitHub’s end. What can we do here?
Dependent and contributor numbers just don’t change quickly, even for large orgs. And as we know, npm download data updates daily. But GitHub stars do generate events from GitHub whenever there’s a change.
A best effort for showing real data as quickly as it changes might look like:
- Running our
getGitHubOwnerStats()andgetNpmOrgStats()actions regularly - Capturing GitHub star events and updating the database immediately
Let’s look at how to do that with Convex.
Continuous updates with cronjobs
Convex has the simplest cronjobs implementation I’ve ever encountered:
1// convex/crons.ts
2import { cronJobs } from "convex/server";
3import { internal } from "./_generated/api";
4
5const crons = cronJobs();
6
7crons.hourly(
8 "update stats",
9 { minuteUTC: 0 }, // At the top of every hour
10 internal.stats.updateGithubOwnerStats,
11 { owner: "tanstack" },
12);
13
14crons.hourly(
15 "update npm stats",
16 { minuteUTC: 0 }, // At the top of every hour
17 internal.stats.updateNpmOrgStats,
18 { org: "tanstack" },
19);
20
21export default crons;
22convex/crons.ts is a special file for defining your cronjobs. The cronJobs factory we’re importing supports some nice shortcuts like crons.hourly, but also supports regular cron schedule syntax if that’s your thing.
Here we’ve scheduled both of our entry point actions to run every hour so our data stays fresh - next time the hour rolls over, you should see these functions running.
Realtime updates with webhooks
I really want live in a world where I can see the number of stars on my GitHub repos change instantly when someone stars a repo. That’s all I’ve ever wanted. And I dare say, that’s all anyone has ever wanted. Let’s live the dream, people.
We have two steps to get webhooks going:
- Configure a webhook on GitHub
- Write a Convex HTTP Action to receive the webhook in your Convex project
Setting up the webhook
GitHub sends a webhook every time almost anything happens. But while we’re able to get general data on any public repo, we can’t set up webhooks for repos we don’t have privileged access to. We can set up webhooks to be sent by GitHub to any url we give it for specific repos, or for an org. You can’t do it for all repos on a user’s account, unfortunately.
Here’s how to get those hooks flowing:
- Follow GitHub’s docs for repository webhooks or organization webhooks
- Get your payload URL
npx convex dashboard> Settings > URL & Deploy Key > HTTP Actions URL- Add
/events/githubto this url to get your payload url - Eg.,
https://verb-animal-123.convex.site/events/github
- Content type:
application/json - Generate a secret, add it in the webhook creation form and in Convex production env vars as
GITHUB_WEBHOOK_SECRET - Which events? > Select individual > Stars only
Now every time someone stars or un-stars the repo you set up that webhook for, or any repo on the org if you set it up for an org, a POST request will be sent to your Convex project at the path /events/github ! Currently this will result in a 404, so let’s make that endpoint to receive the webhooks.
Receiving a webhook with Convex
Convex HTTP Actions are Convex Actions that you register to handle specific url paths on your HTTP Actions URL (this is identical to your deployment’s main Convex URL, except it ends in .site instead of .cloud). You can write as many as you want, and they can do anything Convex Actions can do.
Let’s look at the behavior we need.
- User stars a repo
- GitHub sends a POST request to
/events/githubon our HTTP Actions URL - Using data from the request, we update the number of stars for both the repo and the owner in our db
- Clients update immediately
Let’s start by creating our endpoint to receive the webhook. HTTP Actions are defined in a special file: convex/http.ts.
1// convex/http.ts
2import { httpActionGeneric, httpRouter } from "convex/server";
3import { Webhooks } from "@octokit/webhooks";
4import { internal } from "_generated/api";
5import { httpAction } from "_generated/server";
6
7const http = httpRouter();
8
9http.route({
10 path: "/events/github",
11 method: "POST",
12 handler: httpAction(async (ctx, request) => {
13 const webhooks = new Webhooks({
14 secret: process.env.GITHUB_WEBHOOK_SECRET!,
15 });
16
17 const signature = request.headers.get("x-hub-signature-256")!;
18 const bodyString = await request.text();
19
20 if (!(await webhooks.verify(bodyString, signature))) {
21 return new Response("Unauthorized", { status: 401 });
22 }
23 const body = JSON.parse(bodyString);
24 const {
25 repository,
26 }: {
27 repository: {
28 name: string;
29 owner: { login: string };
30 stargazers_count: number;
31 };
32 } = body;
33
34 // TODO: update database
35
36 return new Response(null, { status: 200 });
37 }),
38});
39
40export default http;
41The configuration is pretty straightforward, we specify the path we want the endpoint to receive requests at, the method, and a handler. We use Octokit’s Webhooks helper to verify the webhook for security, and then parse the request body into a typed object based on Github’s docs for this event.
