
GPT Streaming With Persistent Reactivity
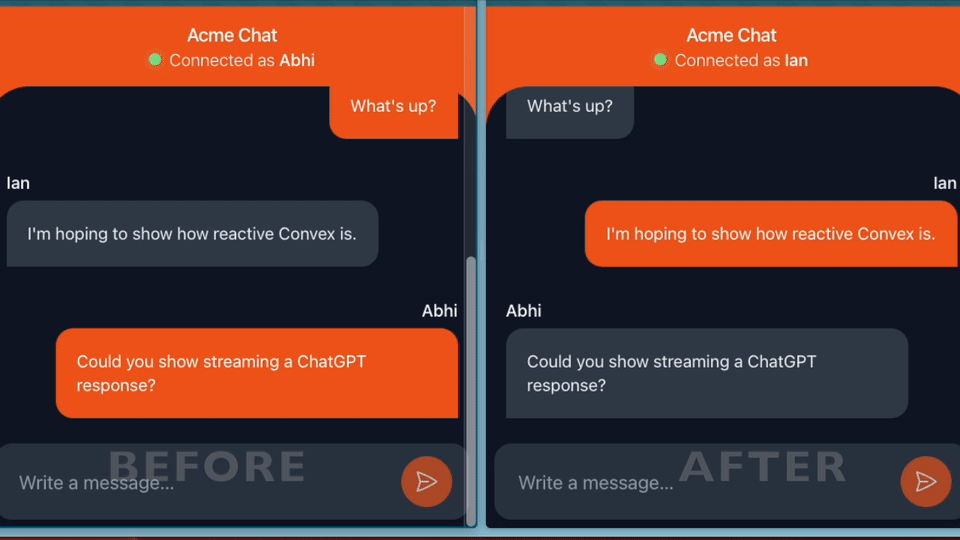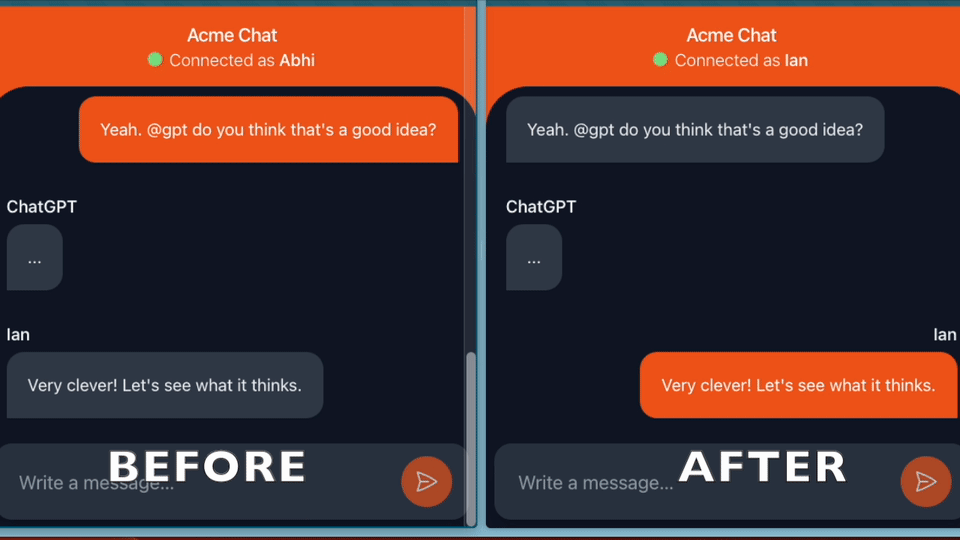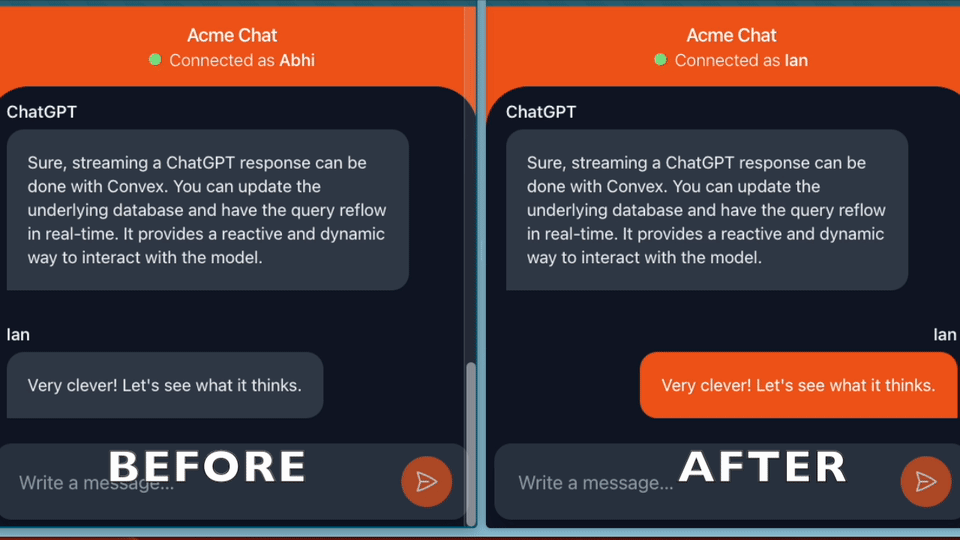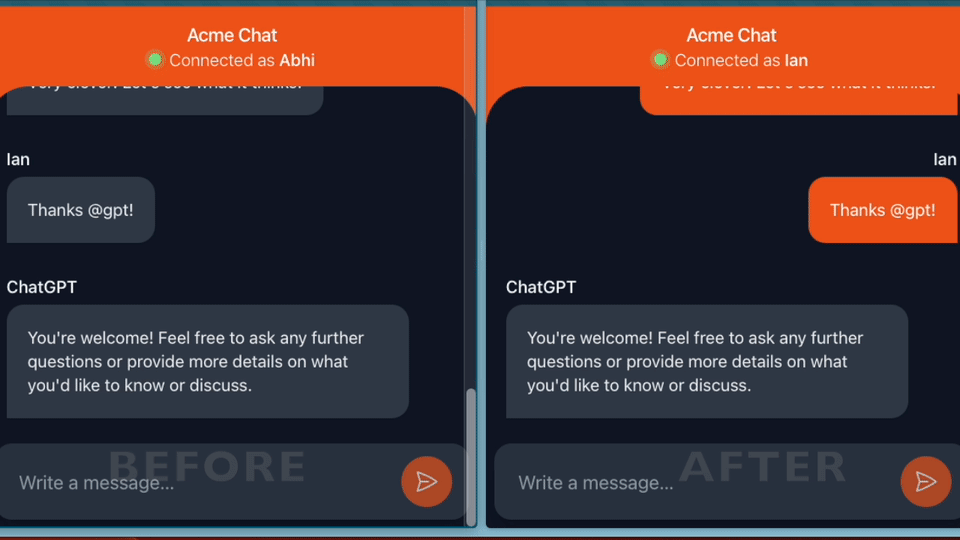
Building ChatGPT-powered experiences feel snappier when the responses show up incrementally. Instead of waiting for the full response before showing the user anything, streaming the text in allows them to start reading immediately.
OpenAI exposes a streaming API for chat completions. But how do you manage a GPT streaming request when you have a server between the client and OpenAI? You might be tempted to use HTTP streaming end to end - both from the client to the server and the server to OpenAI. However, there’s another way that comes with some big benefits. Spoiler: it’s possible to use a database as a layer of reactivity that separates client request lifecycles from server requests. Don’t worry if that doesn’t make sense yet - we’ll take it one step at a time.
This post will look at working with streams with OpenAI’s Node SDK. Beyond just getting streaming for a single user, we’ll look at an approach that enables:
- Persisting the response even if the user closes their browser.
- Multiplayer chat, including streaming multiple ChatGPT messages at once.
- Resuming a stream when a user refreshes their browser mid-stream.
- Streaming to multiple users at once.
