
Midpoints: A Word Game Powered by AI Embeddings and Convex Components
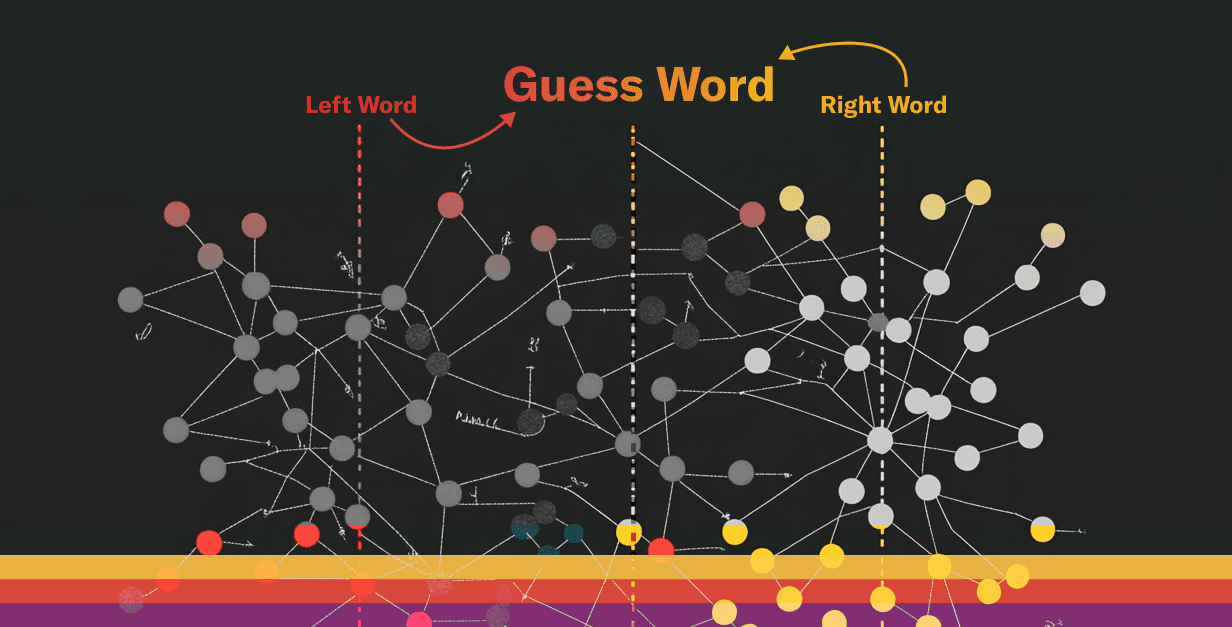
Recently, Ian shared an idea with me that he had for a new word game. I told him, "I love Wordle!" And then he proceeded to explain the most brilliant and fun-sounding game I'd ever heard of.
Ian's game concept relies on a little bit of high school algebra applied to vector embeddings of words. I always thought "vector embedding" sounded so fancy, but the idea is simple: words are translated to an array of numbers, and words that are semantically or contextually similar will be "closer" to each other in the number space. That's it.
Take the world's simplest example: after being embedded by the same Magic Algorithm (e.g. OpenAI Embeddings or Anthropic Embeddings), "dog" and "cat" might have a difference* of 2. But "dog" and "archaeology" might have a difference of 100. See? Easy.
*The actual embedding are arrays of numbers, so that's why we need to use linear algebra to calculate the difference - or more correctly, distance.
But don't worry about a thing. We'll dive deeper into the math of vector embeddings below.
Midpoints: Words, Math, and a little Magic
Ever wondered what word sits perfectly between "sporty" and "practical"? Or perhaps "sweet" and "crunchy"? Midpoints gives you 10 chances to find the best match and scores you accordingly!
In Midpoints, players face a deceptively simple task: given two words, guess the words that best bridge the gap between them. But unlike traditional word association games, Midpoints uses AI embeddings to determine the "best" answers.
You can think of it as a combination of the game "Scattergories" and a crossword puzzle.