Finally, we end our action with a 200 response. But we have an important TODO before that! Remember, actions can’t touch the database directly, so we’ll need to write a mutation that our action can call to update the data. Let’s add one to convex/stats.ts.
1// convex/stats.ts
2// ...
3export const updateGithubRepoStars = internalMutation({
4 args: {
5 owner: v.string(),
6 name: v.string(),
7 starCount: v.number(),
8 },
9 handler: async (ctx, args) => {
10 const owner = await ctx.db
11 .query("githubOwners")
12 .withIndex("name", (q) => q.eq("name", args.owner))
13 .unique();
14 if (!owner) {
15 throw new Error(`Owner ${args.owner} not found`);
16 }
17 const repo = await ctx.db
18 .query("githubRepos")
19 .withIndex("owner_name", (q) =>
20 q.eq("owner", args.owner).eq("name", args.name),
21 )
22 .unique();
23 if (!repo) {
24 throw new Error(`Repo ${args.owner}/${args.name} not found`);
25 }
26 await ctx.db.patch("githubRepos", repo._id, { starCount: args.starCount });
27 await ctx.db.patch("githubOwners", owner._id, {
28 starCount: Math.max(0, owner.starCount - repo.starCount + args.starCount),
29 });
30 },
31});
32// ...
33This mutation will updates both the repo star count and the associated owner star count, and throw an error for unknown owners or repos. (New repos will get picked up by the hourly cron.)
Now, let’s include it in our HTTP endpoint:
1// convex/http.ts
2// ...
3http.route({
4 path: "/events/github",
5 method: "POST",
6 handler: httpAction(async (ctx, request) => {
7 // ...
8 await ctx.runMutation(internal.stats.updateGithubRepoStars, {
9 owner: repository.owner.login,
10 name: repository.name,
11 starCount: repository.stargazers_count,
12 });
13
14 return new Response(null, { status: 200 });
15 }),
16});
17// ...
18You should now be able to star/unstar the repo that you set up the webhook for, or any repo in the org you set up the webhook for, and see the stars count
Quick recap
We’re close to the end here, and we have some pretty cool functionality in place.
- GitHub and npm data stored in our own database
- Automatically updating itself every hour
- Live updates of GitHub stars
- Rendering in the browser with sync
We did all of this with
- ~500 lines of Typescript for backend
- A handful of lines for frontend integration
I’m using one service for everything, it’s all running right next to my database, on infrastructure I never have to think about. Didn’t have to open any accounts at different services or go into a dashboard and enable or provision a service or feature, everything is completely defined in code. Plus, everything is type safe, front to back! The future, my friends 🚀.
09 - Bonus round: npm downloads go brrrr
In js world, npm download numbers are generally your largest stat. Just look at the numbers for TanStack - it goes up by millions every day.
And there it sits, only updating every hour.

Computing (faking) live-ish npm download numbers
We have daily counts of npm package downloads, right? What if we used past averages to make a conservative estimate of downloads for the next 24 hours? We could show a live counter based on the estimate. Maybe it could be all animated and cool looking?! Let’s take our over-engineering to the next level
A basic approach might look like this:
- Start with our npm download count from the database
- Increase this number in the client based on the time that’s passed since the number was last updated and some forecasted rate of increase
- Keep increasing the number at some interval
- Eventually a new real number will hit the database and the increasing restarts
To do this, we need some things.
- The last download count ✅
- A timestamp for when that download count was updated ❌
- A reasonable expected rate of increase based on recent data ❌
- A hook to continually change the value in the client ❌
We could totally drive this from Convex instead of in the client, but we’ll be updating it very frequently (like once every second), so a lot of function calls for a use case that’s well served with local state.
Let’s get our missing pieces.
Download count update timestamp
We need to capture the timestamp when the download count changes for an org (and may as well for each package, too). This isn’t the same as a general updatedAt field - we only want this field to update when the downloadCount is refreshed (even if the number itself doesn’t change).
Let’s add a new downloadCountUpdatedAt field to our npm tables in the schema. We’ll use simple numeric timestamps for this.
1// convex/schema.ts
2export default defineSchema({
3 // ...
4 npmOrgs: defineTable({
5 // ...
6 downloadCountUpdatedAt: v.number(),
7 }).index("name", ["name"]),
8 npmPackages: defineTable({
9 // ...