- Implement custom stream granularity, such as only updating on full words or sentences, rather than on each token.
To do this, we’ll use Convex to store the messages and make the request to OpenAI. This code is on GitHub for you to clone and play with.
 Diagram of browsers talking to Convex, which talks to OpenAI
Diagram of browsers talking to Convex, which talks to OpenAI
Persisting messages
Let’s say we have a chat app, like the one pictured in the gif above. We want to store the messages from each user, as well as messages populated by responses from OpenAI. First let’s look at how data is stored (2), assuming a client sends a message (1).
When a user sends a message, we immediately commit it to the database, so they’re correctly ordered by creation time. This code is executed on the server:
1export const send = mutation({
2 args: { body: v.string(), author: v.string() },
3 handler: async (ctx, { body, author }) => {
4 // Save our message to the DB.
5 await ctx.db.insert("messages", { body, author });
6
7 if (body.indexOf("@gpt") !== -1) {
8 // ...see below
9 }
10 }
11});
12This mutation saves the message to the database. When the user wants a response from the GPT model (by adding “@gpt” to the message), we will:
- Store a placeholder message to update later.
- Make a streaming request to OpenAI in an asynchronous background function.
- Progressively update the message as the response streams in.
By running the streaming request asynchronously (versus blocking in a user request), we can interact with ChatGPT and save the data to the database even if the client has closed their browser. It also allows us to run many requests in parallel, from the same or multiple users.
We also run it asynchronously because, in Convex, mutations are pure transactions and as such can’t do non-deterministic things like making API requests. In order to talk to third-party services, we can use an action. Actions are non-transactional serverless functions that can talk to third-party services. We trigger the background job to call ChatGPT and update the message body by scheduling the action like so:
1// ...when the user wants to send a message to OpenAI's GPT model
2const messages = // fetch recent messages to send as context
3// Insert a message with a placeholder body.
4const messageId = await ctx.db.insert("messages", {
5 author: "ChatGPT",
6 body: "...",
7});
8// Schedule an action that calls ChatGPT and updates the message.
9await ctx.scheduler.runAfter(0, internal.openai.chat, { messages, messageId });
10We schedule it for zero milliseconds later, similar to doing setTimeout(fn, 0) in JavaScript. The message writing and action scheduling happens transactionally in a mutation, so we will only run the action if the messages are successfully committed to the database.
When the action wants to update the body of a message as the streaming results come in, it can invoke an update mutation with the messageId from above:
1export const update = internalMutation({
2 args: { messageId: v.id("messages"), body: v.string() },
3 handler: async (ctx, { messageId, body }) => {
4 await ctx.db.patch(messageId, { body });
5 },
6});
7Note: An internalMutation is just a mutation that isn’t exposed as part of the public API. Next we’ll look at the code that calls this update function.
Convex has end-to-end reactivity, so when we update the messages in the database, the UI automatically updates. See below what it looks like to reactively query data.
Streaming with the OpenAI node SDK
Streaming is currently available in the beta version of OpenAI’s node SDK. To install it:
1npm install openai
2The internal.openai.chat action we referenced above will live in convex/openai.ts - see the full code here.
1import { OpenAI } from "openai";
2import { internalAction } from "./_generated/server";
3//...
4type ChatParams = {
5 messages: Doc<"messages">[];
6 messageId: Id<"messages">;
7};
8export const chat = internalAction({
9 handler: async (ctx, { messages, messageId }: ChatParams) => {
10 //...Create and handle a stream request
11Creating a stream request
1// inside the chat function in convex/openai.ts
2const apiKey = process.env.OPENAI_API_KEY!;
3const openai = new OpenAI({ apiKey });
4
5const stream = await openai.chat.completions.create({
6 model: "gpt-3.5-turbo", // "gpt-4" also works, but is so slow!