The core gameplay is straightforward: you're presented with two words and have 10 chances to guess words that lie conceptually between them, scoring points based on how "perfect" your answer is according to the AI's understanding of language.
How to Play
When you start a round of Midpoints, you're presented with two words and a simple challenge: guess the words that best connect them. Each round contains 10 hidden target words, carefully selected from a specific category (like cars, foods, or animals), and you get 10 guesses to find them.
For example, in a round about cars, you might see:
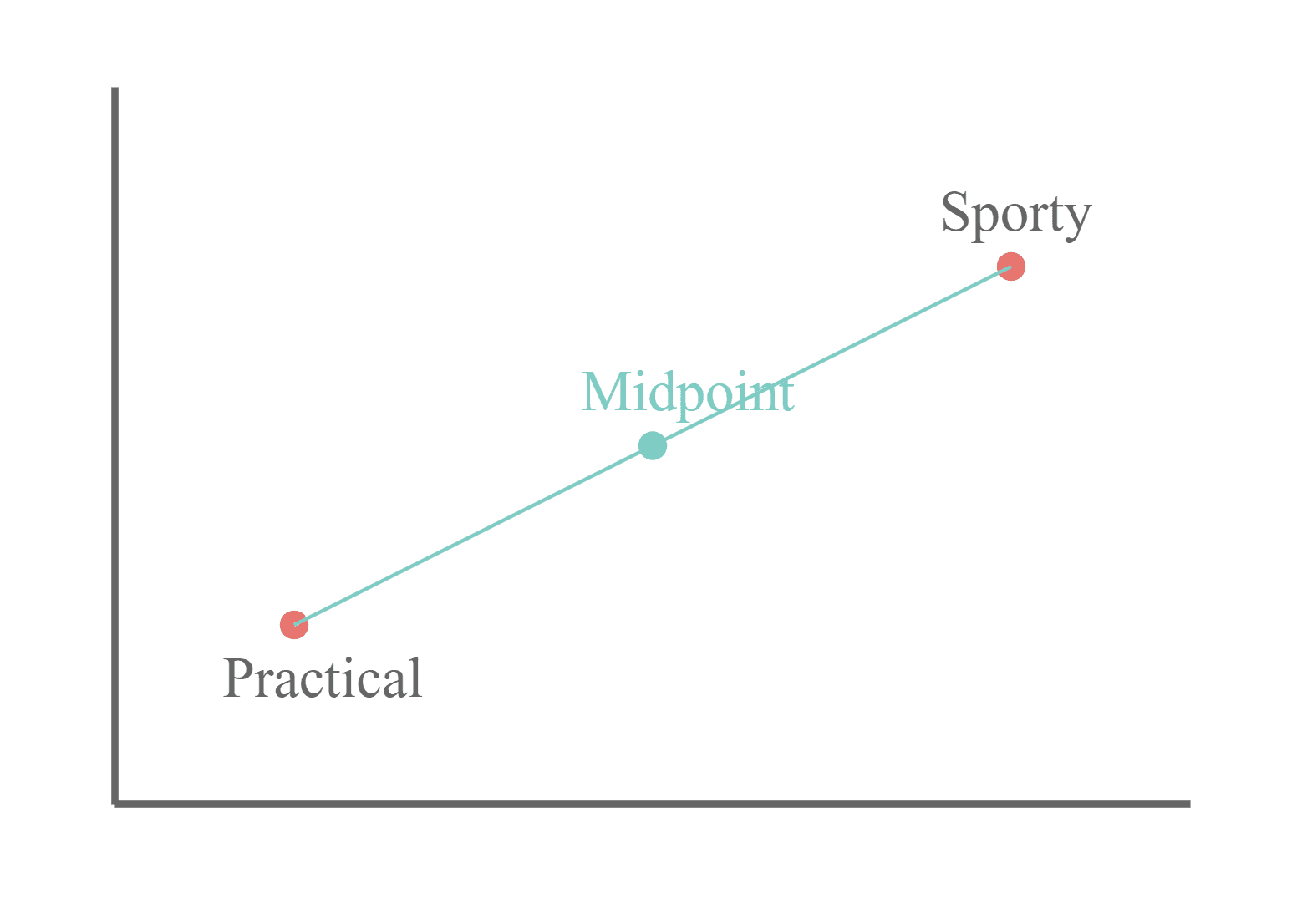
- Word 1: sporty
- Word 2: practical
Your task is to think of cars that balance these qualities. A Volkswagen Golf GTI might be a perfect answer, combining sporty performance with practical functionality. A Ferrari would be too sporty, while a minivan would be too practical – the game rewards finding the sweet spot between the two concepts.