10 downloadCountUpdatedAt: v.number(),
11 })
12 .index("org", ["org"])
13 .index("name", ["name"]),
14// ...
15Then we’ll update the new field in our npmPackages mutation:
1// convex/stats.ts
2// ...
3export const updateNpmPackagesForOrg = internalMutation({
4 // ...args
5 handler: async (ctx, args) => {
6 await asyncMap(args.packages, async (pkg) => {
7 // ...
8 // Only update if downloadCount has changed, this keeps
9 // downloadCountUpdatedAt from changing every hour
10 if (existingPackage?.downloadCount === pkg.downloadCount) {
11 return;
12 }
13 if (existingPackage) {
14 await ctx.db.patch("npmPackages", existingPackage._id, {
15 // ...
16 // add field
17 downloadCountUpdatedAt: Date.now(),
18 });
19 return;
20 }
21 await ctx.db.insert("npmPackages", {
22 // ...
23 // add field
24 downloadCountUpdatedAt: Date.now(),
25 });
26 });
27 },
28});
29updateNpmOrg needs a slight refactor - we used to only need the org id, but now we need the whole org so we can check the downloadCountUpdatedAt field and bail if it hasn’t changed.
1// convex/stats.ts
2export const updateNpmOrg = internalMutation({
3 args: { name: v.string() },
4 handler: async (ctx, args) => {
5 const existingOrg = await ctx.db
6 .query("npmOrgs")
7 .withIndex("name", (q) => q.eq("name", args.name))
8 .unique();
9 const newOrgId =
10 existingOrg?._id ??
11 (await ctx.db.insert("npmOrgs", {
12 name: args.name,
13 downloadCount: 0,
14 downloadCountUpdatedAt: Date.now(),
15 dayOfWeekAverages: [],
16 }));
17 const org = existingOrg || (await ctx.db.get("npmOrgs", newOrgId));
18 if (!org) {
19 throw new Error(`npm org ${args.name} not found`);
20 }
21 const packages = await ctx.db
22 .query("npmPackages")
23 .withIndex("org", (q) => q.eq("org", args.name))
24 .collect();
25 const downloadCount = packages.reduce(
26 (acc, pkg) => acc + pkg.downloadCount,
27 0,
28 );
29 if (downloadCount === org.downloadCount) {
30 return;
31 }
32 await ctx.db.patch("npmOrgs", org._id, {
33 downloadCount,
34 downloadCountUpdatedAt: Date.now(),
35 });
36 },
37}
38Note: Date.now() is a frozen value in the Convex runtime, it doesn’t change at any point during function execution. It’s also in UTC as you’d probably expect. If you already have data in the npm tables, these changes will cause errors in npx convex dev, as we’ve added a new required field and it’s unset in your existing records, so Convex blocks the deployment to ensure data remains valid to your schema. We would normally use migrations to address this, but since the data is all generated, we can clear the database and rerun our functions to populate data with the new field.
The tutorial repo includes an npm script for clearing the database, you can run it via npm run clear-db. If you’re not using the repo, you can run this from your project root to clear all tables:
1npx convex import --replace-all --table githubOwners --format jsonLines /dev/null -y",
2Calculating rate of increase
Rate of increase should be simple. We have daily counts going back years, we could just take the last x number of days and use the average. If most days are following a similar curve, that is. Turns out, they aren’t.
Here’s a week of data for the @tanstack/query-core package, one of the most downloaded on the org, from Monday to Sunday:
1{
2 downloads: 201464,
3 day: '2024-11-17'
4},
5{
6 downloads: 756724,
7 day: '2024-11-11'
8},
9{
10 downloads: 912807,
11 day: '2024-11-12'
12},
13{
14 downloads: 932266,
15 day: '2024-11-13'
16},
17{
18 downloads: 827693,
19 day: '2024-11-14'
20},
21{
22 downloads: 804527,
23 day: '2024-11-15'
24},
25{
26 downloads: 218162,
27 day: '2024-11-16'
28}
29Look at the first and last days compared to the rest. This trend is repeated week after week - apparently folks are downloading packages from npm way less on the weekends. Like, it’s not even close. Apparently we engineers do in fact have lives! No that’s probably stretching it. Anyway, if we want a good estimate, it should take this day of week variance into account.
In other words, we want a different average depending on which day it is, because there are clear daily patterns for specific days of the week. This wouldn’t be worth it if it took a lot more effort, but it doesn’t.
So! When we’re updating npm data, let’s try:
- Getting the last 4 download counts for each day of the week
- Getting an average for each
- Keep these numbers in an array field on the package and org tables
With these numbers, we’ll be able to use the average for the upcoming day to calculate a rate of increase.
