
Using Pinecone and Embeddings
Looking to implement semantic search or add on-demand context to a GPT prompt so it doesn’t just make shit up (as much)?
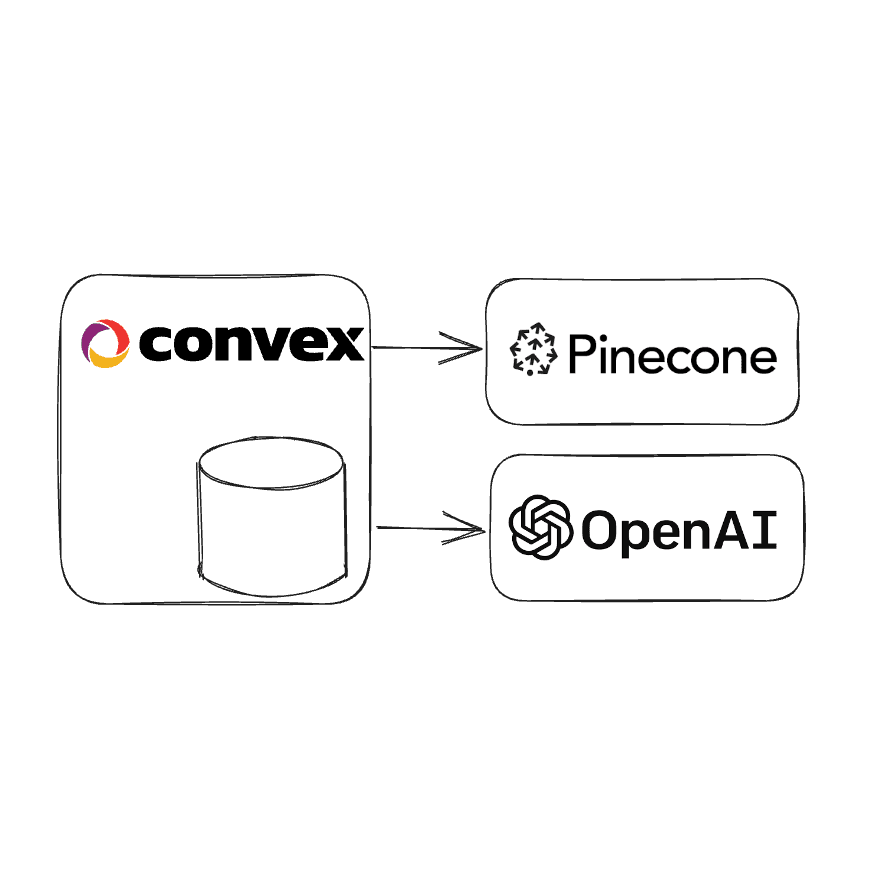
Convex is a great fit for apps that leverages embeddings and also has user data. Convex has a built-in vector store that can store millions of vectors with a variety of filters. However, going with a specialized provider like Pinecone can be beneficial for apps with specific needs, like storing hundreds of millions of vectors.
When used together, Pinecone stores and queries over vectors efficiently, and Convex stores relational & document data with strong transaction guarantees and end-to-end real-time reactivity.
Let’s walk through how this shakes out in practice. If you want to see some code you can play around with, check out this GitHub repo where you can add your own data and compare it and search over it using Convex and Pinecone.
High-level user flow
To start, what’s an example? With Pinecone and Convex, you can have a flow like this:
- A user submits a question and starts subscribing to the question’s results. Under the hood, Convex has stored the question in a document and kicked off an asynchronous action. If this question has been asked before, it might re-use previous results.
- The action creates an embedding using a service like OpenAI or Cohere. It can persist this embedding for posterity or to be able to search for similar questions.
- The action uses the embedding to query Pinecone (or any vector store) for related documents, products, or whatever your embeddings represent.
- The action stores the results in the question document, which automatically reflows to update the user’s client with the new data - potentially returning materialized data pulled from other documents in the database associated with the results.
- If this is part of a broader chain of operations, it might use the related documents to compose a prompt to an LLM like ChatGPT, using both the related documents and the question to get a more contextual answer.
A word on streaming updates
At every step, updates written to the Convex database will update all subscribed clients. Unlike raw HTTP streaming, Convex subscriptions can be trivially consumed by multiple clients in parallel and are resilient to network issues or page refreshes. The data received will be from a consistent snapshot of the database state, making it easier to reason about correctness.
Convex is the reactive backend platform that keeps up with you and your agents. Database, functions, workflow, sync, search, file storage, and more. All TypeScript, zero glue.