7 stream: true,
8 messages: [
9 {
10 role: "system",
11 content: "You are a terse bot in a group chat responding to q's.",
12 },
13 ...messages.map(({ body, author }) => ({
14 role:
15 author === "ChatGPT" ? ("assistant" as const) : ("user" as const),
16 content: body,
17 })),
18 ],
19});
20//...handling the stream
21Note passing stream: true. This changes the return format, which unfortunately does not currently provide token usage as the non-streaming version does. I hope this is fixed in a future release, as keeping track of token usage is useful to know how different users or features are affecting your costs.
Handling the stream
The API exposed by the openai SDK makes handling the stream very easy. We use an async iterator to handle each chunk, appending it to the body and updating the message body with everything we’ve received so far:
1let body = "";
2for await (const part of stream) {
3 if (part.choices[0].delta?.content) {
4 body += part.choices[0].delta.content;
5 await ctx.runMutation(internal.messages.update, {
6 messageId,
7 body,
8 });
9 }
10}
11Note that here we’re updating the message every time the body updates, but we could implement custom granularity by deciding when to call runMutation, such as on word breaks or at the end of full sentences.
This action allows us to stream messages from OpenAI to our server function and into the database. But how does this translate to clients updating in real time? Next, let’s see how the client reactively updates as messages are created and updated.
Client “streaming” via subscriptions
After the previous sections, you might be surprised how little is required to get the client to show live updating messages. I put streaming in quotes since we aren’t using HTTP streaming here - instead, we’re just using the reactivity provided out-of-the-box by Convex.
On the client, we use the useQuery hook, which calls the api.messages.list server function in the messages module, which we’ll see in a second. This hook will give us an updated list of messages every time a message is added or modified. This is a special property of a Convex query: it tracks the database requests, and when any of the data is changed it:
- Invalidates the query cache (which is managed transparently by Convex).
- Recomputes the result.
- Pushes the new data over a WebSocket to all subscribed clients.
1export default function App() {
2 const messages = useQuery(api.messages.list);
3 ...
4 return (
5 ...
6 {messages?.map((message) => (
7 <article key={message._id}>
8 <div>{message.author}</div>
9 <p>{message.body}</p>
10 </article>
11 ))}
12Because this query is decoupled from the HTTP streaming response from OpenAI, multiple browsers can be subscribed to updates as messages change. And if a user refreshes or restarts their browser, it will just pick up the latest results of the query.
On the server, this is the query that grabs the most recent 100 messages:
1export const list = query({
2 handler: async (ctx): Promise<Doc<"messages">[]> => {
3 // Grab the most recent messages.
4 const messages = await ctx.db.query("messages").order("desc").take(100);
5 // Reverse the list so that it's in chronological order.
6 // Alternatively, return it reversed and flip the order via flex-direction.
7 return messages.reverse();
8 },
9});
10Convex is doing some magic under the hood. If any message is inserted or updated into the database that would match this query - for instance if a new message is added or one of the first 100 messages is edited - then it will automatically re-execute this query (if there are any clients subscribed to it via useQuery). If the results differ, it will push the new results over a WebSocket to the clients, which will trigger an update to the components using useQuery for that query.
To give you a sense of performance, list takes ~17ms and update takes ~7ms for me on the server, so the total latency between a new token coming from OpenAI and a new set of messages being sent to the client is very fast. The gifs in this article are real recordings, not sped up.
 GPT response streaming in quickly
GPT response streaming in quickly
Summary
We looked at how to stream ChatGPT responses into Convex, allowing clients to watch the responses, without the flakiness of browser-based HTTP streaming requests. The full code is available here. Let us know in Discord what you think!
Extra Credit 🤓
Beyond what’s covered here, it would be easy to extend this demo to:
- Store whether a message has finished streaming by storing a boolean on the message updated at the end of the stream.
- Add error handling, to mark a message as failed if the stream fails. See this post for an example of updating a message in the case of failure.
- Schedule a function to serve as a watchdog, that marks a message as timed out if it hasn’t finished within a certain timeframe, just in case the action failed. See this post for more details, as well as other patterns for background jobs.
- Organize the messages by thread or user, using indexes.
Convex is the reactive backend platform that keeps up with you and your agents. Database, functions, workflow, sync, search, file storage, and more. All TypeScript, zero glue.