Let’s add a new dayOfWeekAverages field to our npm tables and gather the averages array when we fetch package data from the npm api:
1// convex/schema.ts
2// ...
3export default defineSchema({
4 npmOrgs: defineTable({
5 // ...
6 // add field
7 dayOfWeekAverages: v.array(v.number()),
8 }).index("name", ["name"]),
9 npmPackages: defineTable({
10 // ...
11 // add field
12 dayOfWeekAverages: v.array(v.number()),
13 })
14 // ...
15});
161// convex/stats.ts
2// ...
3const fetchNpmPackageDownloadCount = async (name: string, created: number) => {
4 const currentDateIso = new Date().toISOString().substring(0, 10);
5 let nextDate = new Date(created);
6 // ...
7 nextDate.setDate(nextDate.getDate() - 30);
8 const from = nextDate.toISOString().substring(0, 10);
9 nextDate.setDate(nextDate.getDate() + 30);
10 const to = nextDate.toISOString().substring(0, 10);
11
12 // Fetch the last 30 days so we can get 4 of each week day. The last
13 // one or two days tend to have a zero count, getting 30 ensures we
14 // have 28 days with counts.
15 const lastPageResponse = await fetch(
16 `https://api.npmjs.org/downloads/range/${from}:${to}/${name}`,
17 );
18 const lastPageData: {
19 end: string;
20 downloads: { day: string; downloads: number }[];
21 } = await lastPageResponse.json();
22 // Create array of week of day averages, 0 = Sunday
23 const dayOfWeekAverages = Array(7)
24 .fill(0)
25 .map((_, idx) => {
26 const total = lastPageData.downloads
27 .filter((day) => new Date(day.day).getDay() === idx)
28 .slice(0, 4)
29 .reduce((acc, cur) => acc + cur.downloads, 0);
30 return Math.round(total / 4);
31 });
32 return {
33 totalDownloadCount,
34 dayOfWeekAverages,
35 };
36};
37// ...
38Finally, we’ll update the other functions to handle the new field.
1// convex/stats.ts
2// ...
3export const updateNpmPackagesForOrg = internalMutation({
4 args: {
5 org: v.string(),
6 packages: v.array(
7 v.object({
8 // ...
9 // add field
10 dayOfWeekAverages: v.array(v.number()),
11 }),
12 ),
13 },
14 handler: async (ctx, args) => {
15 await asyncMap(args.packages, async (pkg) => {
16 // ...
17 if (existingPackage) {
18 await ctx.db.patch("npmPackages", existingPackage._id, {
19 // ...
20 // add field
21 dayOfWeekAverages:
22 pkg.dayOfWeekAverages || existingPackage.dayOfWeekAverages,
23 });
24 return;
25 }
26 await ctx.db.insert("npmPackages", {
27 // ...
28 // add field
29 dayOfWeekAverages: pkg.dayOfWeekAverages,
30 });
31 });
32 },
33});
34
35// ...
36
37export const updateNpmOrg = internalMutation({
38 args: { name: v.string() },
39 handler: async (ctx, args) => {
40 // ...
41 const newOrgId = await ctx.db.insert("npmOrgs", {
42 // ...
43 // add field
44 dayOfWeekAverages: [],
45 });
46 // ...
47 await ctx.db.patch("npmOrgs", org._id, {
48 // ...
49 // total up and add field
50 dayOfWeekAverages: packages.reduce(
51 (acc, pkg) => acc.map((val, idx) => val + pkg.dayOfWeekAverages[idx]),
52 Array(7).fill(0),
53 ),
54 });
55 },
56});
57
58// ...
59If you run npm run clear-db and then run our updateNpmOrgStats function with “tanstack” as the org, you’ll see the @tanstack/query-core package we referenced earlier now has an array of dayOfWeekAverages. The top is the array as I see it as of this writing, the bottom is the download numbers from above, both start with Sunday. They look pretty similar!
1[
2 203405, 942359, 990738, 964757, 904130, 786032, 202608,
3]
4
5{
6 downloads: 201464,
7 day: '2024-11-17'
8},
9{
10 downloads: 756724,
11 day: '2024-11-11'
12},
13{
14 downloads: 912807,
15 day: '2024-11-12'
16},
17{
18 downloads: 932266,
19 day: '2024-11-13'
20},
21{
22 downloads: 827693,
23 day: '2024-11-14'
24},
25{
26 downloads: 804527,
27 day: '2024-11-15'
28},
29{
30 downloads: 218162,
31 day: '2024-11-16'
32}
33Hook it up
Now that we have our count and our averages for reference, let’s write a hook that outputs a projected number based on past averages.