Many of the code snippets below can be found in this GitHub repo which you’re welcome to play around with using your own data and API keys. If you are desperate for a hosted playground, let me know in Discord!
Adding data to Convex and Pinecone
Depending on the application, you may have a large mostly-static corpus of data, or be continually adding data — which I’ll refer to as a source below. The process looks something like the following:
Break up your source into bite-sized chunks.
This helps limit how much data you pass (embedding models have context limits), as well as make the embedding more targeted. You could imagine an embedding of this whole post might not rank as highly against “How do you add data to Convex and Pinecone?” as an embedding that just covered this section.
To do this, you can split it yourself or use a library like LangChain’s RecursiveCharacterTextSplitter:
1import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
2
3const textSplitter = new RecursiveCharacterTextSplitter({
4 chunkSize: ChunkSize,
5});
6const splitTexts = await textSplitter.createDocuments([pageContent]);
7const chunks = splitTexts.map((chunk) => ({
8 text: chunk.pageContent,
9 lines: chunk.metadata.loc.lines,
10}));
11You can tune the size and algorithm to your own needs. One tip is to add some overlap, so each chunk has some text from the previous and next sections.
Store the source in the database
The Convex database is a great place to store all the metadata that your app will want. For embeddings based on text, you’ll likely even want to store the chunk of text in the database, so you can quickly access it to return as part of queries for a client or as part of a pipeline. For larger data, like video, it makes more sense to store the data in file storage.
Importantly, you should not store the text chunk directly in Pinecone metadata, as it can quickly fill up the index because all metadata is indexed by default in Pinecone.
1async function addSource(
2 db: DatabaseWriter,
3 name: string,
4 chunks: { text: string; lines: { from: number; to: number } }[]
5) {
6 const sourceId = await db.insert("sources", {
7 name,
8 chunkIds: [],
9 saved: false,
10 });
11 const chunkIds = await Promise.all(
12 chunks.map(({ text, lines }, chunkIndex) =>
13 db.insert("chunks", {
14 text,
15 sourceId,
16 chunkIndex,
17 lines,
18 })
19 )
20 );
21 await db.patch("sources", sourceId, { chunkIds });
22 return (await db.get("sources", sourceId))!;
23}
24There are a few things to note here:
- I’m both saving a back-reference from chunks to sources, as well as a forward reference from a source to many chunks. As discussed in this post on database relationships, this is a way to get quick access in both directions without having to define an extra index when you have a small number of relations (8192 technically but <1k is my rule of thumb).
- I’m saving an empty array at first, then patching it with the chunk IDs once I insert them. Convex generates unique IDs on insertion. At this time you can’t pre-allocate or specify custom primary IDs for documents.
- I’m creating the source with
saved: false- we’ll update this once we’ve saved the embeddings into Pinecone. This allows the client to know the insertion status, as well as help with transient failures, which we’ll see later on.
Kick off a background action
The Convex mutation function is transactional but as a result, we can’t perform a non-transactional operation like talking to a third-party service in the middle of a mutation. A Convex action is non-transactional and can talk to the outside world. One trick I like to use is to schedule an action to execute after a mutation commits, ensuring that the communication with the outside world only happens if the mutation has successfully run.
Mutations in Convex are transactions and are prohibited from having non-transactional side effects like calling other cloud services. With actions you can make these sorts of calls, but how do you “call” an action from a mutation if the mutation can’t have side effects? A pattern I really like is to schedule the action from the mutation:
1await ctx.scheduler.runAfter(0, internal.sources.addEmbedding, {
2 source,
3 texts: chunks.map(({ text }) => text),
4});
5Thanks to Convex’s strong transaction guarantees, the action is only invoked if the mutation successfully commits, so you’ll never have an action running for a source that doesn’t exist.
Create an embedding
From our action, we can fetch embeddings. See this post for more information on what embeddings are. See the code for fetchEmbeddingBatch here.
1const { embeddings } = await fetchEmbeddingBatch(texts);
2Upsert into Pinecone
Adding data into Pinecone is a straightforward operation. “Upsert” for those unfamiliar is an update if the specified id already exists, otherwise it inserts.
1await upsertVectors(
2 "chunks", // namespace
3 source.chunkIds.map((id, chunkIndex) => ({
4 id,
5 values: embeddings[chunkIndex],
6 metadata: { sourceId: source._id, textLen: texts[chunkIndex].length },
7 }))
8);
9Tips:
- We aren’t including much metadata here - in general, you should only store metadata that you might want to use to limit Pinecone queries - such as keywords, categories, or in this case text length1.