Scoring System
The scoring is designed to reward precision while keeping the game engaging:
- Finding the #1 ranked word: 10 points
- Finding the #2 ranked word: 9 points
- Finding the #3 ranked word: 8 points And so on...

Each guess gives you immediate feedback with your score and how close you were to the perfect answer. The game keeps track of your overall performance, displaying your rank and total score in the top right corner.
Example Round Walkthrough
Let's walk through a real round:
- The round begins: sporty + practical
- First guess: "Honda Civic" - 7 points! A good start, the Civic balances both qualities well
- Second guess: "Golf GTI" - 10 points! Perfect match, exactly between sporty and practical
- Third guess: "BMW M3" - 5 points, a bit too far on the sporty side
- And so on until you've used all 10 guesses or found all target words
A leaderboard shows how your scores compare to other players, adding a competitive element to the game mechanics.
The Technology Behind the Game

Vector Embeddings: Teaching AI to Understand Word Relationships
At the heart of Midpoints is a sophisticated system for understanding how words relate to each other. As mentioned, we use vector embeddings – a way of representing words as points in a high-dimensional space. Imagine a giant map where every word has its own unique coordinate. Words with similar meanings cluster together, while unrelated words end up far apart:
 In this mathematical space:
In this mathematical space:
- "Car" might be closer to "vehicle" than to "banana"
- "Sporty" creates a direction toward performance and excitement
- "Practical" points toward utility and functionality\
Scoring Algorithms: Finding the Perfect Middle Ground
Time to dust off that old algebra textbook you've been meaning to dive back into! Midpoints uses these algorithms to determine how good a guess is:
1// convex/linearAlgebra.ts
2
3// Calculate the midpoint between two embedding vectors
4export function calculateMidpoint(a: number[], b: number[]) {
5 return normalize(a.map((n, i) => n + b[i]));
6}
7
8// Normalize a vector to unit length
9export function normalize(vector: number[]) {
10 const magnitude = vectorLength(vector);
11 return vector.map((n) => n / magnitude);
12}
13
14// Calculate vector magnitude/length
15export function vectorLength(vector: number[]) {
16 return Math.sqrt(vector.reduce((sum, n) => sum + n * n, 0));
17}
18
19// Calculate dot product between two vectors
20export function dotProduct(a: number[], b: number[]) {
21 return a.reduce((sum, n, i) => sum + n * b[i], 0);
22}
23
24// Calculate vector from point a to point b
25export function deltaVector(a: number[], b: number[]) {
26 return a.map((n, i) => b[i] - n);
27}
28Algorithm 1: Midpoint Calculation (calculateMidpoint)
We literally find the mathematical midpoint between two word vectors. If our words are "sporty" and "practical", we calculate a point exactly halfway between them in our high-dimensional space.
Algorithm 2: Reciprocal Rank Fusion (RRF)
This algorithm combines multiple ranking signals to create a more nuanced scoring system. It also has the coolest name of any algorithm in history. It's particularly good at handling cases where a word might be a great match for one input word but only okay for the other.