Here’s a generic hook I came up with that takes in a value, a next value, a time range, and an interval to update at, and puts out a number that updates on the interval:
1// src/counters.ts
2import { useCallback, useState, useEffect } from "react";
3
4const useFakeCounter = ({
5 value,
6 nextValue,
7 rangeStart,
8 rangeEnd,
9 intervalMs = 1000,
10}: {
11 value?: number;
12 nextValue?: number;
13 rangeStart?: number;
14 rangeEnd?: number;
15 intervalMs?: number;
16}) => {
17 const [isInitialized, setIsInitialized] = useState(false);
18 const [currentValue, setCurrentValue] = useState(value);
19
20 const updateCurrentValue = useCallback(() => {
21 if (
22 typeof value !== "number" ||
23 typeof nextValue !== "number" ||
24 typeof rangeStart !== "number" ||
25 typeof rangeEnd !== "number"
26 ) {
27 setCurrentValue(value);
28 return;
29 }
30 const diff = nextValue - value;
31 const duration = rangeEnd - rangeStart;
32 const rate = diff / duration;
33 setCurrentValue(Math.round(value + rate * (Date.now() - rangeStart)));
34 }, [value, nextValue, rangeStart, rangeEnd]);
35
36 useEffect(() => {
37 const interval = setInterval(updateCurrentValue, intervalMs);
38 return () => {
39 clearInterval(interval);
40 };
41 }, [updateCurrentValue, intervalMs]);
42 return currentValue;
43};
44Let’s wrap this with another hook that passes in our npm data and a 1 second interval.
1// src/counters.ts
2// ...
3export const useNpmDownloadCounter = (
4 npmPackageOrOrg?: {
5 downloadCount: number;
6 dayOfWeekAverages: number[];
7 downloadCountUpdatedAt: number;
8 } | null,
9) => {
10 const { downloadCount, dayOfWeekAverages, downloadCountUpdatedAt } =
11 npmPackageOrOrg ?? {};
12 const nextDayOfWeekAverage =
13 dayOfWeekAverages?.[(new Date().getDay() + 8) % 7] ?? 0;
14 return useFakeCounter({
15 value: downloadCount,
16 nextValue: (downloadCount ?? 0) + nextDayOfWeekAverage,
17 rangeStart: downloadCountUpdatedAt,
18 rangeEnd: (downloadCountUpdatedAt ?? 0) + 1000 * 60 * 60 * 24,
19 intervalMs: 50,
20 });
21};
22We’ve set rangeEnd to 24 hours ahead of downloadCountUpdatedAt, which will be within an hour of when the number was last updated (except the first day you run it, who knows how old that number is 😅). We’ve set intervalMs low at 50ms, for a proper brrrr. If you’re using TanStack or another npm org with decent volume, you should see the downloads number climbing!

Make it shine
Alright, one. last. thing. Proper brrr requires proper animation. I would probably have bypassed this established rule of brrr in favor of just shipping were it nor for an incredible little library called NumberFlow, aka brrr.js (I just call it that). NumberFlow gives us a component that animates changing numeric values both effortlessly and stunningly 💫
It was quickly apparent that animating non-monospace numbers quickly can cause some jarring layout shift, so we’ll wrap it in this component that uses a 0 opacity number with the same number of digits all set to the number 8 to maintain a stable width while our animated numbers are positioned absolutely over it. Also more inline css, shield your eyes.
1// src/StableCounter.tsx
2import NumberFlow from "@number-flow/react";
3
4export const StableCounter = ({ value }: { value?: number }) => {
5 if (typeof value !== "number") {
6 return null;
7 }
8 const dummyString = Number(
9 Array(value?.toString().length ?? 1)
10 .fill("8")
11 .join(""),
12 ).toLocaleString();
13
14 return (
15 <div style={{ position: "relative" }}>
16 {/* Dummy span to prevent layout shift */}
17 <span style={{ opacity: 0 }}>{dummyString}</span>
18 <span style={{ position: "absolute", top: "-0.5px", left: 0 }}>
19 <NumberFlow
20 transformTiming={{
21 duration: 1000,
22 easing: "linear",
23 }}
24 value={value}
25 trend={1}
26 continuous
27 isolate
28 willChange
29 />
30 </span>
31 </div>
32 );
33};
34Let’s add it to our App component. We’ll adjust our <Stat> component to optionally accept children so our counter inherits the same styles as the other stats.