- We’re re-using the Convex document ID for the pinecone vector. This isn’t required—you could make up your own ID and store that in the Convex document—but I find it very handy. Results of Pinecone queries, without returning metadata, can be used directly with
db.getwhich is wicked fast. It also means you can fetch or delete the Pinecone vector for a given chunk, without storing an extra ID. - I used the table name as the Pinecone namespace for convenience, so queries for chunks wouldn’t return vectors for other data. This isn’t required but helped me with organization and naming fatigue.
Tip: Use the @pinecone-database/pinecone Pinecone client for the best experience in Convex.
There are two action runtimes in Convex: our optimized runtime, and a generic node environment. When possible I prefer using the optimized runtime, so I can keep the actions in the same file as the queries and mutations, along with some performance benefits. However, our runtime doesn’t support all npm libraries. Thankfully the pinecone package doesn’t depend on any incompatible packages and just uses the fetch standard under the hood. This is also why I prefer using fetch and the OpenAI HTTP API directly above. See here for more information on runtimes.
Mark the source as “saved”
All we need to do to notify the frontend that the data has been saved is to update the source. Any queries that reference the source document will be updated with the latest data automatically.
1await ctx.runMutation(internal.sources.patch, {
2 id: source._id,
3 patch: { saved: true, totalTokens, embeddingMs },
4});
5At this point, our data is in Convex and an embedding vector is saved in Pinecone.
Extensions
Beyond saving chunks of the source, you might also consider:
- Adding an embedding of a summary of the whole source.
- Add a hierarchy of searches - where you could separately search for a category of documents and then provide that category as a metadata filter in a later query.
- Namespacing or otherwise segmenting user data so you never accidentally leak context between users.
Searching for sources
Similarly to inserting data, to do a semantic search over your documents, you can:
-
Insert the search into a table of searches. If there’s already an identical search, you could even decide to re-use those results. This is handy for iterating on large pipelines and keeping latency and costs low.
1const searchId = await ctx.db.insert("searches", { input, count }); 2 -
Kick off an action transactionally.
1await ctx.scheduler.runAfter(0, internal.searches.search, { 2 input, 3 searchId, 4 topK: count, 5}); 6 -
Create an embedding of the search. Aside: I have a hunch there’s a lot of opportunity here for ways of transforming the raw search into a better text input for the embedding.
1const { embedding } = await fetchEmbedding(input); 2 -
Use the pinecone query to find nearby vectors representing chunks.
1const { matches } = await pinecone.query({ 2 queryRequest: { 3 namespace: "chunks", 4 topK, 5 vector: embedding, 6 }, 7}); 8 -
Update the search results by running a mutation.
1await ctx.runMutation(internal.searches.patch, { 2 id: searchId, 3 patch: { 4 relatedChunks, 5 }, 6 }); 7 -
Optional: store the search embedding in Pinecone if you want to be able to search semantically over searches themselves!
Note: you could just do steps 2-4 directly in an action if you don’t care about keeping a cache and storing the search vector.
Returning results to the client
The client can subscribe to the search document’s ID:
1const results = useQuery(api.searches.semanticSearch, { searchId });
2The query looks for the search and returns the related chunks along with their source’s name:
1export const semanticSearch = query({
2 args: { searchId: v.id("searches") },
3 handler: async (ctx, { searchId }) => {
4 const search = await ctx.db.get("searches", searchId);
5 if (!search) throw new Error("Unknown search " + searchId);
6 if (!search.relatedChunks) return null;
7 return pruneNull(
8 await Promise.all(
9 search.relatedChunks.map(async ({ id, score }) => {
10 const chunk = await ctx.db.get("chunks", id);
11 if (!chunk) return null;
12 const source = await ctx.db.get("sources", chunk.sourceId);
13 return { ...chunk, score, sourceName: source!.name };
14 })
15 )
16 );
17 },
18});
19This is parallelized by using Promise.all and calls to db.get are cached.
Summary
In this post, we looked at using Pinecone and Embeddings in Convex. One natural extension of this is to then use the sources as part of a GPT prompt template, but I’ll leave that for a future post. Let us know in discord what you think and what you’d like to see next!
Footnotes
-
At the Pinecone hackathon, there was a discussion of issues of semantic rankings sometimes behaving oddly - in my case, when I searched over a corpus of famous poems for “what is the meaning of life?” one of the top hits was a “hello world” dummy text I had added. One participant mentioned that a useful filter—after listing a plethora of sophisticated ranking strategies—was to just exclude text less than 200 characters. Intuitively this makes some sense - the longer something is, as short phrases probably have higher semantic variance. ↩
Convex is the reactive backend platform that keeps up with you and your agents. Database, functions, workflow, sync, search, file storage, and more. All TypeScript, zero glue.