The algorithm for reciprocal rank fusion looks like this:
1// convex/namespace.ts
2function reciprocalRankFusion(aIndex: number, bIndex: number) {
3 const k = 10;
4 const a = aIndex + k;
5 const b = bIndex + k;
6 return (a + b) / (a * b);
7}
8Here's how this algorithm works:
-
Takes two rank positions (
aIndexandbIndex) as input -
Uses a constant k=10 to stabilize the calculation
-
For each rank position:
- Adds k to prevent division by very small numbers
- Combines the ranks using the formula:
(a + b) / (a * b)
For example:
- If an item ranks 1st in both lists:
(1+10 + 1+10) / ((1+10) * (1+10)) = 20/121 ≈ 0.165 - If an item ranks 1st and 50th:
(1+10 + 50+10) / ((1+10) * (50+10)) = 71/660 ≈ 0.108 - If an item ranks 50th in both:
(50+10 + 50+10) / ((50+10) * (50+10)) = 120/3600 ≈ 0.033
The resulting RRF score:
- Is higher when items rank well in both lists
- Decreases as ranks get worse
- Handles ties and missing ranks gracefully
- Gives more weight to higher ranks (closer to 1)
Algorithm 3: Vector Dot Products (dotProduct)
We use dot products to measure how similar two words are. This gives us a precise numerical score for how well your guess matches the target words.
Each scoring strategy has its strengths:
- RRF is great for finding balanced matches
- Midpoint calculation rewards precise matches to the mathematical center
- Dot products help identify subtle relationships between words
Convex Components: Building a Scalable Game
When Midpoints inevitably goes viral because somebody in the community adds social features, we've made sure it'll scale without a hitch.
Midpoints is built on Convex, a backend platform that provides powerful building blocks called Components. Here's how we use them:
1. Leaderboards (aggregate)
- Global leaderboard tracking all-time best scores
- Round-specific leaderboards for competitive play
- Efficient aggregation of scores across all players
2. Rate Limiting (ratelimiter)
Use the Rate Limiter component
- Prevents spam and abuse
- Ensures fair play by limiting:
- Number of guesses per second
- Round creation frequency
- Word list uploads, for people using it to build their own games
3. Action Caching (actionCache)
Use the Action Cache component
- Caches expensive embedding calculations
- Speeds up repeated guesses
- Reduces API costs for vector operations
4. Background Jobs (crons)
- Rotating the active game daily
- The upcoming games (pairs of words) are structured as a linked list
- Each day it transactionally sets the next game as active and the current set as inactive
- The clients are subscribed to the latest game, and will show a button to join the new game once the current game is no longer active
5. Sharded Counter (shardedCounter)
Use the Shared Counter component
- Scales to handle many concurrent players
- Accurately tracks global statistics
- Manages high-throughput changes to power a total counter on number of guesses
6. Database Evolution (migrations)
- Safely updates game data structure
- Enables new features without disruption
- Used to backfill the aggregate components with current data
These components work together to create a responsive, fair, and scalable game experience. The rate limiter keeps the game fair, caching makes it fast, and aggregation helps us track who's winning – all without writing complex infrastructure code from scratch.
Round Creation Workflow
Game creators supply:
- A category-specific word list (e.g., "cars", "foods", "movies")
- Two anchor words that form an interesting conceptual spectrum
- A scoring strategy (RRF, midpoint, or dot product)
Example pairings that work well:
- Cars: "luxury" + "efficient"
- Movies: "heartwarming" + "intense"
- Foods: "healthy" + "indulgent"
Best practices:
- Choose words with clear opposing qualities
- Ensure word list contains items spanning the spectrum
- Test rounds with small groups before public release
- Avoid highly similar words as anchors
Technical Implementation Highlights
Rate Limiting Configuration
- Token bucket algorithm
- Sharded for scalability
- Periods configured per-metric
1// convex/auth.ts
2const rate = new RateLimiter(components.ratelimiter, {
3 createNamespace: { kind: "token bucket", period: 10 * SECOND, rate: 1 },
4 addText: {
5 kind: "token bucket",
6 period: 24 * HOUR,
7 rate: 10_000,
8 shards: 10,
9 },
10 basicSearch: { kind: "token bucket", period: SECOND, rate: 1, capacity: 5 },
11});
12Leaderboard System
The leaderboard is one of the most interesting systems in the game. Let's dive into some of the details.
The system demonstrates several best practices:
- Separation of concerns (round vs global rankings)
- Efficient sorting with composite keys
- Graceful handling of anonymous users
- Automatic updates via triggers
- Null-safe value handling
This implementation provides a scalable and maintainable way to track user performance both within individual rounds and across the entire game system.