1// src/App.tsx
2// ...import
3import { StableCounter } from "./StableCounter";
4
5const App = () => {
6 const stats = useQuery(api.stats.getStats, {
7 githubOwner: "tanstack",
8 npmOrg: "tanstack",
9 });
10 const liveNpmDownloadCount = useNpmDownloadCounter(stats?.npmOrg);
11 return (
12 <Card>
13 <Stat label="Downloads">
14 <StableCounter value={liveNpmDownloadCount} />
15 </Stat>
16 // ...
17 </Card>
18 );
19};
20
21// ...
22
23const Stat = ({
24 label,
25 value,
26 children,
27}: PropsWithChildren<{ label: string; value?: number }>) => (
28 <div style={{ padding: "20px" }}>
29 // ...
30 <div
31 style={{
32 // ...
33 }}
34 >
35 {children ?? value?.toLocaleString()}
36 </div>
37 </div>
38);
39
40export default App;
41
42It’s beautiful! But it takes like two seconds longer than the other numbers to load and start animating! This wasn’t a problem in the original component made for the TanStack site, because the TanStack site uses TanStack Start, so all of our Convex data is ready when the page component loads. So our fake counter hook is overly reliant on immediately available state. Without that, we need to add a good ol’ useEffect to kickstart our counter state. We also need to raise that 50ms interval to something much more reasonable with animations running:
1// src/counter.ts
2const useFakeCounter = ({
3 // ...
4}) => {
5 const [isInitialized, setIsInitialized] = useState(false);
6 const [currentValue, setCurrentValue] = useState(value);
7
8 // ...
9
10 // Avoid initial delay
11 useEffect(() => {
12 if (isInitialized) {
13 return;
14 }
15 if (typeof value === "number" && typeof currentValue !== "number") {