Dual Leaderboard System
roundLeaderboard: Tracks scores within individual rounds
globalLeaderboard: Maintains overall user rankings across the entire game
Smart Sorting with Composite Keys
- Round leaderboard uses a triple key:
[roundId, score, -submittedAt] - This ensures proper ordering by round, score, and submission time (favoring recent submissions when the score is tied!)
- Global leaderboard uses
[score, -_creationTime]to rank by score and account age (favoring new users!)
Anonymous User Handling
- Anonymous users' scores are ignored in the global leaderboard unless there aren't enough "real" users
- When anonymous accounts log in, the real accounts inherit the anonymous user's scores for games they hadn't completed, and the anonymous user's data is removed.
- This creates a natural hierarchy: real users > anonymous users > captured accounts
Trigger-based Updates
1// convex/functions.ts
2triggers.register("guesses", roundLeaderboard.idempotentTrigger());
3triggers.register("users", globalLeaderboard.idempotentTrigger());
4- Leaderboards automatically update when relevant tables change
- Uses idempotent triggers while backfilling data.
Reduce Processing by Using an Action Cache
- Efficient caching of embedding operations
- Function + args-based caching
- Transparent cache layer
1// convex/embed.ts
2const embedCache = new ActionCache(components.actionCache, {
3 action: internal.embed.generateEmbedding,
4});
5
6export async function embedWithCache(ctx: ActionCtx, text: string) {
7 return embedCache.fetch(ctx, { model: CONFIG.embeddingModel, input: text });
8}
9Smart Vector Search Implementation
- Namespace-based filtering
- Score mapping for efficient lookups
- Smart limit handling with buffer for edge cases
1// convex/namespace.ts
2const midpointMatchScoresById = new Map(
3 await ctx.vectorSearch("embeddings", "embedding", {
4 vector: midpointEmbedding,
5 limit: 102, // extra two to account for the left and right embeddings
6 filter: (q) => q.eq("namespaceId", ctx.namespace._id),
7 }).then((results) => results.map((r) => [r._id, r._score])),
8);
9Processing in Chunks & Batches
- Efficient batch processing
- Chunking for large datasets
- Promise handling for async operations
1// convex/llm.ts
2export async function asyncMapChunked<In, Out>(
3 items: In[],
4 fn: (batch: In[], index: number) => Out[] | Promise<Out[]>,
5 chunkSize?: number,
6): Promise<Out[]> {
7 return Promise.all(chunk(items, chunkSize).map(fn)).then((c) => c.flat());
8}
9Robust Error Handling with Result Types
- Type-safe error handling
- Discriminated unions for results
- Consistent error pattern across the app
1// convex/functions.ts
2export type Result<T> =
3 | { ok: true; value: T; error: undefined }
4 | { ok: false; value: undefined; error: string };
5
6export function error(message: string) {
7 return { ok: false as const, value: undefined, error: message };
8}
9
10export function ok<T>(value: T) {
11 return { ok: true as const, value, error: undefined };
12}
13
14export function resultValidator<T extends Validator<any, "required", any>>(
15 value: T,
16) {
17 return v.union(
18 v.object({ ok: v.literal(true), value, error: v.optional(v.null()) }),
19 v.object({
20 ok: v.literal(false),
21 error: v.string(),
22 value: v.optional(v.null()),
23 }),
24 );
25}
26What's Next for Midpoints?
Midpoints is open source and ready for community contributions. We welcome improvements in several areas:
Potential Enhancements
- Additional scoring algorithms
- Improve category creation UI
- Mobile-friendly ergonomics
- Social sharing features
Get Involved The codebase is available on GitHub at github.com/ianmacartney/mid-embeddings. We use Convex for the backend, React for the frontend, and standard TypeScript throughout.
Try It Now Play Midpoints here or fork the repo to create your own word-guessing game using our vector embedding infrastructure.
As always, happy coding!
Convex is the reactive backend platform that keeps up with you and your agents. Database, functions, workflow, sync, search, file storage, and more. All TypeScript, zero glue.