16 setCurrentValue(value);
17 return;
18 }
19 if (typeof value === "number" && typeof nextValue === "number") {
20 setCurrentValue(nextValue);
21 setIsInitialized(true);
22 }
23 }, [isInitialized, value, nextValue, currentValue]);
24
25 // ...
26};
27
28export const useNpmDownloadCounter = (
29 // ...
30) => {
31 // ...
32 return useFakeCounter({
33 // ...
34 intervalMs: 1000,
35 });
36};
37// ...
38Voilà ✨
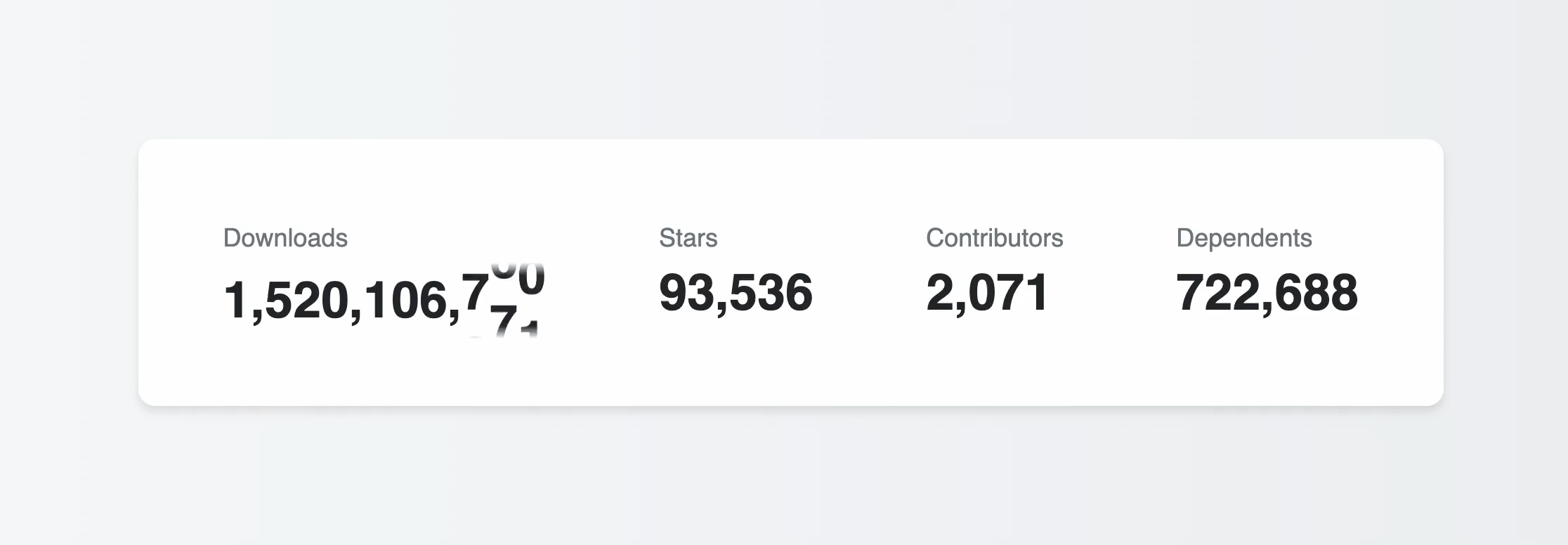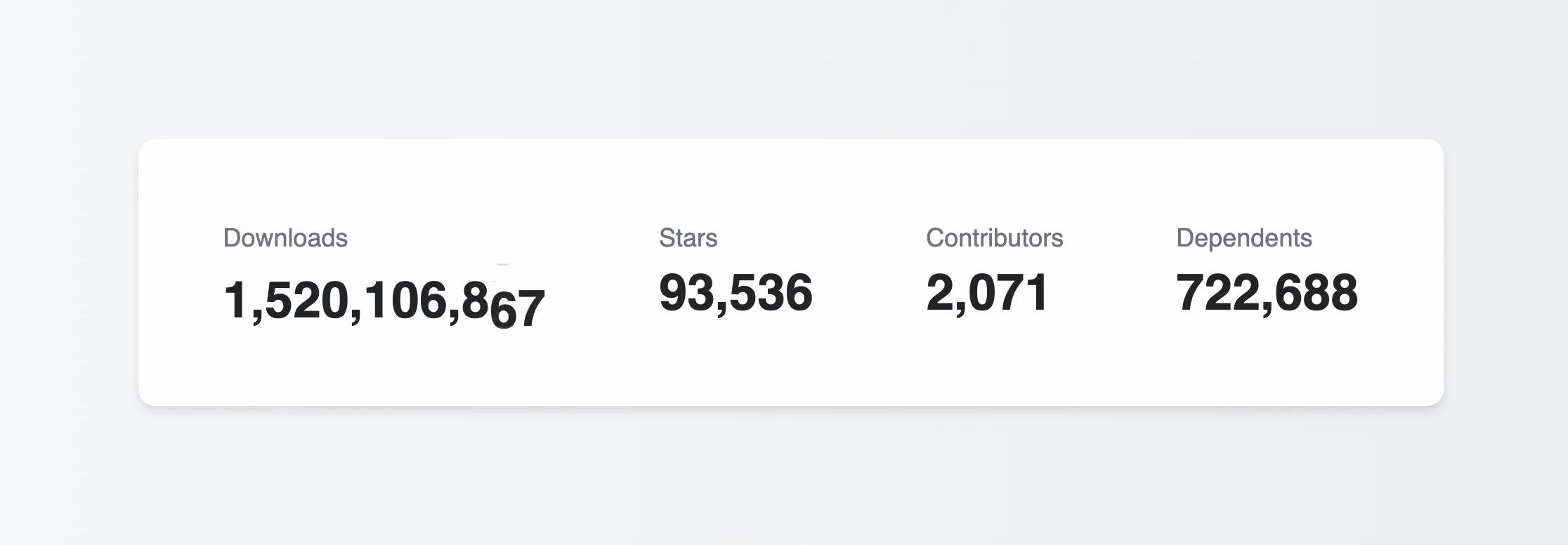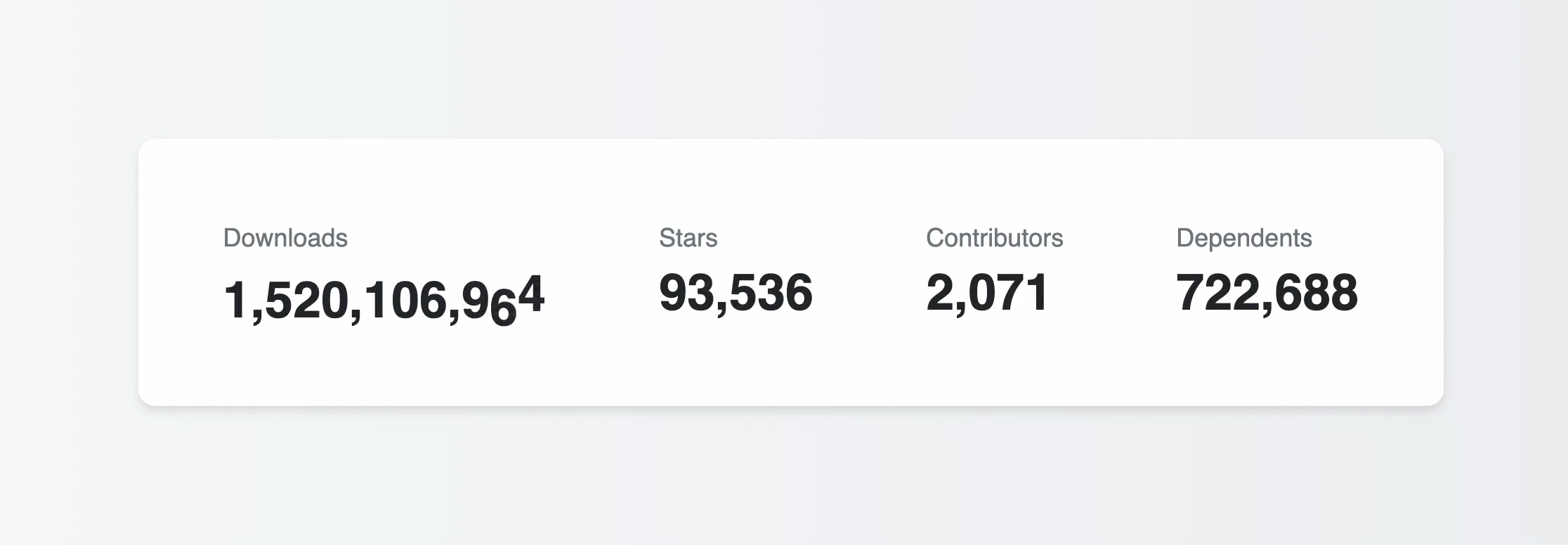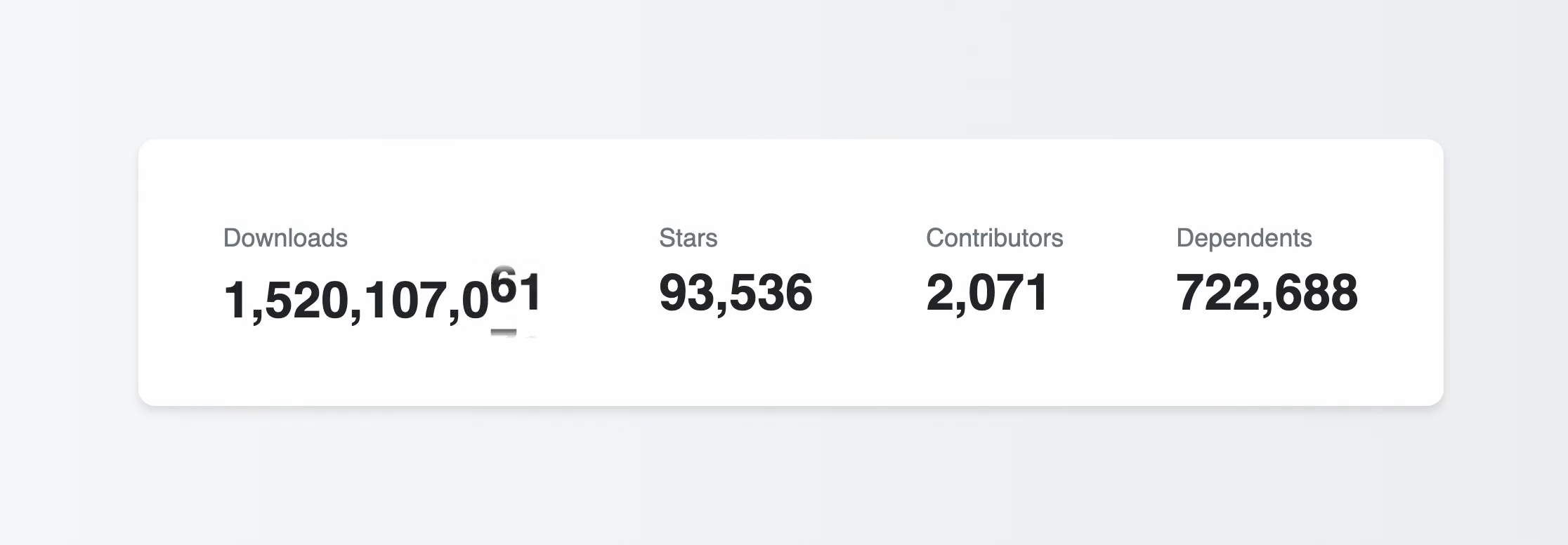
A Convex Component for syncing and rendering open source project data.

Convex is the reactive backend platform that keeps up with you and your agents. Database, functions, workflow, sync, search, file storage, and more. All TypeScript, zero glue.